Hadoop大数据教程
2022年数据工程现状

数据工程的所有最新工具和趋势:数据摄取该层包括提供从操作系统到数据存储的管道的流技术和 SaaS 服务。这里值得一提的演变是Airbyte的急剧崛起。Airbyte 成立于 2020 年,直到当年年底.
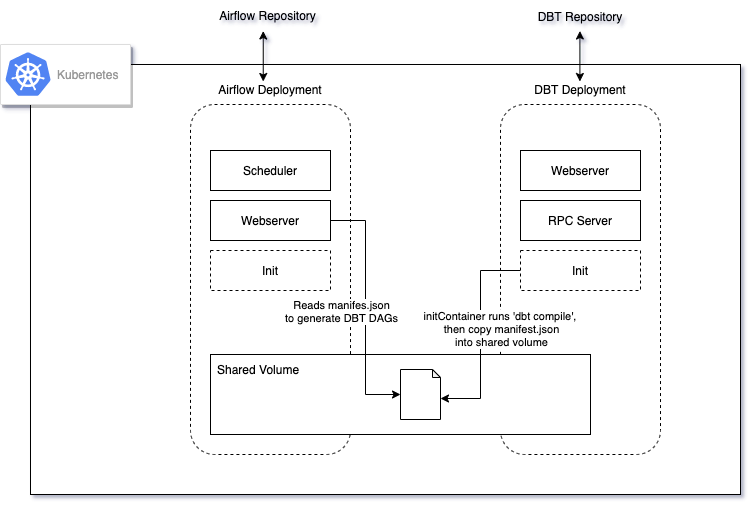
DBT、Airflow 和 Kubernetes的架构演进 - yan
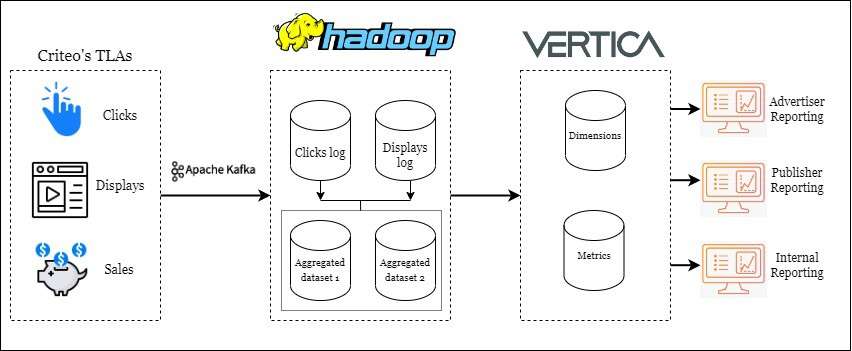
Criteo在大规模数据工程优化上经验 - Nam
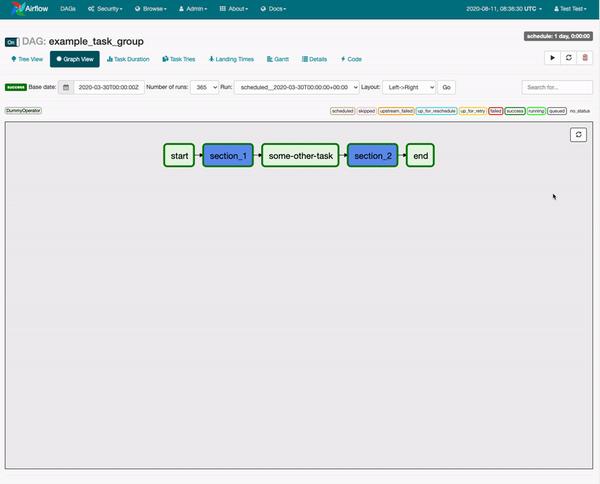
Apache Airflow的10条最佳实践

最初,Airflow 有点像“超级 cron”,因此运行作业的方式与框架本身高度耦合。今天,您必须克服的最大挑战是消除调度和作业之间的耦合。1)Airflow是一个编排框架,而不是一个执行框架:对于您.
大数据编排引擎历史回顾 - Ananth

我在 Hadoop/Bigdata 的早期阶段开始研究数据管道,当时大数据是一个流行词。Apache Oozie (有人还记得 Oozie 吗?)是一种用于编排数据管道的首选工具,您必须在 XML 文.
你应该使用 Apache Airflow 吗?
danthelion/trino-minio-iceberg-example:使用Minio、Trino、iceberg搭建数据工程演示案例

这个项目演示了使用Minio、Trino(具有众多连接器)等工具通过 Docker 在我们的机器上部署 MVP 版本来运行一些分析查询.数据湖“Data Lakehouse”一词是由 Databric.
亚马逊 Redshift 死了吗?

