2 架构技术设计
根据前面的需求分析,以一个中型系统的架构来设计本项目。在设计本例架构时,应充分考虑其扩展性和通用性。
在框架技术选择上,预备完全在J2EE的Web框架里实现。这样可以充分了解熟悉J2EE的Web技术,同时又因为Web技术相对后端EJB层来说是比较成熟的,发展变化不是非常大。
因此,本例的架构可以说是一个J2EE的Web实现的标准架构,可以将它应用到更多的中小型项目中。
2.1 架构分层图
Web技术的通用框架图已经在前面的用户注册系统章节描述过。实际上,很多重要逻辑功能和核心是采用Javabeans来实现的。那么在这些Javabeans中,也不是混乱纠缠一团的,也需要有清晰的层次和功能划分。
在这样一个系统中,整个操作流程其实涉及了很多环节。如用户通过页面输入数据,页面的美化和布局等;系统接受数据后,要结合原有的数据进行一定的逻辑运算,这部分根据系统要求的复杂性不同;数据处理后要保存以备下次再用,关于数据如何在持久化介质上存储和管理也存在相当的工作。
由此可见,如果将上述这些功能都混合在一起,必然导致以后修改维护上的困难。因此将这些功能进行归类设计,划分在不同的层次来实现,在系统伸缩性、耦合性以及重用性方面有诸多好处。
分层后的设计图如图4-3所示。
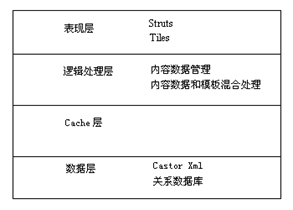
图4-3 系统架构层次图
表现层实际是JSP部分,包括一些为JSP服务的Javabeans,因为在本例中,要完全做到JSP无Java代码,必然要引入一些Javabeans为之服务。
要实现这样的目的,有很多现成的框架技术可以选择,比如JSTL(JSP Standard Tag Libraries),JSP标签库是在JSP中使用XML格式的一些特定标签来实现动态功能的。
在本例中,将采取一种Web层框架软件Strutss,这是Apache上的一个著名的开放源代码项目,在Java世界中有很多优秀的开源项目有助于启迪设计思想、提高开发速度。
用户的数据经过表现层的简单封装处理后,将被传送到第2层的逻辑处理层,由逻辑处理层根据业务逻辑来决定如何进一步操作,在这个操作中,有可能要先读取一下其他数据。那么可以通过Cache层从内存先读取,如果Cache中没有,则直接从数据库读取。
其实,Cache层不仅可以对数据库的数据实现缓冲,在性能要求比较高时,对逻辑处理中的Javabeans也可实现缓冲。
数据层主要是实现数据持久化。自从XML技术出现以后,数据持久化多了一个非常好的选择,那就是XML格式的文件。同数据库相比,XML文件对周围环境的要求相对比较低,不需要专门的数据库服务器,非常适合小型项目的成本要求。
在本例中,也使用XML文件来实现数据的持久化。
多层架构的优点主要体现为:
· 良好的解耦性: 各个功能层只负责自己相应的事务,不再相互混淆在一起。每个功能层如果在将来有所变化时,不会涉及到其他功能层,因为每个功能层是相对独立的。
· 高度的重用性: 各个层的技术都可以移植到其他应用系统。比如表现层的框架一旦确定,可以在第二个项目中同样使用这样的技术,同时还可以提高开发速度。
· 灵活的扩展性: 由于表现层和核心功能分开,可以将系统从PC应用拓展到无线等应用中,所作的修改只是表现层的更改,系统核心功能无需变化。
2.2 MVC模式与Struts
表现层涉及很多用户界面的元素,因此比较难以实现重用。但是,有一个宗旨是:不能将功能性的代码与显示性的代码混合在一起,否则,当需要更改页面或者扩展新功能时会带来很大的修改量,甚至破坏原有系统的稳定性。
因此,需要对表现层进行细化,可以将表现层分3个部分:
· 视图(View)负责显示功能。
· 控制器(Controller)根据Model处理结果,调节控制视图View的输出。
· 业务对象模型(Business Object Model)是对真实世界实体的抽象,可以是一些数据,也可以是一些处理对象或事件对象。在本项目中,业务对象就是那些包含状态和行为的Javabeans,如图4-4所示。
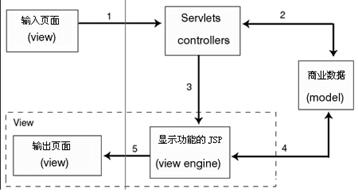
图4-4 MVC模式的流程图
图4-4是一个MVC模式的流程图。从图中可以发现一个表现层清晰的解决方案。
在MVC中,JSP实际只负责显示功能,显示功能的实现要依据客户端来确定。如果客户端是IE浏览器,那么JSP里封装的就是HTML语言;如果客户端是手机,那么JSP里封装的就是WAP语言;如果客户端是其他支持XML的客户端,那么JSP里封装的就是XML。这些客户端不同,变化的只是重新设计一套JSP,而系统的核心功能则无需任何变化,这种灵活强大的拓展性体现了MVC的魅力所在。
Servlet是控制JSP页面输出的。Servlet就像汽车调度员,可以在JSP页面非常多的情况下,实现有效清晰的流程调度管理。
使用MVC模式主要有如下好处:
· 良好的重用性:MVC可以使用多种类型的视图界面,而核心功能无需变化。比如视图界面可以从Web浏览器(HTTP)拓展到无线浏览器(WAP)。
