中台数据工程教程
为什么在 Python 中使用 Pandas?

Pandas 通常以其标志性的黑白熊标志为标志,是 Python 数据分析生态系统中最受欢迎的库之一。自诞生以来,它从根本上改变了 Python 中数据操作和分析的格局。但为什么它获得了如此巨大的人气.
Netflix 使用Psyberg简化数据工程

在 Netflix,我们的会员和财务数据工程团队利用与计划、定价、会员生命周期和收入相关的各种数据来推动分析、为各种仪表板提供支持并做出基于数据的决策。Netflix 财务报告中的许多指标均由我们团队.
矢量包处理(VPP)比传统内核方法快 100 倍

矢量包处理 (VPP) 是一种开源软件,可以通过批处理数据包和使用 SIMD 指令等技术在商用硬件上提高吞吐量。矢量包处理 (VPP) 是一种在软件中高速处理数据包的技术。它将数据包处理从内核移到用户.
Manticore Search:可替代Elasticsearch的开源搜索项目

Manticore Search 是一个易于使用的开源快速搜索数据库。Elasticsearch 的良好替代方案。它与其他解决方案的区别在于: 它速度非常快,因此比其他替代方案更具成本效益,例如 Ma.
Debezium会丢失事件吗?

是否存在这样的情况:数据库中的记录被插入、更新或删除,但 Debezium 无法从事务日志中捕获该事件并将其传播到下游消费者?一般来说,Debezium 本身绝不会错过任何事件。如果确实如此,则被认为.
您的数据库技能并不“值得拥有”?

2006 年,《纽约杂志》数字团队开始为其时装周门户网站打造全新的搜索体验。这是一个甚至没有与技术团队讨论过技术可行性的项目,这在当时很常见。敏捷技术尚属新生事物,更不用说在出版业了。这只是一个愿景,.
Salesforce中企业数据架构的设计原则

企业的运营依赖于数据——最好的组织都拥有强大的数据战略。Salesforce中的企业数据架构是:用于指导 Salesforce 组织中的数据管理的核心设计原则和框架。它可以帮助您确定数据的存储位置、数.
数据工程中九大痛点

1、业务领域与数据工程脱节:业务中没有人愿意掌握数据的所有权,包括数据的生成方式、业务规则是什么等。2、上游分析师是否负责 QA?常见的工作流程是分析师试图解决问题,遇到数据质量问题,然后无法证明或证.
Uber使用Apache Pinot实时分析移动app的崩溃

在 Uber,我们构建了一个名为“Healthline”的系统,以帮助解决平均检测时间 ( MTTD ) 和平均解决时间 ( MTTR ) 问题,并避免潜在的中断和大规模用户影响。由于我们能够实时检测.
使用Go构建一个Postgres流平台
使用 Go 通道从拉推模型转向更高效的流方法。这通过重叠拉取和推送阶段来提高性能,减少总体处理时间和延迟。Go通道提供数据同步、资源管理和并发处理。它们允许 goroutine 安全地通信和交换数据。.
变更数据捕获 (CDC) 的七种使用方法
变更数据捕获 (CDC) 是数据工程中的强大工具,在过去几年中在各种组织中得到了巨大的应用。这是因为它能够以非常低的延迟将事务数据库紧密集成到您企业中的许多其他系统中。CDC 对事务数据库中发生的更改.
利用快速C++数据处理的Python API

ArcticDB 是一个为 Python 数据科学生态系统构建的高性能、无服务器 DataFrame 数据库。ArcticDB by Man Group一个Python API,利用快速C++数据处理.
Scratch:BigQuery、Redshift和Snowflake开源替代品

ScratchDB 是 Clickhouse 的包装器,BigQuery、Redshift 和 Snowflake 的开源替代品。ScratchDB可让您输入任意 JSON 并对其执行分析查询。添加新.
使用 Apache Kafka 和 OpenTelemetry 最大化可扩展性
OpenTelemetry Collector 和 Apache Kafka 之间的选择不是零和游戏。每个都有其独特的优势,甚至可以在某些架构中相互补充。OpenTelemetry Collector.
什么是数据工程中的流处理?
数据流处理可分为三个不同的数据处理阶段: 收集 处理 呈现 让我们更详细地了解这三个阶段,并举例说明。步骤 1:收集数据要处理数据流,首先需要数据流!幸运的是,几乎所有数据都是以连续的方式产生的,将数.
20个SQL查询优化技巧
以下值得关注的 20个SQL查询优化技术列表: 1.在庞大的表(>1.000.000)行上创建索引 2.使用 EXIST() 代替 COUNT() 查找表中的元素 3.用 SELECT 字段代替 SE.
RDBM最佳实践
RDBMS 可以做的事情比大多数人想象的要多得多:1. 添加表通常比更改现有表更好在大公司中尤其如此。对其他团队依赖的核心表进行更改是非常危险的,并且可能需要经过许多批准。这会大大降低团队的敏捷性。取.
使用数据库实现状态机
大多数人都熟悉状态机并知道它们的价值。一般状态机库可以帮助您对状态进行建模,防止无效转换,并生成图表以帮助非技术人员理解代码的行为方式。本文并不是要阐述状态机的情况。这是关于如何采用状态机的概念并使其.
InfluxDB正式从Go切换到Rust
InfluxDB 是一个用 Rust 编写的开源时间序列数据库,使用 Apache Arrow、Apache Parquet 和 Apache DataFusion 作为基础构建模块。从Go切换到Ru.
可组合数据系统之路:对过去15年和未来的思考
来自韦斯·麦金尼文章:15年前,也就是2008年4月,我开始构建数据分析工具。我当时所感知到的是数据科学的迫切“Python化”。这不仅是为了让新一代的数据从业者更容易获得数据科学,也是为了让现有的数.
如何通过业务架构和IT架构提供价值?

