Eurake的自我保护机制
从CAP定理角度看,Eureka是一个AP系统,以高可用性为主,而zookeeper则是CP,以高一致性为主,所以如果使用ZK在服务发现和注册方面,可用服务信息虽然很及时,但是会出现不可用情形,造成无法克服的生产事故。Eureka则是在出现网络分区期间(无法通讯,出现需要重试的情况就是由于网络已经分区了),注册表中的信息在服务器之间不一致,自我保护(self-preservation)功能旨在最大限度地减少这种不一致性。
定义自我保护
自我保护是一种功能,当Eureka服务器超过某个时间阈值没有收到心跳(来自同级和客户端微服务)时,它会停止失效注册表中的实例,因为按一般常理,如果没有收到某个实例的心跳,应该失效那个实例的心跳。
让我们试着详细了解这个概念。
从健康的系统开始
考虑以下健康系统。
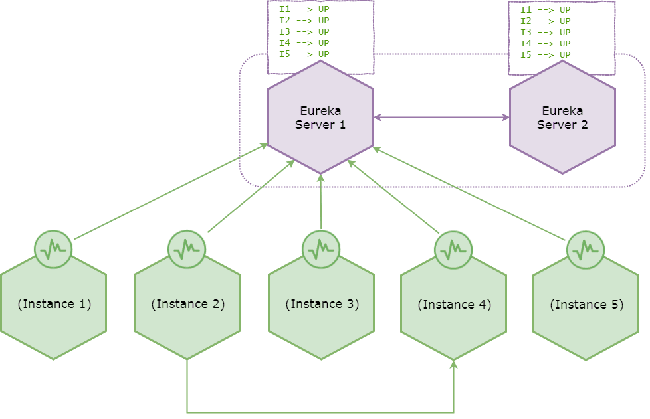
假设所有微服务都处于健康状态并在Eureka服务器1上注册。如果您想知为啥只注册到server1原因 :因为注册时配置导致,心跳只发送到service-url列表中配置的第一台服务器。即
eureka.client.service-url.defaultZone = server1,server2
Eureka服务器与相邻对等方之间者采取复制注册表信息方式,并且这两个服务器注册表都指示所有微服务实例都处于UP状态。上图还说明实例2从Eureka注册表中发现实例4之后还调用了它。
遇到网络分区
假设发生网络分区,系统转换到以下状态。
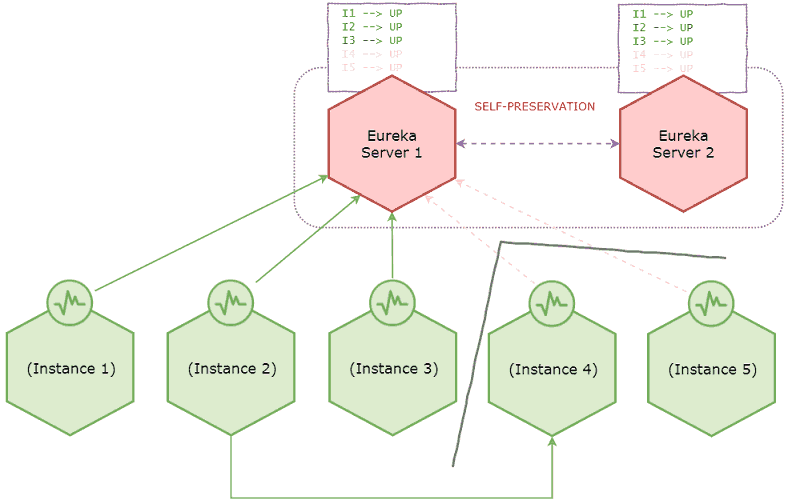
上图中由于网络分区实例4和5与服务器失去连接,但是实例2仍然连接到实例4,这时Eureka服务器会按照常理从注册表中删除实例4和5,因为它不再接收到这两个实例心跳,这时它也进入观察期,如果在一段观察期内又失去超过15%的心跳,它就会进入自我保护模式。
从现在开始,即使剩余的实例也出现故障,Eureka服务器也不会删除注册表中的这些实例了。
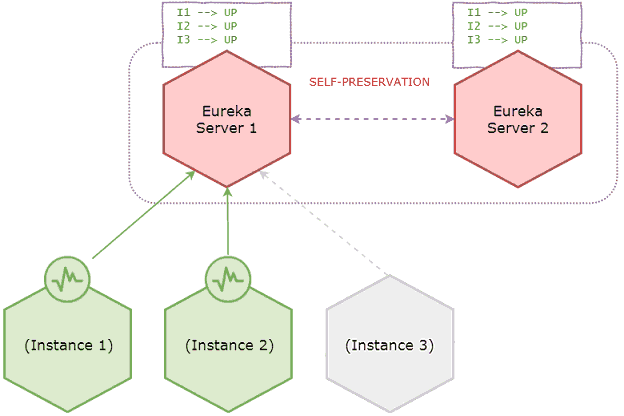
上图中实例3已关闭,但它在服务器注册表中保持活动状态。不过,服务器还是能够接受新的注册实例。
自我保护背后的理由
注意:没有接受心跳意味着两种可能:网络故障;原实例真的下线了。如何判断这两个故障其实很难,这是分布式系统典型拜占庭将军问题,解决方式一般两个:接受现状或重试。接受现状就是允许网络故障的两端数据不一致,根据CAP定理,就是选择了AP,而如果不断重试,则是为了让两端数据尽快一致起来,实际就是选择 了CP,Dubbo的源码中使用Netty长连接以及ZoopKeeper本身的都是CA,这些都是符合人的自觉,但是Eureka选择了接受现状,选择了AP,对网络分区的容忍性提高,可用性也提高了。
具体来说,由于以下两个原因,自我保护功能可以证明是合理的。
- 没有接收心跳的服务器可能是由于网络分区,接受分区,保留暂时的不一致,提高可用性。
- 即使服务器和某些客户端之间的连接丢失,客户端也可能相互连接。即,在网络分区期间,实例2还是具有与实例4的连接,如上图所示。
自我保护的默认配置
下面列出的是可以直接或间接影响自我保护行为的配置。
eureka.instance.lease-renewal-interval-in-seconds = 30
表示客户端向服务器发送心跳的频率,不建议更改此值,因为自我保护假设始终以30秒的间隔接收心跳。
eureka.instance.lease-expiration-duration-in-seconds = 90