· 极低的成本:MVC模式可以让一般水平的程序员来开发和维护用户的界面功能,降低了人员成本。
· 快速开发:由于将Java代码从JSP中去除,Java程序员和HTML 或者JSP程序员可以同时工作。而如果不采用MVC分离的模式,那么只有等Java程序员完成核心功能后,再交由美工和JSP程序员进一步加工。
· 可靠性:由于显示功能和处理功能分离,这就允许在不重新编译核心功能的情况下修改系统的视图界面和外观。
有一种观点认为只有大项目才需要采取MVC。实际上,很多时候无法确定项目的规模。因为客户的需求始终不断在变化,如果原有的基础架构不具有很强的拓展性,那么项目进行到中途时可能要再进行重新设计,很容易陷入左右为难的地步。所以,无论任何项目,用标准的架构去设计它,就如按标准的方法去做事一样,相当于成功了一半。
具体实现MVC模式的软件框架有很多,其中应用最广泛的有下列3种:
· Apache Struts(http://jakarta.apache.org/Strutss/) Struts是基于JSP的框架软件,有大量文章和参考资料面世,其中《Strutss in Action》一书非常值得一读。
· Apache Cocoon (http://xml.apache.org/) Cocoon是基于XML和XSLT技术的MVC模式实现框架,在Cocoon中很巧妙地利用XML技术实现了内容和模板分离的功能。
· Petstore WAF(Web Application Framework) Petstore是SUN公司推出的一个J2EE实例样本,WAF是其Web实现框架,其原理类似Struts。
由于Struts有大量实践应用,已经成为目前事实上的Web实现标准,而Cocoon是未来的一个发展趋势。本例中,使用Struts框架来构架本项目的Web层是一种实用而且理想的选择,当然也会引入更多XML技术,以能够向未来过渡。
本例另外一个关键问题是如何解决模板和内容分离。而这在Struts中,正好有Tile组件可以解决这个问题。Tile的总体思路是将页面划分成几块“碎片”,然后分别实现之。下面逐个介绍。
Struts框架是结合JSP、JSP 标签库以及Servlets的MVC模式实现。这里将简单介绍Struts的使用,进一步学习请参考相应书籍。图4-5是Struts实现MVC的流程图。
MVC模式的实现核心是控制器(Controller)部分,ActionServlet是Struts的控制器的核心,它将根据来自用户的请求,调用在Strutss-config.xml中配置好的ActionMapping,从其中寻找到相应Action具体实现类。具体实现类所要做的就是要继承实现Action类中的Execute方法(已经不推荐使用perform()方法)。
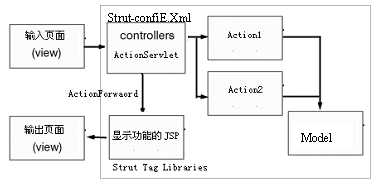
图4-5 Struts的流程图
在Action类的Execute方法中,要实现两个功能:
· 将用户输入的数据传递到后台处理,Struts已经把用户输入的数据封装在ActionForm类中,只要从其中读取数据,形成新的数据对象,递交给逻辑处理层来处理。
· 在后台处理完成后,需要根据使用Struts提供的ActionMapping来指定输出的视图(View)。
Struts的原理比较复杂,初学者若要迅速上手,则应该首先学会如何使用Struts,这样通过不断深入使用,会逐渐了解其原理和运行机制。
Tile是有关视图界面的组件。Tile主要是将一个页面划分成几个部分,分别对应不同的JSP,大大提高了视图界面元素的可重用性。
使用Tile有很多优点。例如在很多项目中,页面的头部和尾部都是固定的。一般会采取下面的做法:
<html>
<body>
<%-- include header --%>
<jsp:include page="/header.jsp" />
这里是Body 内容部分:
<p>
<%-- include footer --%>
<jsp:include page="/footer.jsp" />
</body>
</html>
使用include的主要问题是:
· 如果要修改的不只是头部和尾部,而是整个页面的布局,那么就必须逐个进行页面的修改。
· 大量include嵌套使用,这类似面向过程语言中的GoTO语句,会使维护扩展变得非常困难,但是因为编写简单直接,不少程序员还是可能喜欢这样做。在一个项目中开这种先河,将出现大量层层重叠的include语句,严重破坏了页面的可扩展性和可维护性,使得页面修改扩展成为整个系统的恶梦。
· 调试不方便。include分动态静态两种用法,静态用法调试很不方便,因为即使被include的JSP页面在一些容器中,主页面如果不修改,容器将不会重新载入新的使用“include”语句调用的子页面,除非调用者页面和被调用者页面均被修改。
如果使用Tiles来改造上面的问题,将会有一个很巧妙干净的解决方式:
