ApacheSpark大数据教程
-
Spring Boot中集成机器学习简介
23 5K
如今,机器学习提供了创新的解决方案和更好的用户体验。在动态的软件开发领域,利用机器学习的力量对于创建智能和自适应应用程序至关重要。Spring Boot 以其简单性和高效性而闻名,为构建强大的企业应用.
-
比较 Pandas、Polars 和 PySpark:基准分析
66 2K
比较 Pandas、Polars 和 PySpark 三种工具的不同数据集,得出数据处理未来发展方向的结论。PandasPandas 一直是数据操作、探索和分析的主要工具。由于 Pandas 与 R .
-
Python中读写Parquet文件的方法
60 8K
Apache Parquet 文件是数据科学家和任何使用 Hadoop 生态系统的人所使用的流行列式存储格式。它的开发在压缩和编码方面非常高效。您可以使用pyarrow 包通过 Python 读取和写.
-
Java中大数据生态和4个工具介绍
63 2K
大数据 和 Java 形成强大的协同作用。大数据以其高 容量、 高速度和 多样性为特征,已成为各行业的游戏规则改变者。什么是大数据?使用传统数据处理技术难以处理和处理的异常大的数据集被称为“大数据”。.
-
PySpark DataFrame教程与演示
61 5K
PySpark DataFrame 是 PySpark 库中的基本抽象,专为分配的记录处理和操作而设计。它是 Apache Spark 生态系统的重要组成部分,提供了一种强大且绿色的方式来大规模处理结.
-
2024年20大数据科学工具
97 5K
企业数据变得越来越具有挑战性,并且由于它在战略规划和决策中发挥着关键作用,组织被迫在从数据资产中提取有用的业务洞察所需的人员、程序和技术上投入资金。当我们深入研究 2024 年时,数据科学工具的前景已.
-
Apache Spark:释放大数据力量
85
Apache Spark是一个强大的开源分布式计算系统,已成为大数据处理领域的基石。凭借其多功能的特性和强大的功能,Spark 已成为处理海量数据集的组织的首选解决方案。让我们探讨一下它的主要特性、优.
-
简单介绍Iceberg与数据湖屋由来
123 2K
本文从数据存储格式的演变介绍了数据工程领域的大数据处理框架发展,从Hive到Iceberg、Delta Lake以及数据湖屋的发展过程:数据如何存储(在文件和内存中)开源文件格式(如Avro、Parq.
-
Taipy:将数据和人工智能算法转变为可投入生产的 Web 应用
332 16K
Taipy 是一个开源 Python 库,用于构建 Web 应用程序前端和后端。立即将数据和 AI 算法转化为可投入生产的 Web 应用程序。将 PySpark 与 Taipy 结合使用Taipy 是.
-
2023年游戏数据流的状况
116
这篇博文探讨了 2023 年游戏行业的数据流状态。包括来自 Kakao Games、Mobile Premier League (MLP)、Demonware / Blizzard 等的客户案例。休闲.
-
可组合数据系统之路:对过去15年和未来的思考
438 6K
来自韦斯·麦金尼文章:15年前,也就是2008年4月,我开始构建数据分析工具。我当时所感知到的是数据科学的迫切“Python化”。这不仅是为了让新一代的数据从业者更容易获得数据科学,也是为了让现有的数.
-
Apache Flink 是实时流处理的行业标准
509
在 Decodable,我们长期以来一直认为Apache Flink是最好的流处理系统,在满足世界上一些最大和最复杂的企业(如 Netflix、Uber、Stripe 等)的需求方面有着良好的记录。未.
-
揭密Tweepcred:Twitter推荐引擎背后的力量
621 6K
您已经在 Twitter 上看到一些人具有某种影响力,他们的推文以近乎神奇的效率获得点赞、转发和回复。但是你有没有想过这种影响力是什么?今天,我们将深入 Tweepcred 的神秘世界,这是计算用户在.
-
数据帧比较:Polars vs. Spark vs. Pandas vs. DataFusion性能对比
1783
在 Spark 真正成为主流之前,数据科学家仍在大量使用 Pandas。现在每个人都想要一块 DataFrame 蛋糕!GitHub 上提供测试代码。我不会深入探讨这些工具中的每一个,除了一些Rust.
