ApacheSpark大数据教程
Spark流教程 :使用 Apache Spark 的Twitter情绪分析
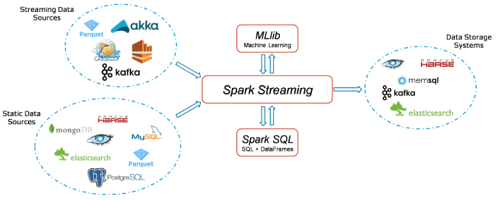
机器学习库Spark MLlib简介与教程

Spark MLlib是 Apache Spark 的机器学习组件。 Spark 的主要吸引力之一是能够大规模扩展计算,而这正是机器学习算法所需要的。但局限性是所有机器学习算法都无法有效并行化。每个算.
Spark GraphX简介与教程
BDA:Hadoop生态大数据工具的漏洞扫描器

BDA 是 Hadoop 和 Spark 等大数据工具的漏洞扫描器。它搜索配置弱点并报告它们。Hadoop 和 Spark 是少数遇到大量数据的应用程序之一。因此,通过保护这些应用程序,可以实现巨大的.
Hadoop YARN 架构

Hadoop YARN代表又一个资源管理器,随着 Hadoop 2.x 的出现,YARN 成为 Hadoop 生态系统的一部分,YARN 管理集群环境中的资源,在 Hadoop 2.x 之前我们没有任.
使用 PySpark 创建新列的 4 种不同方式 - Soner

了解如何在 Spark 数据框中创建新列?我们生活在大数据时代。收集、存储和传输数据变得非常容易。随着数据量的增加,传统的工具开始变得不够用。当数据太大而无法通过传统工具和技术进行处理时,我们应该使用.
关于Delta Lake的ACID事务机制简介
近年来,随着大数据利用用例的多样化,需要为分布式存储添加更多功能。这几年诞生了几款OSS存储层SW,可以原样使用HDFS等分布式存储和Apache Spark等分布式处理框架,为分布式存储添加新功能。.
机器学习项目 - 使用 Apache Spark 创建电影推荐引擎

在这个项目中,我们将为每个用户生成前 10 名电影推荐,并为每部电影生成前 10 名用户推荐。无论年龄、性别、种族、肤色或地理位置如何,每个人都喜欢电影。推荐系统是一个过滤程序,其主要目标是预测用户对.
在 Apache Spark 中使用机器学习进行客户细分

在这个项目中,我们将执行机器学习最重要的应用之一——客户细分。无论何时您需要找到最佳客户,我们都会在 Apache Spark 和 Scala 中实施客户细分。客户细分是将公司的客户划分为反映每组客户.
ML与BI结合的产品:Tellius
AI 和 BI 的世界在分析连续体中占据不同的位置,最常通过描述性分析、预测性分析和规范性分析等概念来理解:用户可以利用描述性分析和 BI 工具来探索过去发生的事情;而预测分析则利用在现实世界数据上训.
Apache Spark、Hadoop和Zookeeper因使用Log4j 1.x被列为未受CVE-2021-44228影响?

在这次Log4Shell或log4j2 CVE-2021-44228漏洞事件中,Apache Spark、Hadoop和Zookeeper被列为不受影响,因为它们使用 Log4j 1.x。Log4j .
tomaztk/Spark-for-data-engineers:面向数据工程师的Apache Spark学习教程
Spark for data Engineers 是一个Github存储库(点击标题),将为读者提供概述、代码示例和示例,以更好地处理 Spark。数据分析师、数据科学家、商业智能分析师和许多其他角色.
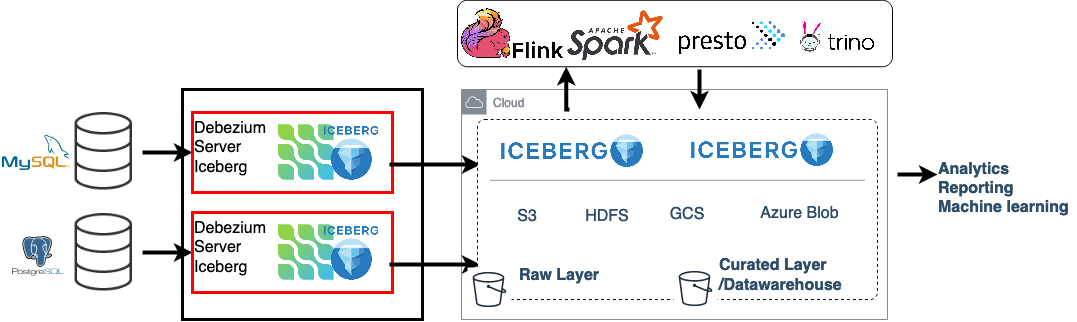
使用 Debezium 和 Apache Iceberg 创建数据湖
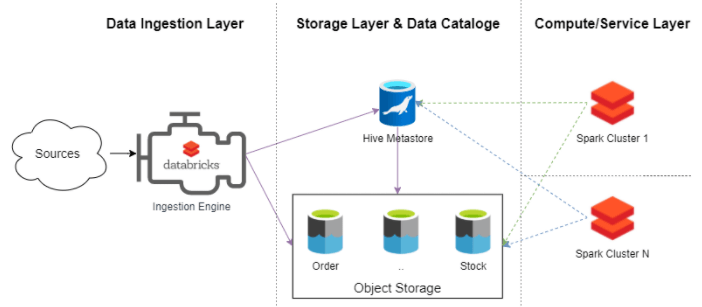
以Kafka事件中心+Spark为核心构建新一代数据湖平台 - DZone
Apache Spark:数据框,数据集和RDD之间的区别 - Baeldung

Apache Spark是一个快速的分布式数据处理系统。它执行内存中的数据处理,并使用内存中的缓存和优化的执行,从而实现快速性能。它为流行的编程语言(例如Scala,Python,Java和R)提供了.