<%@ taglib uri="/WEB-INF/tiles.tld" prefix="tiles" %>
<html>
<body>
<%-- include header --%>
<tiles:insert page="/header.jsp" flush="true"/>
这里是Body 内容部分:
<p>
<%-- include footer --%>
<tiles:insert page="/footer.jsp" flush="true"/>
</body>
使用tiles:insert代替了include。更深入一点,可以修改成这样:
<tiles:insert page="/layout.jsp" flush="true">
<tiles:put name="header" value="/header.jsp"/>
<tiles:put name="body" value="/body.jsp"/>
<tiles:put name="footer" value="/footer.jsp"/>
</tiles:insert>
在这段代码中,Tile将一个页面划分为4个区域,分别由对应的JSP来实现。页面布局由layout.jsp实现,这样当需要修改布局时,只要修改layout.jsp一个文件就可以了。
Tile提供的关于页面布局的解决方案非常适合应用到本项目中。
2.3 Castor与XML持久化
在Java中,对象序列化成二进制数据是比较方便的。但是将一个对象序列化成XML文本时,也许就没那么简单了。对象和XML之间序列化和反序列化依赖很多方面,比如文本的编码、映射设置等。
将包含数据的对象序列化成XML文本后,就可以很方便地实现数据的持久化保存。
数据持久化表示数据将脱离应用程序的生存周期,也就是说,当这个应用程序退出或计算机关机,这些数据还将继续存在。因为这些数据已经被保存到永久存储介质上,如硬盘文件系统或关系数据库系统。
关系数据库是最经常使用的存储介质,在以后章节中将讨论结合EJB来使用关系数据库。将XML文件存储到硬盘文件系统中也是一种可选的持久化方案,这种方案的优点就是开发或维护的成本比较低,本项目中将使用硬盘文件系统作为存储介质。
对象的序列化需要很丰富的XML API,最经常使用的就是SAX和DOM,但是在做一些简单的XML操作时,如获取XML中一个数据,首先遍历整个文档的树形结构,在父子或兄弟关系的节点上导航一番,这些都会需要编写很多代码,可见是非常琐碎和麻烦。
JDOM(http://www.jdom.org/)在这方面做得比较好,它用来分析XML文本是非常方便的,在本项目中,可以使用JDOM来读取系统的XML配置文件。
但是,在使用JDOM实现将对象序列化到XML文本时,代码还会涉及到该XML文本的结构。也就是说,在代码中硬编码XML文本的节点名称,这是非常不具备可重用性和拓展性的。
要达到良好的重用性和灵活的扩展性,就必须将一些操作细节封装起来,因此,需要将XML和数据交互操作的细节封装起来,这就会使用到DBO模式。
在讨论DBO模式(Data Bind Object Pattern)之前,首先必须了解一个很重要的概念,就是MVC模式中的Model。它泛指的是一种业务对象模型(Business Object Model),数据对象模型(Data Object Model)是业务对象模型的一种,它包含状态以及操作状态的行为。数据对象也可以被认为等同于经常提到的另外一个名词:值对象(Value Object)。
数据对象是对真实世界中实体软件的抽象。它可以是人、事或地方以及一些商业概念,比如订单、客户这些概念也属于业务对象。
例如“人”可以形成一个数据对象,如下:
public class Person implements java.io.Serializable {
//人的姓名
private String name = null;
// 人的年龄
private Integer age = null;
//没有名字的情况下创建一个人
public Person() {
super();
}
//以一个给定的名字创建一个人
public Person(String name) {
this.name = name;
}
// @return 返回这个人的年龄
public Integer getAge() {
return age;
}
// @return 返回这个人的名字
public String getName() {
return name;
}
// 设置这个人的年龄
public void setAge(Integer age) {
this.age = age;
}
// 设置这个人的名字
public void setName(String name) {
this.name = name;
}
}
在这个数据对象中,定义了人的一些属性。比如他的名字、年龄,而且有一些setXXX getXXX操作这些属性。这个类Person是对现实中“人”对象化的概括。
