高性能聊天系统
作者:板桥banq
1.2.4 多线程
前面介绍了3种Java事件处理模式。在一个微观系统中,事件处理机制的实现主要是依靠Java线程来实现,一般监视者是一个线程,专门用于监测源目标的变化。
在 Java 程序中使用多线程要比在 C 或 C++ 中容易得多,因为 Java 编程语言提供了语言级的支持,但是这并非意味着在使用时可以避开线程的一些基本问题。在以后章节中介绍的JSP/Servlet容器,实际是一个线程池容器,JSP在运行时将编译成Servlet,而Servlet是一种线程类,J2EE通过Servlet概念的提出,确保开发者不用担心线程以及同步等问题,可以像往常一样编程。
无论是开发独立多线程的Java Application或使用Servlet,有一个概念总是需要时刻注意:对同一资源访问时需要考虑同步(Synchronization)的问题。但是,同步使用需要慎重,过多使用反而会降低性能,甚至发生死锁(DeadLock),同步只是在复杂的情况下不得已使用的一种办法。在使用同步之前有两个因素需要仔细考虑:首先确定是否一定需要同步;然后确定被访问资源是否属于原子型(atomic)的。下面从这两个方面详细讨论一下。
在一些情况下,多线程访问同一个资料是不需要同步的,如读操作,针对方法体内局部变量的写操作也不需要同步,关键是对类变量的访问操作,一旦设置了类变量,那么就需要非常小心。采取类变量有两种形式,如下:
public class Test{
private int state;
private volatile long stateLong ;
private byte[] states = null;
private String stateStrs = null;
private final Object stateObject = null;
private HashMap map = new HashMap;
private Hashtable hashtable = new Hashtable;
public void setState(int state){
this.state = this.state + state;
}
…
}
在上面的Test类中,有5个类变量,分别代表5种不同的类变量:
(1)state的类型是整型(int),整型是属于Java原始型变量(primitive)。原始变量的操作访问都是原子型(atomic)的(long和double除外),因此对于原始型变量的操作访问都是线程安全的,不需要实现同步。
(2)对long和double操作访问可以加上volatile,如上面代码第3行。多线程工作中有主内存和工作内存之分,在JVM中有一个主内存,专门负责所有线程共享数据;而每个线程都有它自己私有的工作内存,volatile变量表示保证它必须是与主内存保持一致,它实际是变量的同步。但是,由于volatile在Java语言规范中表单不够详细,不是所有的Java虚拟机都支持volatile的。
(3)第4行是一个数组state,数组是属于对象(Object),因此,对数组state的访问必须使用Synchronization实现同步。当然,String也属于对象,因此使用时需要注意,在这种情况下还是有可能避免使用Synchronization,而使用Java的对象不变性(immutability)。
不变性对象就是指自从产生那一刻起就无法再改变的对象,一个对象如果有下列2种情况就属于不变性对象,对这些不变性对象的访问就无需使用同步。
(4)String之类对象。一旦赋值给String,该String对象的长度和内容都不会改变,如果要变化需通过同样性质的类StringBuffer来实现。
(5)使用final,这样就阻止对这个类再进行继承拓展的可能,而且可以提高JVM的效率,例如Test类中第6行。
一个类的所有类属性都是通过类的构造方法来设置,没有其他set之类的方法。
类似String的trim()或toUpperCase()这样的修改后数据结果是在另外一个对象中,String的trime()等方法并不是对自己本身对象进行修改,而是将结构保存到另外一个对象中。
因此,在实际编程中,尽量操作方法体内局部变量,这样就不需要考虑同步问题。如果必须做成类变量,那么,想办法使自己的类变量变成一个不变性对象,还是可以避免同步(Synchronization)的使用。
使用HashMap或Hashtable保存对象引用时也需要注意同步的问题。在向HashMap中加入新对象引用时,要使用同步方法;而Hashtable已经实现了内部同步,则在同样操作时不需要加同步,同样,List和Vector也是这样的关系。
