JVM微调
高吞吐量调整
- UseParallelGC 和UseParNewGC等高吞吐量配合参数:
- -XX:+UseAdaptiveSizePolicy
- -XX:MaxGCPauseMillis=… (i.e. 100)
- -XX:GCTimeRatio=… (i.e. 19)
UseAdaptiveSizePolicy
- 当使用-XX:+UseParallelGC 缺省策略加载,XX:+UseAdaptiveSizePolicy。
- 主要调整下面参数,在暂停和吞吐量之间取得一个平衡:
- 一个合适的最大GC暂停值
- 一个合适的应用程序吞吐量值
- 最小化实现路径。
UseAdaptiveSizePolicy 策略路径
- 如果GC暂停时间大于目标暂停时间(-XX:MaxGCPauseMillis=nnn ),降低新生代大小以匹配目标暂停时间。
- 如果暂停时间合适,考虑应用的吞吐量,通过增大新生代的大小满足吞吐量。
- 如果暂停时间和吞吐量两个目标都满足,新生代大小降低以节约成本路径。
UseAdaptiveSizePolicy
- -XX:MaxGCPauseMillis=nnn :不能设置过小,会阻碍吞吐量,如果不设置,暂停时间依赖heap中活动数据量。
- -XX:GCTimeRatio=nnn 不超过应用运行时间的1 / (1 + nnn) 用在垃圾回收上。缺省99。垃圾回收时间不应该超过整体时间的1%
JVM微调调试方法
- 配置JVM的JAVA_OPTS参数 –verbosegc
- 观察Full GC的信息输出:
- [Full GC $before->$after($total), $time secs]
- Full GC太频繁,应用暂停,响应时间受影响。
- 克服GC太频繁方法:
- 1. 增大内存。增大年轻代的内存
- 2.使用LRU等缓存,限制大量对象创建。
- 3. 64位下压缩对象头。
- 消灭Full GC:-XX:+PrintGCDetails 无Full GC输出
内存大小影响
- 大内存:
1. 降低GC执行次数。
2.增加每次GC执行的时间。
- 小内存:
1.增加了GC执行次数
2.降低每次GC执行的时间。
如果Full GC能够在1秒内完成,10G也是合适的。
Jstat 监视微调
- jstat -gcutil 21891 250 7
- 21891是Java的pid, 250表示间隔几秒 7表示采样7次
- S0 S1 E O P YGC YGCT FGC FGCT GCT
12.44 0.00 27.20 9.49 96.70 78 0.176 5 0.495 0.672
12.44 0.00 62.16 9.49 96.70 78 0.176 5 0.495 0.672
12.44 0.00 83.97 9.49 96.70 78 0.176 5 0.495 0.672
0.00 7.74 0.00 9.51 96.70 79 0.177 5 0.495 0.673
0.00 7.74 23.37 9.51 96.70 79 0.177 5 0.495 0.673
0.00 7.74 43.82 9.51 96.70 79 0.177 5 0.495 0.673
0.00 7.74 58.11 9.51 96.71 79 0.177 5 0.495 0.673 - Minor GC :YGC年轻代GC发生了78次,YGCT是GC发生的时间累计0.176。
- FULL GC发生了5次,累计0.495, 每次是0.495/5
- http://www.cubrid.org/blog/dev-platform/how-to-monitor-java-garbage-collection/
- 如果GC执行时间在一秒以上,需要GC微调,如果在0.1-0.3之间则不需要
需要微调的案例
- Full GC超过一秒,需要微调。
- Minor GC正常
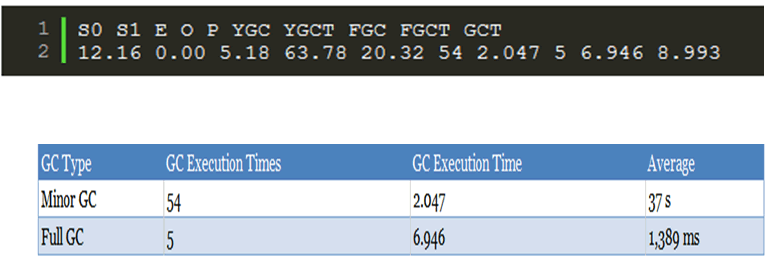
微调前检查内存大小分配
- jstat –gccapacity
- NGCMN NGCMX NGC S0C S1C EC OGCMN OGCMX OGC OC PGCMN PGCMX PGC PC YGC FGC
- 212992.0 212992.0 212992.0 21248.0 21248.0 170496.0 1884160.0 1884160.0 1884160.0 1884160.0 262144.0 262144.0 262144.0 262144.0 54 5
- 新生代是 212,992 KB,老生代是1,884,160 KB
- 新生代:老生代是1:9, 调整NewRatio
- NewRatio=2
- NewRatio=3
- NewRatio=4
- 如果其中一个设置没有FULL GC发生,就是合适新生代和老生代的大小。
- 随着新生代内存减小,其GC时间缩短:
- NewRatio=2: 45 ms