-
Druid:实时分析数据存储
1542 4K
Apache Druid是一个开源数据库,专为低延迟的近实时和历史数据分析而设计,Druid 被Netflix、Confluent和Lyft等公司用于各种不同的用例。这个领域有Clickhouse、t.
-
Snowflake和Databricks比较 - John
1598 2K
应该选择 Snowflake 还是 Databricks?Snowflake 和 Databricks 都是很棒的组织。他们发明或重新发明了数据管理行业。我不会贬低他们的任何技术、人员或流程。然而,他.
-
使用 Spark 优化加速大数据处理 - Gaurav
1068 7K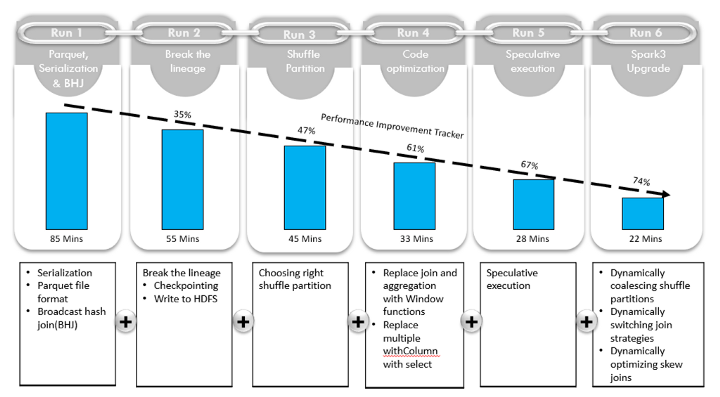 Apache Spark 是领先的开源数据处理引擎,用于批处理、机器学习、流处理和大规模 SQL(结构化查询语言)。它旨在使大数据处理更快、更容易。自诞生以来,Spark 作为一个大数据处理框架获得了.
Apache Spark 是领先的开源数据处理引擎,用于批处理、机器学习、流处理和大规模 SQL(结构化查询语言)。它旨在使大数据处理更快、更容易。自诞生以来,Spark 作为一个大数据处理框架获得了. -
Apache Iceber能将Amazon S3 成本降低了 90%
1353 3K
与Apache Hive相比,新一代数据湖表格式(Apache Hudi、Apache Iceberg和Delta Lake)凭借其卓越的功能每天都在受到越来越多的关注。它们为具有 ACID 事务、模.
-
在 Data Lakehouse 中统一批处理和流处理
705 3K
最近,我们在 ALTEN 的一位客户表示希望开始从他们的操作系统中提取和集中数据。从分析的角度来看,他们的信息环境处于未开发状态。这为创建集中式分析平台留下了许多架构选项。我们对数据处理的主要要求包括.
-
批处理中的数据质量如何保证? - Weingarten
1187
下面是我在尼尔森工作时的实现,这在 Airflow 中使用 Soda 来实施数据质量检查的博客类似。当我在尼尔森时,还没有一个数据质量的总体框架或平台,所以我们“开发”的只是内部供我们自己使用。我们决.
-
Claimforce为何使用湖仓统一数据湖和数据仓库?
1381 3K
在 Claimforce,我们最初的大数据方法是一个两层架构,包括 Amazon S3 中的数据湖阶段和 Amazon Redshift 中的数据仓库阶段(此处概述)。随着时间的推移,我们意识到拥有两.
-
数据摄取的 7 个最佳实践
1202 3K
“数据工程是 2022 年最性感的新工作”它在需求和职业机会方面已经超过了数据科学。如果您还没有看到对数据工程的需求呈天文数字增长,那么您很可能在过去 2 年都生活在山洞里。到底是什么炒作?为了试图回.
-
Eats数据平台:用数据赋能企业
1465 4K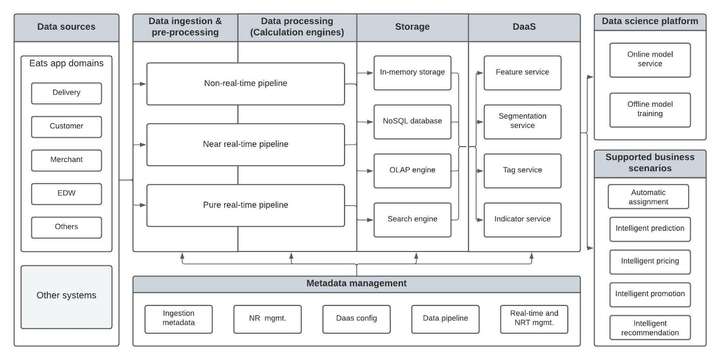 在线食品订购和配送是一个竞争激烈的市场,速度是生存的关键。Coupang Eats(简称Eats)是韩国电商巨头Coupang的外卖子公司。在这篇文章中,我们将详细介绍 Eats 数据平台团队如何构建.
