中台数据工程教程
数据序列化工具比较:Avro vs Protobuf

两种流行的数据序列化系统是Google 的 Protocol Buffers (Protobuf)和Apache 的 Avro。虽然 Protobuf 和 Avro 都有各自的优点和缺点,但开发人.
MongoDB vs. PostgreSQL vs. ScyllaDB

工控系统如何为其实时机器学习环境选择最佳数据库?当谈论数据库时,人们会想到很多选项。然而,我们首先决定关注那些拥有最大社区和应用程序的人。这就留下了三个直接选择:两个市场巨头和一个令竞争对手感到惊讶的.
让Postgres快30%的方法

解决方案架构师25道面试题

在这里,在这篇文章中,我想为你提供一份关于解决方案架构师角色最常见的25个面试问题的指南!在这篇文章中,我将深入介绍成为一名解决方案架构师所需的条件,并对你在这个职位的面试中最有可能被问到的问题提供详.
Apache Doris是Elasticsearch + Grafana Loki优点的综合

理想的日志处理系统应该支持: 高吞吐量实时数据摄取:它应该能够批量写入博客,并使它们立即可见。 低成本存储:它应该能够存储大量的日志而不需要花费太多的资源。 实时文本搜索:它应该能够快速搜索文本。 业.
Apache Flink 是实时流处理的行业标准

在 Decodable,我们长期以来一直认为Apache Flink是最好的流处理系统,在满足世界上一些最大和最复杂的企业(如 Netflix、Uber、Stripe 等)的需求方面有着良好的记录。未.
SQL 二次兴起 - IEEE Spectrum
SQL 在今年IEEE Spectrum的顶级编程语言互动排名中占据主导地位。通常情况下,排名靠前的是 Python 或其他主流语言,例如 C、C++、Java 和 JavaScript,但是雇主多次.
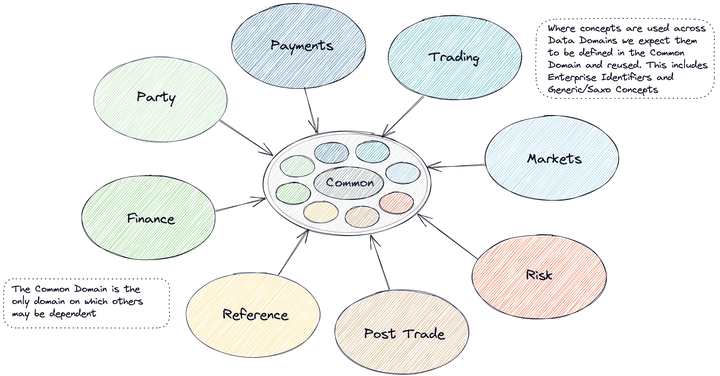
盛宝银行基于数据网格的分布式领域驱动架构最佳实践
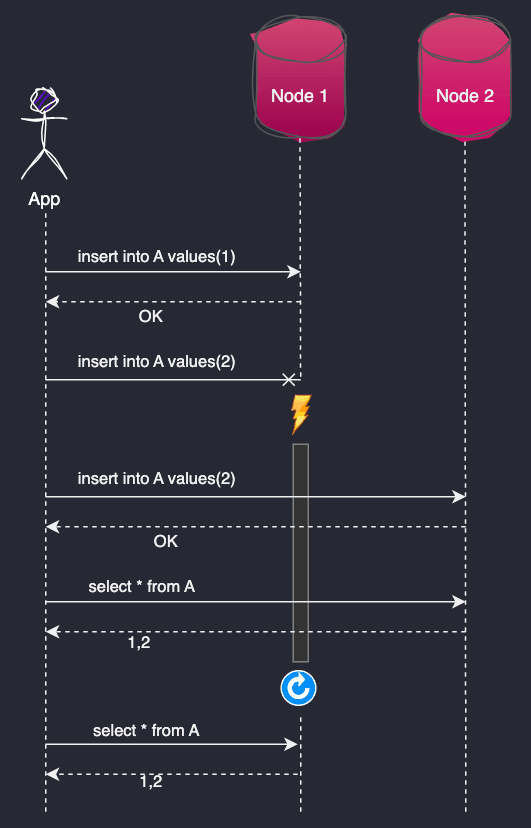
分布式数据库的内部工作原理
MotherDuck:大数据已死

十多年来,人们很难从他们的数据中获得可操作的洞察力,这一事实被归咎于其规模。诊断结果是 "你的数据对你那微不足道的系统来说太大了",而治疗方法是购买一些能够处理大规模的新的花哨的技术。当然,在大数据工.
pandas 2.0 新变化

Pandas 2.0来了!这是自Pandas诞生以来最大的一次大修,而且已经酝酿了多年。然而,你可能不会注意到太多的变化,你现有的Pandas代码很可能会像以前一样运行。所有的主要变化都在引擎盖下。这.
MLOps 主要是数据工程 - cpard

