JiveJdon基于DDD的仓储字段查询/筛选查询设计
需求
1.根据 帖子标题、发言者、发言日期和标签tag查询。
2.根据自定义查询后,如果是管理者和版主,提供编辑删除或批量删除的功能。
3.提供查询用户所有帖子功能。
4.根据关键字查询,每个帖子都应该有自己的关键字。
5.设计内容关键字,也就是标签tag的设计。
模型设计
我们可以将查询条件建模,取名为QueryCriterial,下面首先进行一些建模的理论准备和简单考虑。
查询模型设计是第一步,建立QueryCriterial,按照PoEAA的”Query Object”模式:http://www.martinfowler.com/eaaCatalog/queryObject.html,QueryCriterial封装的查询字段不能够是数据表名或字段名,而应该是模型对象名或字段。
在QueryCriterial中,我们封装了查询的条件,以便最后成为SQL语句的where条件,这个过程也就是解释器解释过程。
这个步骤看似简单,实则有一些问题需要反复权衡考量:
第一:需要一个翻译层面,查询条件的字段应该是对象字段,如果我们没有使用Hibernate等ORM,那么这些字段就不能直接成为SQL语句的where条件,需要经过对象字段到数据表字段的转换,这个转换过程必须和其他部分松耦合,是否使用取决于具体项目的持久层选用技术。
还有:页面查询条件有可能不是简单直接针对某个字段查询,不能直接转换到SQL语句的where条件中,而是需要一个解释翻译成SQL语句能够辨识的查询条件。
这个问题在没有ORM情况下考虑起来比较麻烦,在JiveJdon3中,由于我们已经采取模型类字段名和数据表字段名基本相同的策略。
第二:关于查询模型中的字段设计,模型中有哪些字段,根据需求,我们经常需要组合下面几个字段条件查询:
forumId; //帖子所在论坛
publishUser; //帖子发言者 用userId 或username替代
publishDateDomain; //发言范围日期 查询日期:从某年某月某日到某年某月某日
考虑到日期字段几乎是查询的最基本的条件,而且通过日期约束查询,可以减少查询范围,甚至可以将结果提取到内存中,再在内存中进行各种条件筛选,因此我们将日期字段作为查询模型QueryCriterial基本字段。
查询结果需要排序,我们设计一个ResultSort来表达排序算法:升序 还是降序。
查询模型设计类图如下:
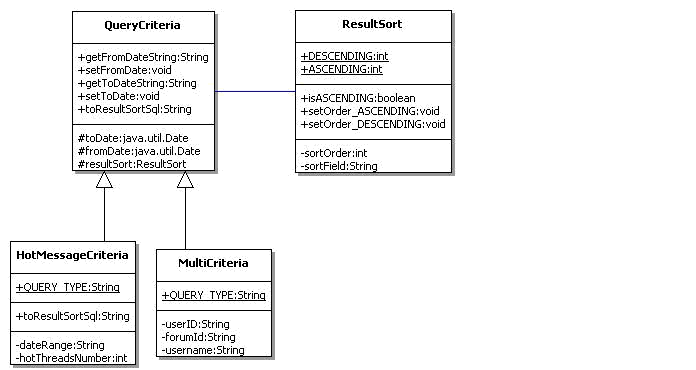
QueryCriterial有两个子类,HotMessageCriteria是查询热门帖子的查询条件,MultiCriteria是根据userId或forumId或username进行组合查询的条件,很显然,如果我们以后有新的查询条件组合,可以继承QueryCriterial实现新的子类。
有了查询条件模型,如何翻译成SQL语句,从而通过SQL实现查询呢?当然,如果我们有ORM作为持久层,就可能不需要这个SQL翻译,但是由于JiveJdon3中翻译还结合批量分页查询功能,可谓一举两得,简洁有效,还是值得在很多场合使用。
SQL解释
将QueryCriterial转为SQL语句,这是在DAO层实现的,如下代码:
public PageIterator getQueryCriteriaResult(String keyName, QueryCriteria mqc, int start, int count){
logger.debug("enter getQueryCriteriaResult" );
try {
//转换日期作为查询条件
StringBuffer where = new StringBuffer( " WHERE modifiedDate >= ? and modifiedDate <= ? ");
Collection params = new ArrayList(6);
String fromDate = ToolsUtil.dateToMillis(mqc.getFromDate().getTime());
String toDate = ToolsUtil.dateToMillis(mqc.getToDate().getTime());
params.add(fromDate);
params.add(toDate);
//如果是多字段查询
if (mqc instanceof MultiCriteria){
MultiCriteria mmqc = (MultiCriteria)mqc;
if (mmqc.getUserID() != null){//如果userID不为空,将userID作为查询条件
where.append(" and userID = ?");
params.add(mmqc.getUserID());
}
if (mmqc.getForumId() != null){//如果forumId不为空,将forumId作为查询条件
where.append(" and forumID = ? ");
params.add(new Long(mmqc.getForumId()));
}
}
//JdonFramework批量查询需要的SQL语句
String GET_ALL_ITEMS_ALLCOUNT =
"SELECT count(1) FROM jiveMessage " + where.toString();
///JdonFramework批量查询需要的SQL语句
//返回主键,主键名称可选,如messageID或threadID
//我们也可以将jiveMessage作为变量传入。
String GET_ALL_ITEMS =
"SELECT "+ keyName +" FROM jiveMessage " + where.toString() + mqc.toResultSortSql();
logger.debug("GET_ALL_ITEMS=" + GET_ALL_ITEMS);
return pageIteratorSolver.getPageIterator(GET_ALL_ITEMS_ALLCOUNT,
GET_ALL_ITEMS, params, start, count);
} catch (Exception e) {
e.printStackTrace();
return new PageIterator();
}
}
以上是QueryCriterial转为SQL语句的过程,可以做得更抽象,形成模板。