企业架构需要足够的资源来规划和映射适当的客户驱动的业务架构,但IT架构的3个领域不应被忽视,即应用程序/服务、信息/数据和技术/基础设施。价值在业务架构中的重要性企业架构中的业务架构领域不仅仅涉及业务.
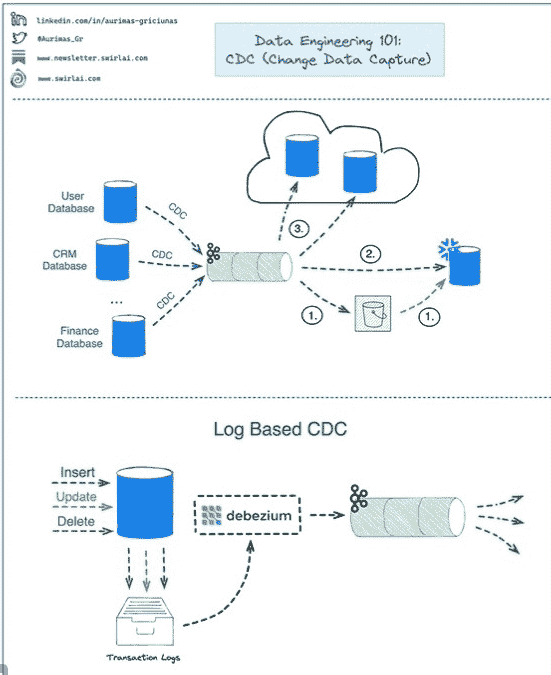
从数据库导出数据CDC的几种方式
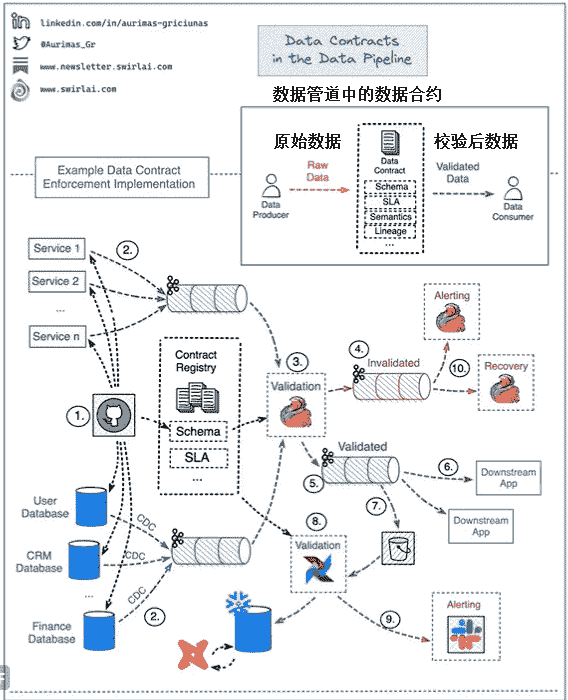
一张图解释数据合同如何实施
本周多篇机器学习用于推荐系统的大科技文摘
有选择地从科技公司的工程博客中挑选了博客文章:[Meta]扩展 Instagram Explore 推荐系统 讲述了一个关于使用先进机器学习模型(如两塔神经网络)使 Instagram 推荐更具可扩展.
七月大科技工程文摘

本文摘包含Airbnb优化数据访问、Etsy 实时广告个性化、Pinterest 时间序列数据工作、Wix 大迁移等!1、[Airbnb] Riverbed:以 Airbnb 的规模优化数据访问 概述.
6个Python日志记录库比较

虽然 Python 在其标准库中提供了强大且功能丰富的日志记录解决方案,但第三方日志记录生态系统提供了一系列引人注目的替代方案。根据您的要求,这些外部库可能更适合您的日志记录需求。因此,本文将考虑 P.
PostgreSQL和Oracle物化视图比较
对于最终用户来说,物化视图基本上只是一个表,物化视图只是将结果缓存在磁盘上,这样就不需要每次都运行底层查询。您可以使用类似的方法为分析师设置一些历史销售数据,他们不需要实时信息,只需要最近 5 年的销.
10个Postgres使用高级技巧
PostgreSQL不仅仅是另一个数据库,它是一个包含可以改变您处理数据方式的功能的系统。1、元组是行的物理版本PostgreSQL的基础之一是元组(tuple)的概念,这让许多新手感到惊讶。简单地说.
东南亚Grab如何降低Kafka流量成本?
Grab 是东南亚领先的超级应用平台,提供对消费者重要的日常服务。Grab 不仅仅是一款叫车和送餐应用程序,还在该地区提供广泛的按需服务,包括移动、食品、包裹和杂货配送服务、移动支付以及遍及 8 个国.
什么是向量数据库VectorDatabase?
随着基础模型的兴起,VectorDatabase(矢量数据库/向量数据库)的受欢迎程度直线上升。事实上,向量数据库在大型语言模型的上下文之外也很有用。当涉及到机器学习时,我们经常与向量嵌入打交道。向量.