开源消息系统Apache Kafka, RabbitMQ和NATS比较(2)
前面章节我们比较了Apache Kafka的使用,现在我们再看看RabbitMQ和NATS。
RabbitMQ
RabbitMQ是一个开源消息引擎,遵循 AMQP 0.9.1 definition of a broker,它是一种标准 store-and-forward 模式,你可以选择将数据存储在内存或磁盘,支持各种消息路由范式,能以集群方式部署,消费者直接监听队列,但是发布者只是知道有一个exchanges, 这些exchanges是通过绑定连接到队列的,这种绑定是一种指定路由范式。
下面是它的管理界面management console.
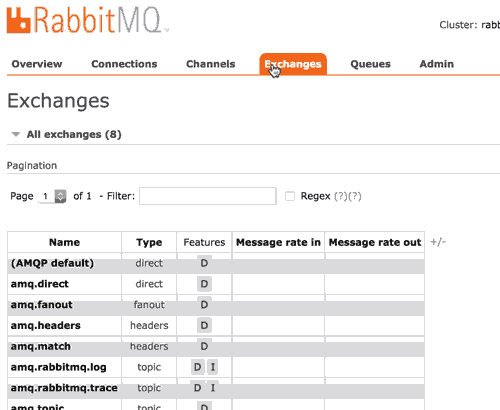
下面我们做一个publish-subscribe案例,增加一对队列:notes1和notes2,然后展示如何创建exchange,为了发送输入消息到所有订阅者,我们使用fanout路由类型,其他选项包括diect(指定路由key),topic(依赖匹配的路由key)或header(以消息头路由)
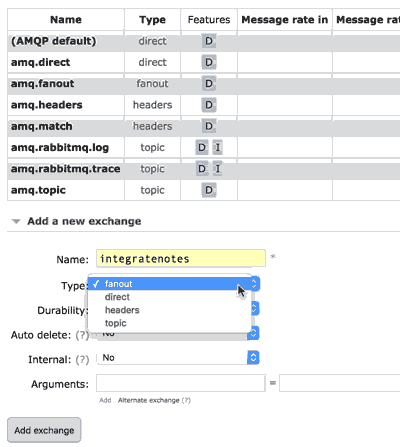
下面是有一个选项绑定这个exchange到另外一个exchanger或一个队列,这里我们绑定到自己创建的notes1队列中:
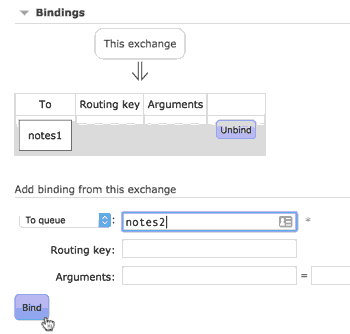
任何进入这个exchange的消息将进入两个队列,我们的node.js应用使用 amqplib module推送消息。
正如你看到,我们会有监听者监听这个队列以得到消息。
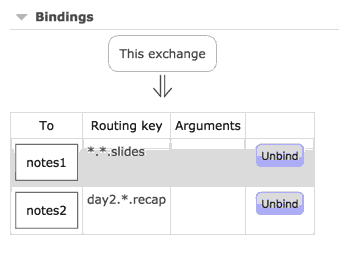
下面这个演示是使用diect路由,这需要指定一个路由key,这意味着每个队列会接受到消息,前提是它们的绑定匹配提供的路由key:
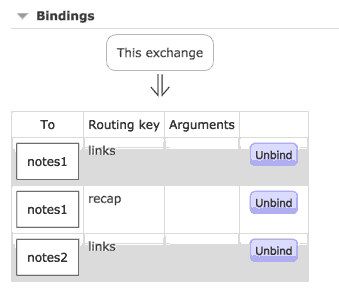
你也可以使用通配符来匹配:
NATS
NATS原来是使用Ruby编写,可以实现每秒150k消息,后来使用Go语言重写,能够达到每秒8-11百万个消息,整个程序很小只有3M Docker image,它不支持持久化消息,如果你离线,你就不能获得消息,它是工作已publish-subscribe引擎,但是你能获得人造的队列。
下面演示使用Node.js实现每秒100万消息,这里我们使用nats-top一口气推送一千两百万的消息。

一千六百万消息每秒,而且很少使用到CPU,非常令人惊奇。
下面演示是假设微服务场景中,运行时定位服务非常重要,但不能在设计编程时硬编码到这些服务,使用 Consul可以很好实现,但是如果你有一个高性能消息总线,你实现它们之间的松耦合,下面这个案例是要查询服务端点,它发布一个请求然后等待在线服务的返回:
每个微服务都有一个监听者连接到NATS,如果它接收到一个"are you online"请求,会回复。下面是每个服务的监听NATS代码:
当我调用这个端点时,我会得到一对响应,因为两个服务都会回复,客户端需要选择其中一个调用,或者我们将服务监听者放到queue group,这意味着仅仅一个订阅者会得到请求: