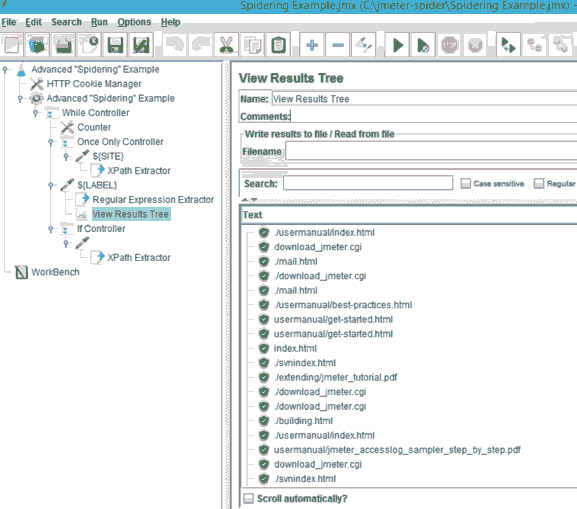
如何使用Jmeter模拟爬虫测试
在构建Web应用程序负载压力测试时,您可能需要模拟一组用户“抓取”网站并随机单击链接。特别是对于动态网站,如博客,新闻门户,社交网络等,新内容被频繁添加或甚至实时添加。 这种形式的测试能确保用户将获得流畅的浏览体验,并检查断开的链接或任何意外错误。
本文介绍了模拟网站“爬网”的3种最常用的方法:点击网页中找到的所有链接、使用HTML链接解析器和高级spidering测试计划。
1.单击网页中找到的所有链接
使用正则表达式提取得到的链接的过程在JMeter的使用正则表达式一文被描述。算法如下:
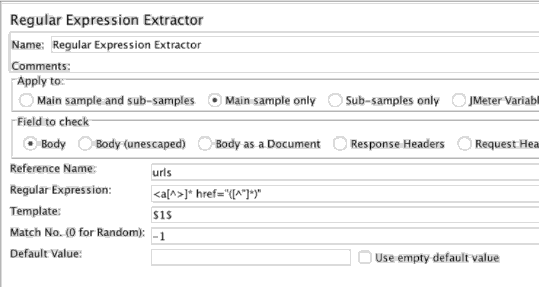
1a。 从响应中提取的所有链接正则表达式提取并将它们存储到JMeter的变量。相关的正则表达式将是:
<a [^>] * href =“([^”] *)“
不要忘记设置匹配编号No.为-1提取所有的链接。 如果将其留空,则只返回第一个匹配项。
1b。 使用的ForEach控制器迭代提取的链接。
1c。 使用HTTP请求取样器点击选择URL,在 Output Variable 输出变量名中 。
演示
优点
-
配置简单。
-
稳定性。
-
故障转移和恢复能力。
缺点
-
正则表达式很难开发,对标记变化敏感,因此很脆弱。
-
实际上不是“爬虫”或“蜘蛛”,只是对链接进行请求。
2.使用HTML链接解析器
JMeter的提供了一个特殊的测试元件, HTML解析器的链接 。 此元素设计用于提取HTML链接和表单,并使用提取的值替换匹配的HTTP请求采样器相关字段。 因此,HTML链接解析器可用于模拟使用最少配置抓取网站。 方法如下:
2a。 把HTML解析器链接放入 Logic Controller 逻辑控制器 下
2b。 把HTTP请求取样器放入逻辑控制器下,配置服务器名称或IP地址和路径字段提取值限制在一个“有趣”的范围。 您可能希望专注于属于被测试应用程序的域,并且不希望它在Internet上爬网,因为如果您的应用程序有任何链接到外部资源; JMeter会去外面抓爬。 Perl5风格的正则表达式可以用来设置提取的链接范围。

演示
优点
-
易于配置和使用。
-
行为像一个“蜘蛛”。
缺点
-
零误差公差; 任何从响应中提取链接的失败将导致后续请求的级联失败。
3.高级“Spidering”测试计划
假设上述方法的局限性,您可能想要一个解决方案,它不会因为错误而崩溃,并且将爬行整个被测试的应用程序。 下面你可以找到一个参考测试计划大纲,可以用作你的“蜘蛛”的骨架:
3a。 打开主页面。
-
从中提取所有链接。
-
点击随机链接。
-
如果返回值有“good”的MIME类型 (如果图片或PDF文件或任何链接提取链路结果将被跳过); 从响应中提取所有链接
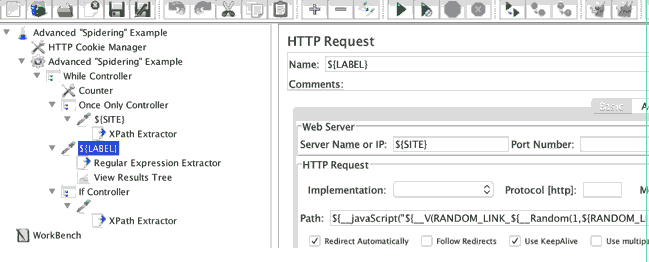
所用元素的说明:
-
While Controller 是用来设置请求的最大额,所以测试不会永远持续下去。 如果您透过排程scheduling限制,可以略过。
-
Once Only Controller 用于执行调用的主网页只有一次。
- XPath Extractor 用于过滤掉不属于该应用程序下测试不感兴趣例如mailto, callto ,等等。一个示例XPath查询将看起来像网址等各个环节:
//a[starts-with(@href,'/') or starts-with(@href,'.') or contains(@href,'${SITE}') and not(contains(@href,'mailto'))]/@href
使用XPath不是必须的,在某些情况下,它可能是非常内存密集型。 您可能需要考虑从响应中提取链接的其他方法。 它用于演示目的,因为通常XPath查询比CSS / JQuery,特别是正则表达式更加人性化。
- __javaScript() function 实际上做了三件事:
-
从XPath提取器提取的选择一个随机链接。
-
从URL的开始删除../。
-
将HTTP请求标题设置为当前随机URL。
-
- Regular Expression Extractor 用于从响应中提取Content-Type头
-
If Controller 使得它使下一轮从响应中提取链接,如果响应已匹配的内容类型才启动。