关系数据库是如何工作的?
如果不了解关系数据库是如何工作,就很难掌握很多事务相关的概念,如原子性,持久性和checkpoint等概念。在这篇文章中,将描述一个关系数据库内部如何工作,同时揭露一些数据库特定的实现细节。
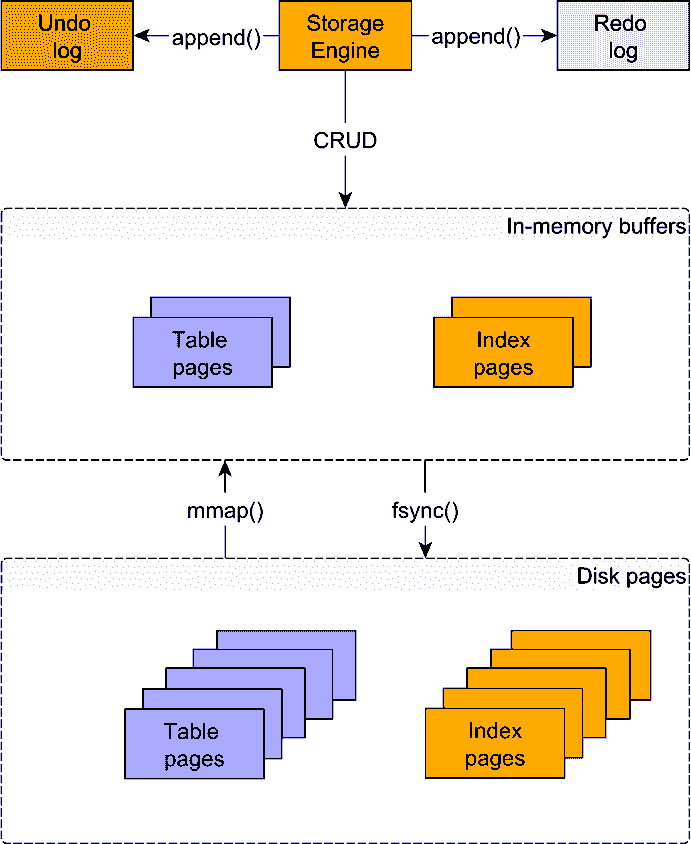
首先看看下面这张图,它基本揭示了关系数据库的工作原理,我们会就这张图进行详细解释和说明。图中Storage Engine是存储引擎,SQL语句在这里运行,CRUD增删改查操作本身作为动作事件会追加到两个日志,Undo日志和Redo日志,CRUD运行结果会影响内存中缓冲In-memory buffers,包括表页Table pages和索引页Index pages,内存中这两部分数据会通过mmap()和fsync()持久保存到数据库中。
数据页
由于磁盘访问缓慢,内存存储器甚至比固态驱动器都快几个数量级。为此,数据库供应商尽可能地延迟磁盘访问。无论我们是在谈论表还是索引,数据都被分成一定大小的页面(例如8 KB),也就是数据页。
当需要读取数据(表或索引)时,关系数据库会将基于磁盘的页面映射到内存缓冲区。当需要修改数据时,关系数据库会更改内存页。要将内存页面与磁盘同步,同时必须进行刷新(例如fsync)。
撤消Undo日志
因为内存中的更改结果可能被多个并发事务访问,所以必须采用并发控制机制(例如2PL或MVCC),以确保数据完整性。因此,一旦事务已修改某表的某行,未提交的更改将作用于内存中数据页,而修改之前的数据将临时存储在Undo日志这样只能不断追加的数据结构中。
虽然这种结构在Oracle和MySQL中称为* undo log *,但在SQL Server中,事务日志扮演着这个角色。PostgreSQL没有撤销日志,但是使用多版本表结构实现了相同的目标,因为表可以存储同一行的多个版本。然而,所有这些数据结构都用于提供回滚能力,这是原子性的强制性要求。
如果当前运行的事务回滚,则撤消日志将会在事务开始时重建内存数据页。
重做Redo日志
一旦事务提交,内存中的更改必须持久化。但是,这并不意味着每个事务提交都会触发fsync。事实上,这将对应用程序性能非常不利。然而,根据ACID事务属性,我们知道提交的事务必须提供持久性,这意味着提交的更改需要持久化,即使我们拔掉数据库引擎不会影响。
那么,关系数据库如何提供持久性而不在每次事务提交时发出fsync?
这是重做日志发挥作用的地方。重做日志也是一个仅追加数据到磁盘中的数据结构,用于存储给定事务所经历的每个更改。因此,当事务提交时,每个数据页更改也将写入重做日志。与刷新不变数量的数据页相比,写入重做日志非常快,因为顺序磁盘访问方式比随机访问方式快。因此,它还允许交易快速。
虽然这种结构在Oracle和MySQL中称为* redo log *,但在SQL Server中,事务日志也起到了这种作用。PostgreSQL称它为Write-Ahead Log(WAL)。
但是,什么时候内存刷新到磁盘?
关系数据库系统使用检查点checkpoint来同步内存中的脏数据页与磁盘数据。为了避免IO业务拥塞,同步通常在较大时间段内以块来完成。
但是,如果关系数据库在将所有脏内存页刷新到磁盘之前崩溃了,怎么办?
在崩溃的情况下,启动时,数据库将使用重做日志来重建自上次成功的检查点后未同步的基于磁盘的数据页。
结论
采用这些设计考虑主要是想克服基于磁盘存储器的高延迟,同时仍提供持久存储保证。因此,需要撤消日志来提供Atomicity(回滚功能),而需要重做日志来确保基于磁盘的页面(表和索引)的持久性。