表示服务器在收到最后一次心跳之后等待的持续时间,然后才能从其注册表中删除实例。该值应大于lease-renewal-interval-in-seconds。此值设置得长会影响每分钟实际心跳的精确性,在下一节中会有描述的,因为注册表的活力取决于这个值。将此值设置得太小可能会使系统无法容忍临时网络故障。
eureka.server.eviction-interval-timer-in-ms = 60 * 1000
调度程序以此频率运行,如果实例的租约按照这种配置时间发生过期现象,这将从注册表中删除。将此值设置得太长会延迟系统进入自保护模式。
eureka.server.renewal-percent-threshold = 0.85
此值用于计算每分钟的预期心跳。
eureka.server.renewal-threshold-update-interval-ms = 15 * 60 * 1000
调度程序以此频率运行,计算每分钟的预期心跳。
eureka.server.enable-self-preservation = true
最后但并非最不重要的是,如果需要,可以禁用自我保护。
理解配置
如果actual number of heartbeats in last minute小于expected number of heartbeats per minute,Eureka服务器就会进入自我保护模式,
预期的每分钟心跳次数
我们可以看到计算每分钟心跳预期阈值的方法。Netflix代码假定此计算始终以30秒的间隔接收心跳。
假设某个时间点的已注册应用程序实例数为N,配置renewal-percent-threshold为0.85。
- 一个实例预期的心跳数/ 分钟= 2
- N个实例预期的心跳数/分钟= 2 * N.
- 预期最小心跳/ 分钟 = 2 * N * 0.85
由于N是变量,因此默认情况下每15分钟计算一次2 * N * 0.85结果。或基于renewal-threshold-update-interval-ms的设置时间计算。
最后一分钟的实际心跳次数
这是由调度程序计算的,调度程序以一分钟的频率运行。
同样如上所述,两个调度器独立运行以便计算实际和预期的心跳数。有另一个调度程序会比较这两个值并确定系统是否处于自我保存模式 - 也就是EvictionTask。这个调度程序以eviction-interval-timer-in-ms定义的时间频率运行并删除过期的实例,但它会在删除之前检查系统是否已达到自我保护模式(通过比较实际和预期的心跳)。
每次启动时,eureka仪表板也会进行此比较,会显示消息“INSTANCES ARE NOT BEING EXPIRED JUST TO BE SAFE”。
结论
- 在大多数情况下,eureka会误报微服务实例下线是因为糟糕的网络分区。
- 自我保护永不失效,也就是一直保持着,直到并且除非关闭微服务(或解决网络故障)。
- 如果启用了自我保护,我们无法微调实例心跳间隔,因为自我保护假定心跳以30秒的间隔接收。
- 除非你的环境中常有网络故障,否则将其关闭(即使大多数人建议将其保留),由于本地调试很容易触发保护机制,出现警告信息:EMERGENCY! EUREKA MAY BE INCORRECTLY CLAIMING INSTANCES ARE UP WHEN THEY'RE NOT. RENEWALS ARE LESSER THAN THRESHOLD AND HENCE THE INSTANCES ARE NOT BEING EXPIRED JUST TO BE SAFE, 可设置eureka.server.enable-self-preservation=false参数来关闭保护机制。