AWS Redshift 是最早的云数据仓库之一,可以说是 Hadoop 之后的一代。Amazon Redshift 是云中完全托管的 PB 级数据仓库服务。该服务适用于小至几百 GB 的数据量,并且.
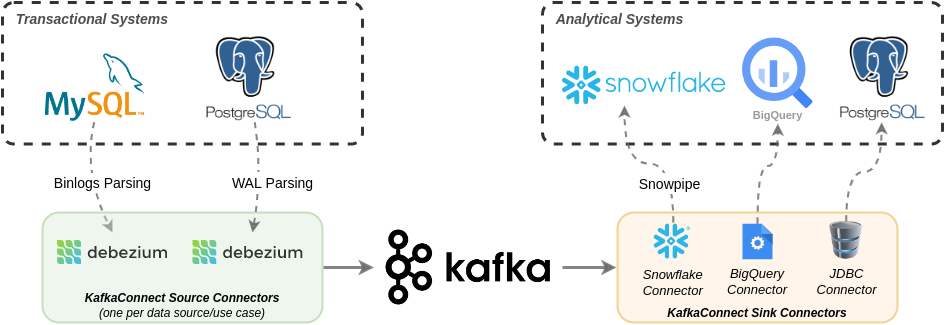
从Debezium到Snowflake在生产中构建数据复制的经验教训 - Shippeo
tokio_sky: 使用Rust+Tokio实现并发和多阶段数据摄取和数据处理

TokioSky 是一个流处理框架,用于构建并发和多阶段数据摄取和流处理,通过 Rust+Tokio 构建并发和多阶段数据摄取和数据处理管道。,TokioSky 让开发者可以高效地使用数据,有效地使用.
2022 年数据工程现状 - LakeFS

我们在过去一年看到的主要主题是整合。1、数据摄取该层包括提供从操作系统到数据存储的管道的流技术和 SaaS 服务。这里值得一提的演变是Airbyte的急剧崛起。Airbyte 成立于 2020 年,直.
数据湖表格式比较(Iceberg、Hudi 和 Delta Lake)
表格格式是数据工具和语言与数据湖进行交互的方式,就像我们与数据库进行交互一样。表格格式允许我们将不同的数据文件抽象为一个单一的数据集,一个表格。数据湖中的数据通常可以跨越多个文件。我们可以使用 Spa.
LinkedIn大数据工程的升级

在 LinkedIn 的早期阶段(2010 年代初),公司发展非常迅速。为了跟上这种增长,他们在分析堆栈中利用了几个第三方专有平台。使用这些专有平台比拼凑现成的产品要快得多。LinkedIn 依靠 I.
数据库会演变成分布式计算平台吗? - Nikita

“数据库”一词是否会在 5 到 10 年内慢慢演变成“分布式计算平台”?随着无服务器市场的扩大,更多的数据库解决方案开始考虑模块化架构,其中系统的各个组件都是分开的。这允许为每个无服务器租户分配此类组.
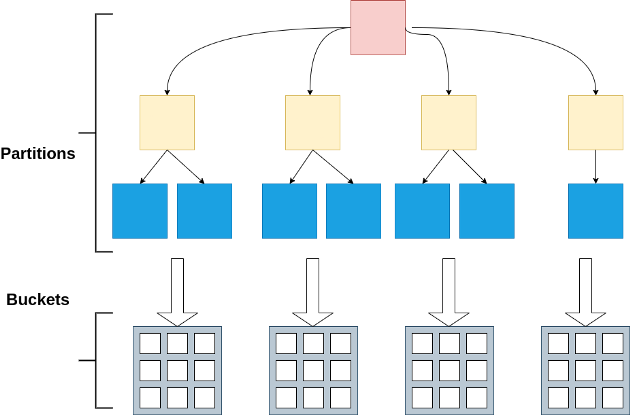
Apache Spark:分区和分桶 - Nivedita
Blaze:基于Rust加速器用更少资源加速Spark作业
超快的查询执行引擎使用 Apache Spark 语言,并以 Arrow-DataFusion 为核心。Apache Spark 的 Blaze 加速器利用本机矢量化执行来加速查询处理。它结合了Apa.
在Docker容器中使用Hadoop执行Python MapReduce作业