在线食品订购和配送是一个竞争激烈的市场,速度是生存的关键。Coupang Eats(简称Eats)是韩国电商巨头Coupang的外卖子公司。在这篇文章中,我们将详细介绍 Eats 数据平台团队如何构建. -
Velox 简介:数据平台统一执行引擎
3243 4K
Meta 撰写了有关 Velox 的文章,这是其用于数据工作负载的开源统一执行引擎。该项目是一个令人兴奋的项目它正在远离默认的基于 JVM 的执行引擎,带有 Spark 和 Presto,但提供了完整.
-
沃尔玛如何使用 Apache Hudi 和 Spark 实现 SCD-2(渐变维度)?
884 1
数据是当今分析世界的宝贵资产。在向最终用户提供数据时,跟踪数据在一段时间内的变化非常重要。渐变维度 (SCD) 是随时间推移存储和管理当前和历史数据的维度。在 SCD 的类型中,我们将特别关注类型 2.
-
SPL: 专门处理开放格式文件 (txt/csv/json/xml/xls)的Java库
1196
在 Java 应用程序中处理 txt、csv、json、xml 和 xls 等开放格式的数据文件是很常见的。Java 中的硬编码非常复杂,因此我们经常求助于某些现成的开源包。但每个包都有其弱点。解析库.
-
DataBathing:将查询传输到 Spark 代码的框架
843
DataBathing可以将 SQL 解析为 JSON,以便我们可以将其转换为其他数据存储!沃尔玛团队已经成功地从 Hive SQL 驱动转变为数据工程的代码驱动。我们每天都在使用 Spark(Sca.
-
Iceberg+Spark+Trino+Dagster大数据分析开源技术栈 | by ZD
1552 7K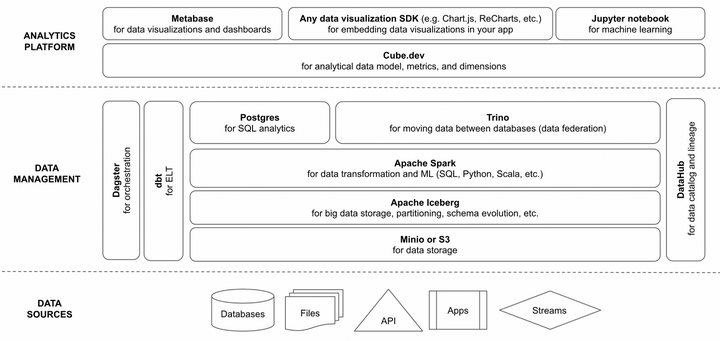 两个月前我组装了ngods(新一代开源数据堆栈),并从那时起将它用于我的朋友的两个项目。这个堆栈可以很好地从小数据(几 GB)扩展到中型数据(几百 GB)。它也比使用基于使用定价的类似云组件(例如,S.
两个月前我组装了ngods(新一代开源数据堆栈),并从那时起将它用于我的朋友的两个项目。这个堆栈可以很好地从小数据(几 GB)扩展到中型数据(几百 GB)。它也比使用基于使用定价的类似云组件(例如,S. -
JSLLightNLP:使用Spring和LightPipelines为Spark NLP实现API服务的项目
1081
Spark NLP是一个构建在 Apache Spark 之上的自然语言理解库,利用 Spark MLLib 管道,允许您大规模运行 NLP 模型,包括 SOTA Transformers。因此,它是.
-
2022 年数据工程现状 - LakeFS
2069 7K
我们在过去一年看到的主要主题是整合。1、数据摄取该层包括提供从操作系统到数据存储的管道的流技术和 SaaS 服务。这里值得一提的演变是Airbyte的急剧崛起。Airbyte 成立于 2020 年,直.