将这个类序列化成XML文本,将会涉及很多操作细节。使用DBO模式可以封装这些细节,从而达到代码的可重用性。
DBO模式有3个参与角色:
· 数据对象:将要被序列化到XML或从XML反序列化的对象。
· 数据绑定对象:这是一个工具型的基本对象,这个基本对象抽象了XML的序列化和XML API的具体使用细节。
· XML 序列化 API: 真正实现XML序列化的具体行为,具体实现可以采取JDOM、Castor、JAXB或其他类似工具。
与JDOM相比,Castor XML更好地封装XML序列化过程,使用Castor XML需要亲自编写的代码将更少。也可以说Castor XML其实是DBO模式的具体实现。
Castor(http://castor.exolab.org/)是一种将Java对象和XML自动绑定的开源软件。它可以在Java对象、XML文本、SQL数据表以及LDAP目录之间绑定。
下面CastorHandler类是使用Castor XML将Person对象序列化到XML文本,并直接持久化保存到文件系统:
/**
* 使用Castor作为XML文件和对象的绑定工具
* <p>Copyright: Jdon.com Copyright (c) 2003</p>
* <p>Company: 上海极道计算机技术有限公司</p>
* @author banq
* @version 1.0
*/
public class CastorHandler {
public final static String module = CastorHandler.class.getName();
private static PropsUtil propsUtil = PropsUtil.getInstance();
/**
* 获得对象和XML之间映射的关系
*/
public static Mapping getMapping(String MappingFile) {
Mapping mapping = (Mapping) SimpleCachePool.get(MappingFile);
if (mapping == null) {
String pathMappingFile = propsUtil.getConfFile(MappingFile);
try {
mapping = new Mapping();
mapping.loadMapping(pathMappingFile);
SimpleCachePool.put(MappingFile, mapping);
} catch (Exception e) {
Debug.logError("get mapping error " + e, module);
}
}
return mapping;
}
/**
* 获得反序列化的对象
*/
private static Unmarshaller getUnmarshaller(String MappingFile,
String className)
throws Exception {
Unmarshaller un = (Unmarshaller) SimpleCachePool.get(className);
if (un == null) {
try {
Class c = Class.forName(className);
un = new Unmarshaller(c);
un.setMapping(getMapping(MappingFile));
SimpleCachePool.put(className, un);
} catch (Exception e) {
Debug.logError(" getUnmarshaller error: " , module);
throw new Exception(e);
}
}
return un;
}
/**
* 从XML文件中读取对象
*/
public static Object read(String MappingFile, String className,
String xmlfile) throws Exception {
Object object = null;
try {
Unmarshaller un = getUnmarshaller(MappingFile, className);
FileReader in = new FileReader(xmlfile);
object = un.unmarshal(in);
in.close();
} catch (Exception e) {
Debug.logError(" read " + className + " form file:" + xmlfile + e, module);
throw new Exception(e);
}
return object;
}
/**
* 将对象序列化到XML文件中