在 Apple Silicon Mac 上的 Docker 容器中使用 Hadoop 执行 Python MapReduce 作业。开始时需要的步骤是。安装 Apple Silicon的docker桌.
MLOps是过度工程吗?- Reddit

数据工程比 DS数据科学 更受欢迎。不幸的是,ML(过度)工程是造成这种情况的一个原因。以前可以使用 crontab 和 15 行 shell 自动化模型;而现在,你需要在你的 XGBoost 模型后.
通过调度和预取提高 Hadoop 性能

在本文中,我们继续研究如何提高Hadoop的性能,如何解决数据访问模式、集群内存和有效调度方面的数据定位问题。在Hadoop集群中,用户通常根据他们的业务需求来访问数据,这使得一些数据比其他数据更容易.
Lyft如何存储支持其ML模型的大规模特征数据?
机器学习是 Lyft 应用程序的支柱,Lyft 的 Feature Serving 服务负责为这些 ML 模型提供特征数据。 Lyft 如何使用 Flyte 和 Apache Flink 存储特征定义.
深入了解Python的Dask分布式调度程序 - selectfrom

Dask 是一个强大的 Python 库,可让您使用一个代码将数据工程从一台机器扩展到多台机器,并具有 Python 的可扩展性。这种分布式电源的核心是 Dask 分布式调度程序。从本质上讲,Dask.
命令行工具可以比Hadoop集群快235倍 - Adam Drake

当我在浏览网页和赶上一些我定期访问的网站时,我发现了一篇来自Tom Hayden的很酷的文章,关于使用亚马逊弹性Map Reduce(EMR)和mrjob来计算他从millionbase档案馆下载的国.
Spark和Hadoop之间的主要技术差异和选择
Hadoop 和 Spark 都是开源软件的集合,由 Apache 软件基金会维护,用于大规模数据处理。Hadoop 是两者中较老的一个,曾经是处理大数据的首选。然而,自从 Spark 推出以来,它的.
每个开发者都应该使用的VSCode插件 - tvkoushik
Material Icon:程序员处理大量不同类型和扩展名的文件,随着代码库的增长,识别这些文件变得很麻烦。Material Icon 主题 VSCode 扩展使文件图标的颜色更加鲜艳,并且可以轻松地.
如何实施数据网格? - thenewstack
数据网格克服了由数据湖和数据仓库设计引起的限制和减速,而是以分散的点对点方式连接数据 - 将其网格化。该想法由 Thoughtworks 新兴技术总监 Zhamak Dehghani 提出,并建立在四.
Hive性能调优实践 - Vidhya
Apache Hive 是一个建立在 Hadoop 之上的数据仓库系统,它使用户能够灵活地以类似 SQL 的查询的形式编写复杂的 MapReduce 程序。性能调优是运行 Hive 查询的重要部分,因.
如何面对后Hadoop时代?

Apache Hadoop作为一个完整的开源大数据套件,在过去十年深刻影响了整个大数据世界。然而,随着各种新兴技术的发展,Hadoop生态系统发生了翻天覆地的变化。2021 年 4 月,Apache .
吴恩达:以数据为中心的人工智能?
吴恩达在 2000 年代后期,率先使用图形处理单元 (GPU) 与斯坦福大学的学生一起训练深度学习模型,并于 2011 年共同创立了Google Brain ,然后在百度担任了三年的首席科学家,在那里.
数据湖中加热数据?
数据湖:通过一个用于大数据分析的存储库来结束数据孤岛。想象一下,有一个单一的地方来存放您的所有数据以进行分析,以支持以产品为主导的增长和业务洞察力。可悲的是,数据湖的想法一度冷落,因为早期的尝试是建立.
Windows 10下Hadoop 3.2.2 安装指南
首先,你需要安装 Java,因为 Hadoop 是基于它的。然后,您需要下载并配置 Hadoop 文件系统本身。另外,我建议你安装WinRAR,因为你需要解压一些文件。 Java 安装和配置Java .