MLOps 作为管理数据基础设施的一类新工具出现,专门针对 ML 用例,主要假设是 ML 具有独特的需求。几年后,随着炒作消失,很明显,MLOps 与数据工程的重叠比大多数人认为的要多。让我们看看为什.
数据中台的数据建模

我们探讨了数据建模在数据工程中的重要性、数据建模的历史以及数据日益复杂的情况。我们还谈到了理解数据格局的重要性、其挑战以及业务需求在推动成功的数据项目中的关键作用。坚实的数据建模基础可帮助组织创建高效.
揭密Tweepcred:Twitter推荐引擎背后的力量
您已经在 Twitter 上看到一些人具有某种影响力,他们的推文以近乎神奇的效率获得点赞、转发和回复。但是你有没有想过这种影响力是什么?今天,我们将深入 Tweepcred 的神秘世界,这是计算用户在.
数据工程中的三种数据创建方式比较
所有成功的数据驱动组织都有一个共同点;他们有一个高质量和高效的数据创建过程。数据创建通常是数据团队成功与失败之间的区别。数据创建的架构模式在数据创建中,有三种类型的架构模式:事件溯源EventSour.
Bitcask - 日志结构的快速 KV 存储

Bitcask 是最高效的嵌入式键值 (KV) 数据库之一,旨在处理生产级流量。向世界介绍 Bitcask 的论文称它是一个用于快速键/值数据的日志结构 哈希表,用更简单的语言来说,这意味着数据将按顺.
四种分布式数据库介绍
许多分布式系统有效地使用专用存储,例如: 时间序列 blob存储 图形数据库 空间数据库 下面是对它们的简要介绍:时间序列时间序列是与特定时间相关的大量数据的专门存储。 它们经过优化,可以测量数据随时.
CDC变更数据捕获实施模式

在本文中,我想讨论实现 CDC 的几种不同方法,以及一些关键应用程序是什么以及 CDC 如何融入现代数据流架构的大局。有几种从数据库中提取变更事件的方法,每一种都有自己的优点和缺点。因此,让我们仔细看.
批处理与事件流区别?
随着数据成为现代企业中越来越重要的一部分,组织经常发现自己需要处理大量数据。处理数据的两种常见方法是批处理和事件流。批处理 批处理涉及通常在预定的时间间隔(例如每天或每周)内一次处理数据。 常用于不需.
什么是 PageRank 算法?
谷歌创始人拉里佩奇和谢尔盖布林需要一种算法来对页面进行排名并为用户提供最佳搜索结果:PageRank算法。使用 PageRank 算法,每个页面都会根据链接到它的其他页面的数量和重要性获得排名。页面排.
SQL 应该是数据工程管道的默认选择

SQL 应该是新数据工程工作的首选。它坚固、快速、面向未来且可测试。稍加注意,它就会清晰易读。一个新的 SQL 引擎 - DuckDB - 使 SQL 与其他高性能数据框架库竞争,使 SQL 成为各种.
Netflix可扩展的数据注释服务

在Netflix,我们有数百个微型服务,每个都有自己的数据模型或实体。例如,我们有一个存储电影实体元数据的服务或一个存储图像元数据的服务。所有这些服务在以后都想对他们的对象或实体进行注释。我们的团队,.
数据库视图的用处 - Reddit
数据库视图只是伪装成表的查询。数据表主要记录数据。视图产生从该数据派生的信息。下面是几个用途:1、抽象也许您必须连接来自数十个不同表的数据才能获得特定类型报告所需的所有数据。因此,您可以通过创建一个将.
数据管道设计模式

使用 Apache Beam 和 Cookiecutter 启用自助服务数据平台
在本文中,讨论了Achievers 的领域团队如何能够通过利用 PyPi Cookiecutter 引导 Apache Beam 管道?在Achievers,我们正在建立一个自我服务的数据平台,使我们.
面向数据设计带来更好的性能

通过将应用数据放置在后续内存区域中获得更高性能。这使得CPU更容易加载和工作。经典的面向对象编程 (OOP) 将其数据放在内存中,就像意大利肉酱面一样——对象和指针都混在一起了。这很好,直到您想对数据.
Apache Kafka在实时物流、运输行业运用
物流、航运和运输需要实时信息来构建高效的应用程序和创新的业务模型,通过数据流支持相关的决策、建议和警报。这篇博文探讨了 Kafka在USPS、瑞士邮政、奥地利邮政、DHL 和 Hermes 等公司的几.
使用Flink实现Exactly-Once分布式事务 - Devora

查询引擎的工作原理
查询引擎是一种软件,可以对数据执行查询以生成问题的答案,例如: 今年到目前为止,我每月的平均销售额是多少? 过去一天我网站上最受欢迎的五个网页是什么? 网络流量与上一年相比如何逐月比较? 最广泛使用的.
cdc-file-transfer:从Windows同步文件到Linux的传输工具
这个存储库包含用于将文件从 Windows 同步和流式传输到 Linux 的工具。它们基于内容定义分块 (CDC),特别是 FastCDC,将文件分成块。谷歌开发了两个工具cdc_rsync和cdc_.