Hadoop大数据教程
2022年数据工程现状

数据工程的所有最新工具和趋势:数据摄取该层包括提供从操作系统到数据存储的管道的流技术和 SaaS 服务。这里值得一提的演变是Airbyte的急剧崛起。Airbyte 成立于 2020 年,直到当年年底.
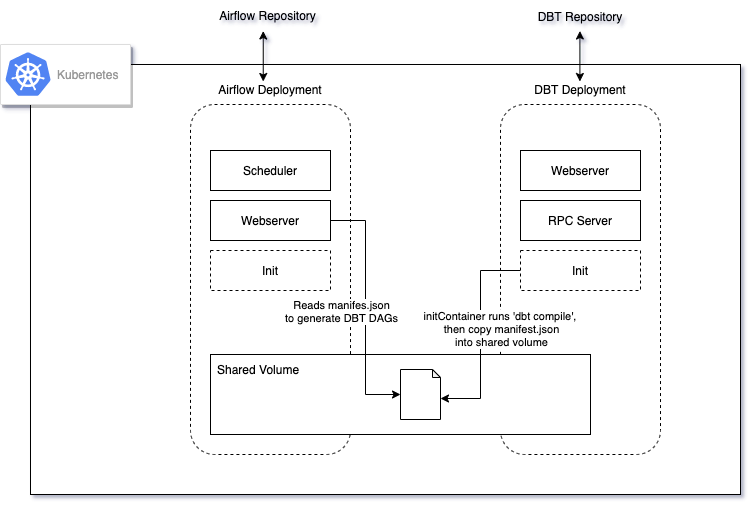
DBT、Airflow 和 Kubernetes的架构演进 - yan
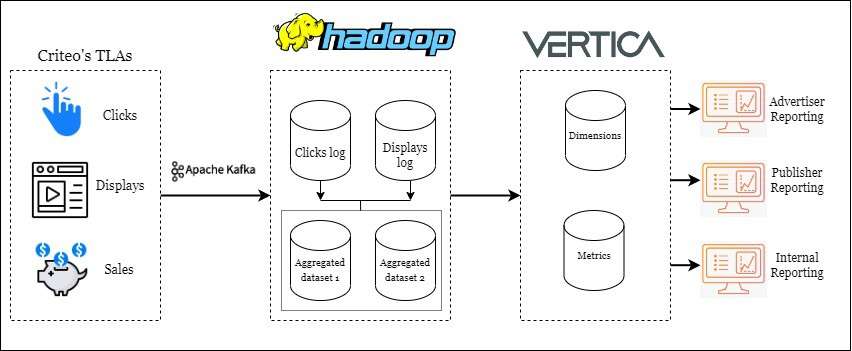
Criteo在大规模数据工程优化上经验 - Nam
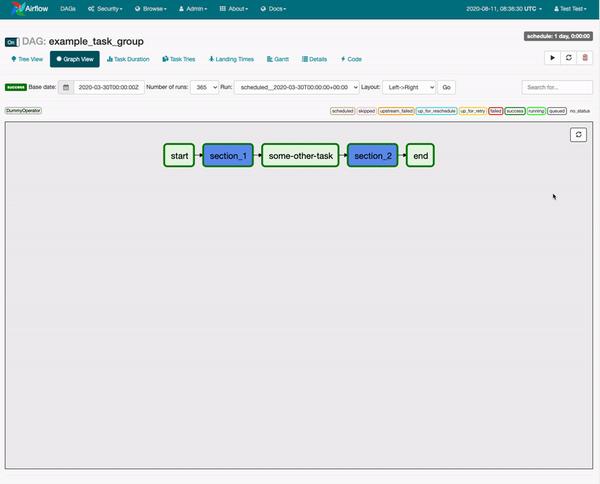
Apache Airflow的10条最佳实践

最初,Airflow 有点像“超级 cron”,因此运行作业的方式与框架本身高度耦合。今天,您必须克服的最大挑战是消除调度和作业之间的耦合。1)Airflow是一个编排框架,而不是一个执行框架:对于您.
大数据编排引擎历史回顾 - Ananth

我在 Hadoop/Bigdata 的早期阶段开始研究数据管道,当时大数据是一个流行词。Apache Oozie (有人还记得 Oozie 吗?)是一种用于编排数据管道的首选工具,您必须在 XML 文.
你应该使用 Apache Airflow 吗?
danthelion/trino-minio-iceberg-example:使用Minio、Trino、iceberg搭建数据工程演示案例

这个项目演示了使用Minio、Trino(具有众多连接器)等工具通过 Docker 在我们的机器上部署 MVP 版本来运行一些分析查询.数据湖“Data Lakehouse”一词是由 Databric.
亚马逊 Redshift 死了吗?

