Hadoop大数据教程
Hadoop - CVE-2021-36151:Hadoop令牌的安全漏洞

Apache Gobblin:本地凭证披露漏洞:在 Apache Gobblin 中,Hadoop 令牌被写入一个临时文件,该文件对类 Unix 系统上的所有本地用户可见。这会影响版本 <= 0.15.
谓词下推:计算和存储分开进行分析是低效的?
将计算和存储分开进行分析是非常低效的,也许我们应该支持谓词和投影下推到存储?谓词下推predicate pushdown是指提取 where 子句条件并使用它们修剪您从磁盘读取的数据的优化(从执行引擎.
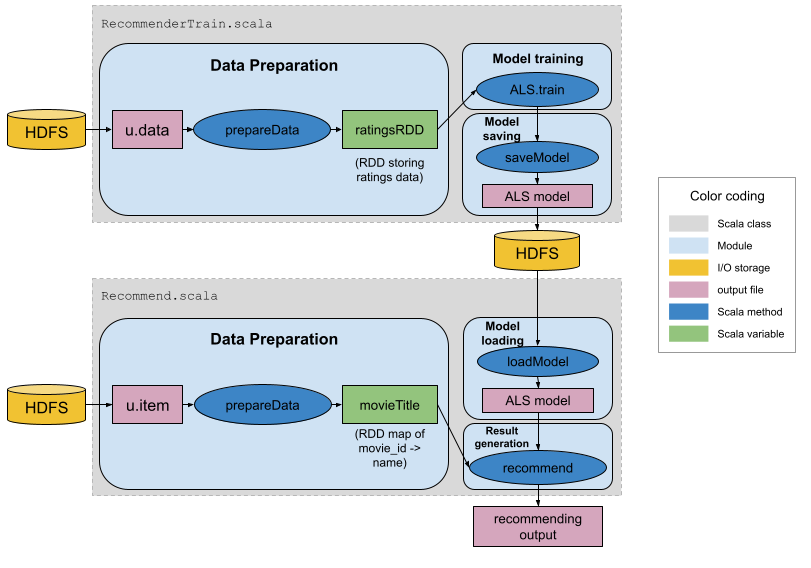
系统设计:使用Scala、Spark和Hadoop构建推荐系统
Spark已死?DBT会替代?

数据世界再次发生变化。自从 Hadoop 出现以来,人们就将工作负载从他们的数据仓库转移到了新的闪亮的数据湖中。没过多久,2010 年开源的 Spark 就成为了数据湖上的标准处理引擎。现在我们看到一.
Log4j 1.x 将直接升级到Log4j2

在Maven中配置:<groupId>log4j</groupId><artifactId>log4j</artifactId><version>${log4j2.version}</version>.
数据网格将替代数据仓库或数据湖?- thenewstack

数据网格由Thoughtworks的技术顾问 Zhamak Dehghani 于一年多前开发的,旨在纠正她认为当今商业世界中数据生成和消费方式的主要缺陷:它从DDD领域驱动设计(用于开发微服务)、De.
Hadoop一键下载安装包

Bitnami 打包的 Hadoop 提供了 Hadoop 的一键安装解决方案。可下载到本地的虚拟机、或云计算Docker中运行您自己的 hadoop 服务器。点击标题Hadoop 是一个免费的、基于.
WebHDFS :通过Web访问Hadoop分布式文件系统 (HDFS)的开源工具

Hadoop是一个框架,可为您提供任何类型的数据存储,并允许您在商品硬件集群上运行计算。许多机构使用 Hadoop 分布式文件系统 (HDFS)作为大数据项目的战略存储平台,因为它具有容错性、高并行化.
快速构建Hadoop的入门练手环境

本文提供了一种快速上手Hadoop的方法:第一步是找到一个沙盒或开发环境,在那里你可以在没有太多开销和风险的情况下玩转技术。对我来说,最好的方法是使用我自己的笔记本电脑作为测试,但我也知道一些开发者喜.
ShifuML/shifu: Hadoop上的机器学习和数据挖掘框架
来自Paypal的Shifu是一个建立在 Hadoop 之上的开源、端到端的机器学习和数据挖掘框架。Shifu 专为数据科学家设计,简化了构建机器学习模型的生命周期。虽然最初是为欺诈建模而构建的,但 .
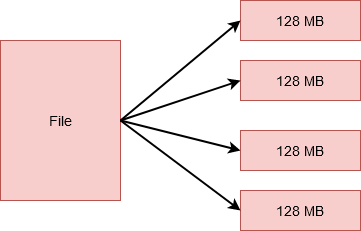
Hadoop的HDFS架构入门
使用Python分析大量数据应该学些什么?
如果您想使用 Python 分析大量数据,该研究什么?对于大数据,我们不能相信只有语言就足够了。Python 之所以合适,是因为它可以方便地管理数学库、简洁且易于管理异构和多维数据结构,但大数据还需要.
Hadoop会在2022年过时吗?