表现层实现
表现层通过ThreadQueryViewAction来推出查询页面,在这个查询页面有一个scope为session的threadQueryForm, threadQueryForm是查询模型QueryCriterial在界面的映射,threadQueryForm可以在多个Jsp中保存用户输入的查询条件,用户感受比较好,threadQueryForm主要是为查询页面服务的。
<action path="/forum/threadViewQuery"
type="com.jdon.jivejdon.presentation.action.ThreadQueryViewAction"
name="threadQueryForm" scope="session"
validate="false">
<forward name="view" path="/forum/queryView.jsp"/>
<forward name="result" path="/forum/threadQueryAction.shtml"/>
</action>
查询页面是/forum/queryView.jsp,提交到/forum/threadQueryAction.shtml,在/forum/threadQueryAction.shtml中,生成具体的QueryCriterial类型,也就是将threadQueryForm转换为QueryCriterial,然后提交Service及其后台的SQL翻译进行执行。
<action path="/forum/threadQueryAction"
type="com.jdon.jivejdon.presentation.action.ThreadQueryAction"
name="threadListForm" scope="request"
validate="false">
<forward name="success" path="/forum/queryView.jsp"/>
</action>
查询模型深度设计
之前设计建立了一个查询筛选的初步架构,该架构总体是可伸缩的,灵活的。
现在在功能上有一个实现问题,需求是想实现查询某段时间内最热门的帖子,也就是回复数最多的帖子,这个功能主要是依靠下面SQL语句实现的:
SELECT threadID, count(1) AS msgCount FROM jiveMessage WHERE modifiedDate >= ? and modifiedDate <= ? GROUP BY threadID ORDER BY msgCount DESC
这个SQL语句其实不能返回我们所要的真正结果,同时,在设计上也不符合我们要求:这样一条复杂SQL会加重数据库服务器的负载;另外,Evans DDD中的规则筛选设计也无法使用了。
很显然,我们在这里应该使用Evans DDD的规则筛选设计,在Java服务器内存中进行一次筛选,而不依靠一个复杂的SQL语句一步获得。
以上SQL语句中有两个条件:一个是时间限制;一个是按回复数大小排列,这两个条件中我们应该选择哪个条件呢?
如果选择第2个条件,会发生SQL语句将数据库中所有数据都读取的现象,大量数据在内存中再进行时间筛选,会造成性能低下;我们希望从数据库读取到内存中的数据量尽可能的少。
数据库SQL使用第一个查询条件限制可以实现我们这个目的,通过时间范围的限制,减少了所有数据都出现到内存中的可能。
实现步骤:
- 将SQL改写为:
SELECT threadID FROM jiveMessage WHERE modifiedDate >= ? and modifiedDate <= ?
这样输出的ForumThread是在某段时间范围内发生修改的主题。
- 在上述结果中进行排序,将主题回复数最多的排在前面,排序功能我们可以使用Collection的Comparator实现。如下:
class ThreadReplyComparator implements Comparator {
public int compare(Object x, Object y) {
ForumThread a = (ForumThread) x, b = (ForumThread) y;
int replya = a.getForumThreadState().getMessageCount();
int replyb = b.getForumThreadState().getMessageCount();
if (replya == replyb) {
return 0;
} else if (replya > replyb) {
return 1;
} else if (replya < replyb) {
return -1;
}
return 0;
}
}
现在的问题是:排序后的Collection是一个从大到小的排列过程,如何将这个Collection和JdonFramework的自动分页功能结合在一起呢?
JF自动分页功能实现主要围绕一个PageIterator展开的,所以只要我们在业务层Service中根据上述排列结果创建一个新的PageIterator就可以了。
3.我们开发一个管理组件QueryManager专门实现制造专门的PageIterator,另外考虑到性能,我们需要结合缓存结果,也就是排序后的ID结果。
public PageIterator getHotThreadPageKeys(QueryCriteria qc, int start,
int count) {
List resultSortedIDs = getHotThreadKeys(qc); //从缓存中获得结果
if (resultSortedIDs.size() > 0){
List pageIds = new ArrayList(resultSortedIDs.size());
for (int i = start; i < start + count; i++) { //分页查询
if (i < resultSortedIDs.size()){
pageIds.add(resultSortedIDs.get(i));
}else
break;
}
//构造一个PageIterator
return new PageIterator(resultSortedIDs.size(), pageIds.toArray());
}else
return new PageIterator();
}