- NewRatio=3: 34 ms
- NewRatio=4: 30 ms
- 内存输出结构:
- S0 S1 E O P YGC YGCT FGC FGCT GCT
- 8.61 0.00 30.67 24.62 22.38 2424 30.219 0 0.000 30.219
- 年轻代发生了2424次,而FullGC没有一次发生,存在大量临时对象都是新生代毁灭。
Jstat参数说明

JVM优化参数
- JAVA_OPTS="$JAVA_OPTS -verbose:gc -XX:+PrintGCDetails -XX:+PrintTenuringDistribution -Xloggc:/home/jdon/jdongc.log -server -Xms1536m -Xmx1664m -XX:NewSize=768m -XX:MaxNewSize=896m -XX:+UseAdaptiveGCBoundary -XX:MaxGCPauseMillis=250 -XX:+UseAdaptiveSizePolicy -XX:+DisableExplicitGC -XX:ParallelGCThreads=4 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSIncrementalMode -XX:CMSInitiatingOccupancyFraction=80 -XX:+CMSClassUnloadingEnabled
- 最大新生代GC暂停时间是250毫秒,在这个基础上JVM自动调整尽量满足吞吐量。
- [GC 2016.468: [ASParNew: 686991K->42743K(711316K), 0.1310080 secs] 713706K->74888K(1422668K) icms_dc=0 , 0.1324500 secs]
- S0 S1 E O P YGC YGCT FGC FGCT GCT
- 0.00 64.80 93.53 4.52 66.34 7 0.619 7 2.381 3.000

如果响应时间还是不够快?
- 响应延迟和吞吐量是一对矛盾,而吞吐量主要标志是内存大小。
- 降低NewSize大小, 降低survivor空间。
- 降低进入老生代reduce的门槛,因为缓存Hold住大量长生命对象,让这些对象进口进入老生代。而老生代的CMS很少暂停。
CMS
- CMS并不进行内存压实compact,所以,会导致碎片。而碎片也会导致暂停。
- Apache Cassandra使用 slab allocator。
- 每个Slab是2M;
- 用compare-and-set拷贝他们。
- 三天
G1 vs CMS vs Parallel GC
三个垃圾回收机制的比较,语法如下:
- -XX:+UseParallelOldGC
- -XX:+UseConcMarkSweepGC
- -XX:+UseG1GC
使用GCViewer观察,结果如下 单位是毫秒:
| Parallel | CMS | G1 | |
|---|---|---|---|
| Total GC pauses | 20 930 | 18 870 | 62 000 |
| Max GC pause | 721 | 64 | 50 |
并行GC ( - XX:+ UseParallelOldGC ) 。在30多分钟的测试时间内,用并行收集器 GC暂停花了接近21秒。最长停顿了721毫秒。因此,我们以此为基准: GC降低了吞吐量为总运行时间的1.1 %。最坏情况下的延迟为721ms 。
CMS ( - XX:+ UseConcMarkSweepGC ) 同样30分钟,因为GC我们失去了不到19秒 。相比并行GC吞吐量明智的。延迟另一方面已显著改善 - 最坏情况下的延迟时间减少10倍以上!来自GC的最大暂停时间我们现在面临的只是64ms。
最闪亮的GC算法 - G1 ( - XX:+ UseG1GC ) 。在同样的测试,,我们看到的结果吞吐量问题比较严重。这一次,我们的应用程序花费超过一分钟等待GC来完成。比较这与CMS中的开销只有1% ,我们现在面对接近的吞吐量3.5 %的效果。但如果你真的不关心的吞吐量,而是想挤出最后那么一点延迟 - 比CMS提高20%左右 - 用G1看到的最长GC暂停服用仅50毫秒。
结论:CMS仍然是最好的“默认”选项。 G1的吞吐量仍然差那么多,得到的延迟通常是不值得的。
JVM推荐设置
| Heap size | Total GC pauses GC暂停 | Throughput吞吐量 |
|---|---|---|
| -Xmx 300m | 207.48s | 92.25% |
| -Xmx 384m | 54.13s | 97.97% |
| -Xmx 720m | 20.52s | 99.11% |
| -Xmx 1,440m | *11.37s | *99.55% |
多线程
同步或锁
性能测试
性能调优
高性能
可伸缩性
JVM专题讨论