这个问题的答案是相当不确定的。一方面,Hadoop 是一种 IT 解决方案,与任何其他解决方案一样,它的衰落是完全有可能的。此外,云正在大数据世界中占据越来越多的空间。另一方面,许多公司仍在考虑实施该.
Apache Impala 架构
Impala 是一个大规模并行查询引擎,可在现有 Hadoop 集群中的数百台服务器上运行。与查询处理和底层存储引擎紧密耦合的标准关系数据库管理系统不同,它与后者分离。Impala 提高了 Apach.
大数据文件格式比较:AVRO vs. PARQUET vs. ORC
为什么我们需要不同的文件格式?对于 MapReduce 和 Spark 等支持 HDFS 的应用程序而言,一个巨大的瓶颈是在特定位置查找相关数据所需的时间以及将数据写回另一个位置所需的时间。这些问题随.
为什么 LinkedIn 改变了他们的数据分析技术堆栈 - Quastor
LinkedIn 之前使用Teradata 第三方专有平台进行数据分析技术堆栈,这种方法导致了扩展问题,并使系统难以发展,LinkedIn 转而使用开源软件和 Hadoop 生态系统。Steven C.
Hadoop的故事
今天云原生技术的大数据中心取代了Hadoop,Kubernetes 取代了 YARN 作为工作负载编排器,亚马逊S3 兼容的对象存储取代了 HDFS 来存储海量数据。但是在 2011 年,Hadoop.
数据湖 vs 数据仓库 vs 数据库

对于外行来说,数据存储通常在传统数据库中处理。但是对于大数据,公司使用数据仓库和数据湖。 什么是数据库?数据库是存储结构化数据的存储位置。我们通常会想到计算机上的数据库——保存数据,可以通过多种方式轻.
Qihoo360/XLearning:奇虎的基于Hadoop 人工智能项目
XLearning是一个结合大数据和人工智能的便捷高效的调度平台,支持多种机器学习、深度学习框架。XLearning 在 Hadoop Yarn 上运行,并集成了 TensorFlow、MXNet、C.
Apache Hadoop Yarn与Kubernetes比较选择 - codehunter