AWS Redshift 是最早的云数据仓库之一,可以说是 Hadoop 之后的一代。Amazon Redshift 是云中完全托管的 PB 级数据仓库服务。该服务适用于小至几百 GB 的数据量,并且.
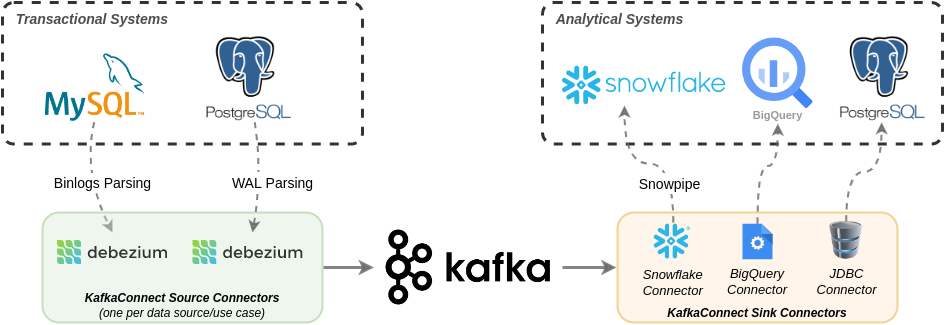
从Debezium到Snowflake在生产中构建数据复制的经验教训 - Shippeo
tokio_sky: 使用Rust+Tokio实现并发和多阶段数据摄取和数据处理

TokioSky 是一个流处理框架,用于构建并发和多阶段数据摄取和流处理,通过 Rust+Tokio 构建并发和多阶段数据摄取和数据处理管道。,TokioSky 让开发者可以高效地使用数据,有效地使用.
2022 年数据工程现状 - LakeFS

我们在过去一年看到的主要主题是整合。1、数据摄取该层包括提供从操作系统到数据存储的管道的流技术和 SaaS 服务。这里值得一提的演变是Airbyte的急剧崛起。Airbyte 成立于 2020 年,直.
数据湖表格式比较(Iceberg、Hudi 和 Delta Lake)
表格格式是数据工具和语言与数据湖进行交互的方式,就像我们与数据库进行交互一样。表格格式允许我们将不同的数据文件抽象为一个单一的数据集,一个表格。数据湖中的数据通常可以跨越多个文件。我们可以使用 Spa.
LinkedIn大数据工程的升级

在 LinkedIn 的早期阶段(2010 年代初),公司发展非常迅速。为了跟上这种增长,他们在分析堆栈中利用了几个第三方专有平台。使用这些专有平台比拼凑现成的产品要快得多。LinkedIn 依靠 I.
数据库会演变成分布式计算平台吗? - Nikita

“数据库”一词是否会在 5 到 10 年内慢慢演变成“分布式计算平台”?随着无服务器市场的扩大,更多的数据库解决方案开始考虑模块化架构,其中系统的各个组件都是分开的。这允许为每个无服务器租户分配此类组.
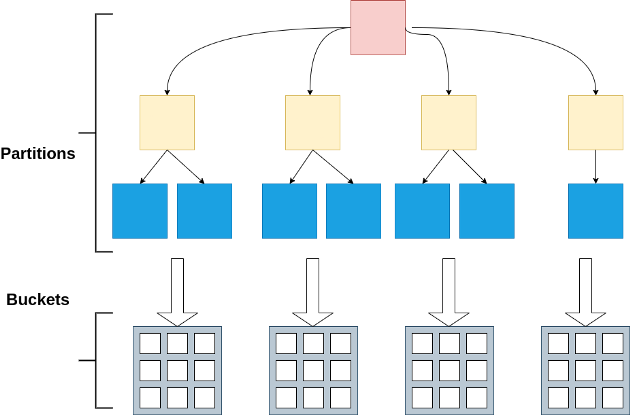
Apache Spark:分区和分桶 - Nivedita