*/
public static void write(String MappingFile, Object object, String outfile) throws
Exception {
try {
FileWriter out = new FileWriter(outfile);
Marshaller ms = new Marshaller(out);
ms.setMapping(getMapping(MappingFile));
ms.setEncoding(propsUtil.ENCODING);
ms.marshal(object);
out.close();
} catch (Exception e) {
Debug.logError("write object to file :" + e, module);
throw new Exception(e);
}
}
}
调用CastorHandler:
String mappingFile = "mapping.xml";
String outfile = "d:\data\person.xml";
// 创建一个新的对象
Person person = new Person("板桥里人");
person.setAge(new Integer(33));
CastorHandler.write(mappingFile, person, outfile)
其中mapping.xml是对象和XML之间结构的映射表:
<mapping>
<description>a map file for the personion>
<class name="Person
<field name="name” type="string" />
<field name="age” type="integer" />
</class>
</mapping>
这样就把person对象写入到d:\data\person.xml文件中。该CastorHandler是DBO模式中的数据绑定对象;person是数据对象;在CastorHandlet中封装的是关于XML序列化的API。例如: getMapping方法是获取org.exolab.castor.mapping.Mapping的一个实例,而getUnmarshaller是获得一个反序列化的对象等。
遵循DBO模式的CastorHandler可以被用来进行任何对象到XML的序列化或反序列化,与具体的XML文本结构就无任何关系,所以,良好的重用性是使用DBO模式的一个显著优点。当然,因为与XML文本结构的关系定义在mapping.xml配置文件中,使用CastorHandler时就必须配置这样一个mapping.xml,对于一些只有XML的读取操作来说,过于复杂了点。
但是,在本项目中,CastorHandler可以方便地实现内容数据的持久化,其操作的简易性和方便性已经远远超过它的缺点。
2.4 Cache缓存设计
是否有缓冲机制(Cache)是衡量一个J2EE产品是否成熟的重要标志。因为缓冲对于J2EE系统的运行性能有至关重要的作用,特别是在大量用户并行访问时,没有缓冲机制几乎是不可想象的事情。
J2EE作为一个多层结构,每发生一次请求,将可能经过系统的许多层次。这些层次中有的可能位于另外一台服务器上,那么网络连接开销将延迟请求信号的处理时间。使用缓冲可以节约请求信号的处理时间,大大提高系统的整体响应能力。
在J2EE系统运行中,有大量经常使用的对象,如session对象和用户资料对象等,创建这些对象可能需要首先访问数据库或文件系统;而销毁这些对象则需要释放该对象占用的内存,因此,创建和销毁对象的过程可能是复杂的,造成的性能损耗也是非常大的。
为了避免创建和销毁的开销,将那些频繁使用的对象保存在内存缓冲中,这样就能大幅度提高应用系统的性能。
在单个JVM中实现缓冲是比较容易的,应用系统通过一个Singleton接口从内存缓冲中读取数据,如果缓冲中没有所要读取的数据,那么就从存储介质或网络连接中读取,读取后再将此数据保存到缓冲中,由于缓冲内存容量有限,缓冲系统会将访问不频繁的数据逐步从缓冲内存中删除,这就是 LRU (Last Recently Used)算法。
另外,缓冲还有校正的问题,缓冲只是将数据源的数据保存在内存中。在一个分布式环境中,如果数据源被其他用户从其他服务器进行更改,那么必须通知所有有关这个数据源的缓冲进行及时更新。
因此,在一个分布式的集群Cluster(负载平衡和错误恢复)环境中,Cache的设计就比较复杂。综合各种因素,使用JMS(Java Message System)进行这种通知信息提示是一种比较切实可行的方案,带来的性能损失也不是很大,支持分布式环境的不少缓冲产品已经面世。因此,一个系统从单机环境升级到分布式环境,缓冲机制可能要作一定的修改。
在本项目中,所有的数据对象都是以XML存储在文件系统中。文件的频繁读写是非常耗时的,因此需要对数据对象实现缓冲。