Kubernetes用于将 Docker 容器内核扩展为一个平台。Kubernetes 开发采用自下而上的方法。它在指定每个容器/pod 资源需求方面有很好的优化,但它缺乏一个有效的全局调度程序,可以.
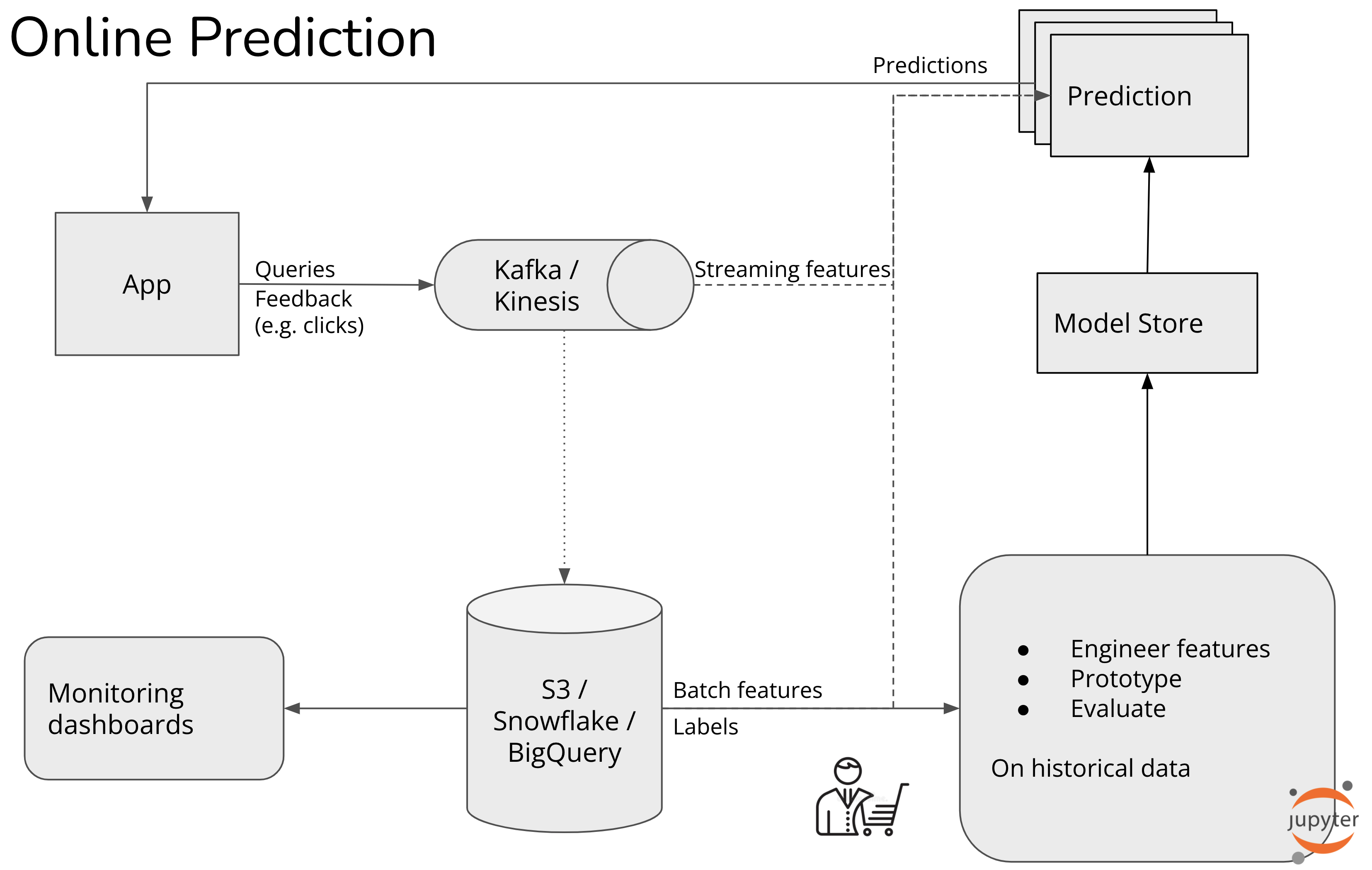
如何实现实时机器学习? - huyenchip
云计算是否会扼杀了Hadoop?
Hadoop 数据分析市场的大玩家继续在快速发展的市场中遭遇逆风,现在包括来自亚马逊网络服务和顶级主要云提供商的竞争,这些云提供商为企业提供管理和分析他们正在生成的大量数据的服务。Cloudera 和.
SeaTunnel用于海量数据的同步和转换

SeaTunnel 是一个分布式、高性能的数据集成平台,用于海量数据(离线和实时)的同步和转换。SeaTunnel 原名 Waterdrop,2021 年 10 月 12 日起更名为 SeaTunne.
Apache Sqoop与Apache Flume比较
选择 ETL 解决方案的目标是确保数据以符合分析要求的速率进入 Hadoop,以及顶级 Hadoop 数据摄取工具, 如Apache Kafka、Apache NIFI (Hortonworks Da.
Hadoop领域12家顶级公司 - BDAN
Hadoop是由 Apache 软件基金会开发的平台,是一种流行的开源大数据平台,用于跨计算机集群对大型数据集进行分布式处理。Apache Hadoop 中的每个系统都充当存储设备和计算平台。它是开发.
数据湖+数据仓库 = 数据湖库架构

传统OLAP和OLTP是分离,数据是从业务数据存储库中提取,然后将其存储在数据湖中,下一步就是进行ETL数据提取转换和分析,然后,将这些数据的关键子集转移到数据仓库中,以生成用于决策的业务洞察力。这样.
Airflow替代方案:Prefect和Dagster比较
深入了解 Airflow、Prefect 和 Dagster 以及三者之间的区别!互操作性目前还是现代数据技术的棘手的问题:数据管道仍然涉及不完全适合 ETL 工作流的自定义脚本和逻辑。无论是自定义内.
用于Hadoop的MongoDB连接器库

用于 Hadoop 的 MongoDB 连接器是一个库,它允许将 MongoDB(或其数据格式的备份文件,BSON)用作 Hadoop MapReduce 任务的输入源或输出目标。它旨在提供更大的灵活.
简单比较 Apache Kafka 和 Apache Pulsar要点 - Jaroslaw
Apache Pulsar 是一个开源的分布式发布-订阅消息系统,与kaffka根本不同的是持久性存储。在 Kafka 中,日志保存在代理上,而 Pulsar 使用Apache BookKeeper,.
ETL专业人员应该学习Hadoop的5个理由
作为提取、转换和加载 (ETL) 处理的临时平台,Hadoop 在数据仓库中的重要性正在迅速发展。提到 ETL,Hadoop 被视为数据准备和转换的逻辑平台,因为它允许他们完美地管理大量、多样性和速度.