大数据专题
Tensorflow简单教程
Google将其机器学习框架Tensorflow开源后引起了世界风暴,本文主要阐述如何在日常数据科学中使用该框架。
为什么使用Tensorflow?
作为一个数据科学研究者,已经有很多工具如R语言、Scikit等学习工具,为什么还要使用Tensorflow呢?
1. TensorFlow的深度学习部分能够在一个模型中堆积了许多不同的模型和转换,你能够在一个模型中方便地处理文本 图片和规则分类以及连续变量,同时实现多目标和多损失工作;
2. TensorFlow的管道部分能够将数据处理和机器学习放在一个框架中,TensorFlow指引了方向。
Titanic 数据集的简单模型
开始一个简单的案例,从Kaggle获得Titanic 数据集,首先,肯定你已经安装了 TensorFlow 和 Scikit Learn,包括一些支持库包Scikit Flow ,它可以简化TensorFlow的许多工作。
pip install numpy scipy sklearn pandas
# For Ubuntu:
pip install https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.5.0-cp27-none-linux_x86_64.whl
# For Mac:
pip install https://storage.googleapis.com/tensorflow/mac/tensorflow-0.5.0-py2-none-any.whl
pip install git+git://github.com/google/skflow.git
你可以从http://github.com/ilblackdragon/tf_examples得到数据集和代码:
git clone https://github.com/ilblackdragon/tf_examples.git
使用iPython或 iPython notebook可以快速浏览一下数据:
>>> import pandas
>>> data = pandas.read_csv('data/train.csv')
>>> data.shape
(891, 12)
>>> data.columns
Index([u'PassengerId', u'Survived', u'Pclass', u'Name', u'Sex', u'Age',
u'SibSp', u'Parch', u'Ticket', u'Fare', u'Cabin', u'Embarked'],
dtype='object')
>>> data[:1]
PassengerId Survived Pclass Name Sex Age SibSp
0 1 0 3 Braund, Mr. Owen Harris male 22 1
Parch Ticket Fare Cabin Embarked
0 0 A/5 21171 7.25 NaN S
让我们基于Scikit 学习的浮点变量预测Survived 类别:
>>> y, X = train['Survived'], train[['Age', 'SibSp', 'Fare']].fillna(0)
>>> X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
>>> lr = LogisticRegression()
>>> lr.fit(X_train, y_train)
>>> print accuracy_score(lr.predict(X_test), y_test)
0.664804469274
我们将数据集分离进入特征和目标,用数据零填入N/A中,建立一个逻辑回归,基于训练数据的预测会给我们一定的精确度,现在使用Scikit Flow:
>>> import skflow
>>> import random
>>> random.seed(42) # to sample data the same way
>>> classifier = skflow.TensorFlowLinearClassifier(n_classes=2, batch_size=128, steps=500, learning_rate=0.05)
>>> classifier.fit(X_train, y_train)
>>> print accuracy_score(classifier.predict(X_test), y_test)
0.68156424581
恭喜你,你已经建立了第一个TensorFlow 模型。
Scikit Flow
Scikit Flow是一个将TensorFlow包装其中提供多新与Scikit Learn API类似的API。TensorFlow是一个构建和执行图,这是一个强大的概念,但是开始时比较复杂一些。所以,需要简化包装一下。
揭开 Scikit Flow神秘面纱,我们发现有三个部分:
- TensorFlowTrainer — 各种优化类,可以进行灰度修剪等优化。
- logistic_regression逻辑回归 — 创建一个逻辑回归模型的图
- linear_regression线性回归 — 创建线性回归模型的图。
- DataFeeder — 取样训练数据的最小批次放入模型。
- TensorFlowLinearClassifier — 一个使用LogisticRegression实现Scikit Learn接口的类,它创建一个模型和一个训练者,使用给定数据集调用fit()运行训练者,调用predict()在评估模型中运行模型。
- TensorFlowLinearRegressor — 类似于TensorFlowClassifier, 但是使用 LinearRegression作为一个模型
模拟数据
我们使用TensorFlow分析三种模拟数据:线性可数据,月亮和土星数据三种。第一种使用线性分类器很容易实现,后两种需要非线性模型如多层神经网络multi-layer neural network。
线性数据如下,可以用从左上到右下一条直线区分这两族数据:
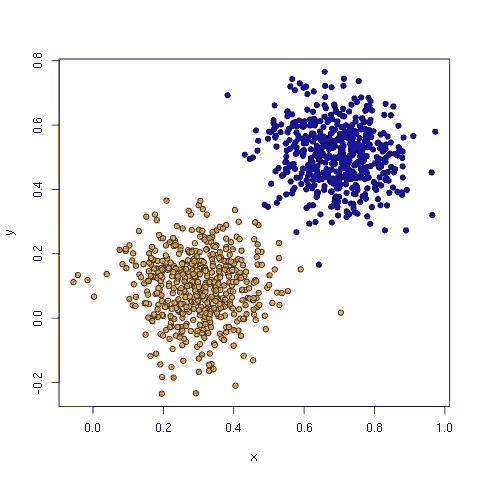
线性分类器如 感知器, 逻辑回归, 线性判别分析, 支持向量机(SVM)都能很好实现这种线性分类。
月亮数据如下,如同两个月亮环抱,这就很难找出一条线可以将这两种颜色的数据进行分离。
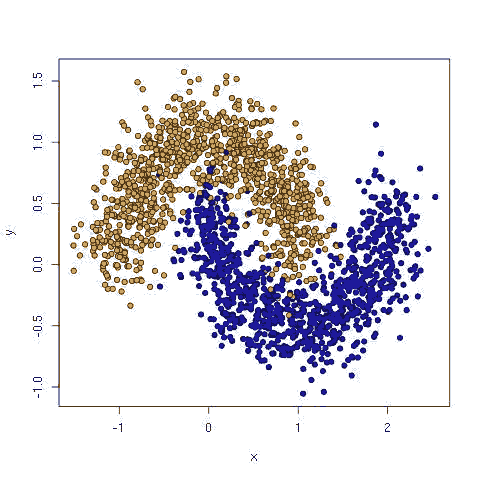
而土星数据则是一族数据环绕另外一组数据:
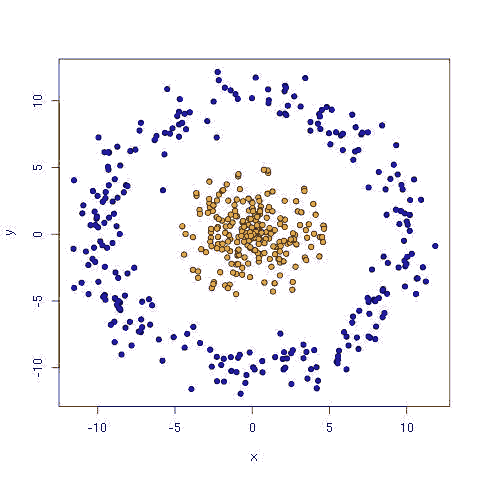
Jason Baldridge在其github上根据Tensorflow案例mnist.py编写了Softmax回归: softmax.py.,使用它进行线性分析:
一代训练结果非常精确达到99% ,二代训练能够达到100%:
更多请参考:
Simple end-to-end TensorFlow examples