在必须使用同步的情况下,要注意避免发生死锁。死锁的情况是:A线程试图访问一个资源对象,但这个对象正在被B线程访问,处于锁定状态,暂时无法使用,如果B一直不释放锁定,那么A线程就发生死锁现象。
避免死锁没有完全之策,只有根据自己的应用小心设计,有几种办法对避免死锁有所帮助。
(1)通过制造缩小同步范围,尽可能地实现代码块同步。
(2)如果使用wait,可以指定毫秒数,让它在一定时间后结束等待,避免死锁。因为wait是被notify()或notifyAll()唤醒的,要保证这两个方法确实能够唤醒wait。
(3)使用性能调试工具可以检测死锁现象发生,如Borland的Optimizeit Profiler。
程序系统中一定要避免死锁,线程死锁后会一直占据CPU,这称为Block,这时的CPU使用率100%,严重阻碍了其他线程的运行,降低了系统的性能,容易发生Block还有等待I/O的响应,现在有了非堵塞I/O的帮助,这个问题基本可以避免。
另外一个容易阻塞住CPU的使用就是死循环,使用while(true)这样的语句让线程进入死循环运行,这样的线程会一直占据CPU,解决办法很灵活,如下:
(1)使用while (!Thread.interrupted())代替while(true)语句,这样使得线程在执行错误时能够放弃对CPU独霸。
(2)在循环体内尽量加上sleep(1000L)这样的语句,这样让CPU有空闲处理其他线程。如果必须做到实时,那么考虑是否有其他应用上的前提限制,使用这些前提条件暂时阻止循环反复执行。
以本系统为例,在客户端需要将用户输入的聊天信息发往服务器,那么建立一个线程一直实现发送功能,由于客户端监视用户输入也有一个监视线程在运行,例如使用Swing实现时,ActionListener的具体实现将监视用户输入。
图1-5 队列Queue模式 |
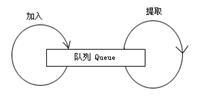
这样有两个线程各司其职。一个线程负责监视输入,另外一个线程负责将输入发送出去。那么在这两个线程之间如何通信?最经常使用的办法是使用队列(Queue)模式。Queue模式是处理消息通信的基本办法,如图1-5所示。
在图1-5中,一个线程负责不断向Queue中加入新的对象,而另外一个线程则不断地从Queue中读取加入的对象,在Queue中,对象数据排着队等待提取。在Java中,LinkList是队列Queue的最好实现。
在本系统中应用Queue模式就有一个问题,加入动作是由用户输入决定的,一旦有用户输入,就会发生加入动作,这由Swing的ActionListener负责,那么,提取线程会在队列另外一端进入死循环不断地读取,这样才能在队列中一旦有对象事件时,能够被立即提取出来,因此必须使用while (!Thread.interrupted())实现死循环。
但是必须注意到,每次循环中的提取动作执行是有前提条件的——队列中有对象事件。如果在有对象事件时,通知提取线程,这样可以避免提取线程一直霸占CPU “傻等”,使用线程的wait()和notifyAll()可以达到这个目的。
提取线程的循环体内设置wait()进行中断等待,加入对象后,执行notifyAll(),这样提取线程将中断等待,从Queue中读取加入的对象。线程在中断等待时,将释放CPU的霸占,这样就有效率地利用了CPU,如图1-6所示。
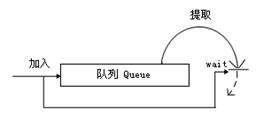
图1-6 改进后的队列Queue模式
由此可见,并不是说使用了多线程就能提高系统性能,更重要的是还要注意提高CPU使用效率,防止Block发生。
提高多线程的使用效率还必须了解下列几点:
(1)线程运行的次序并不是按照创建它们时的顺序来运行的,CPU处理线程的顺序是不确定的。如果需要确定,那么必须手工介入,使用setPriority()方法设置优先级,但是这种方法在Windows NT下有时也不一定有效果。
(2)要避免大量线程运行时发生堵塞现象,可以通过设置线程优先级来实现,但是同时又必须注意到,在大量线程被堵塞时,最高优先级的线程先运行,但是不表示低级别线程不会运行,只是运行概率较小而已。
(3)使用yield()会自动放弃CPU,有时比sleep更能提升性能。
(4)检查所有可能Block的地方,尽可能多地使用sleep或yield()以及wait();尽可能延长sleep(毫秒数)的时间;运行的线程不能超过100个;要注意到不同平台Linux或Windows以及不同JVM运行性能差别很大。
下页