中台数据工程教程
DuckDB简介

DuckDB是一个内存分析型关系数据库,主要用于数据分析。由于其列式存储性质(单独存储每列的数据),它被视为分析数据库。相比之下,传统的关系数据库采用基于行的存储,逐行存储数据。DuckDB 的优点包.
使用Pandas IO工具流式传输源数据

在当今数据驱动的世界中,有效处理流数据的能力变得越来越重要。无论您是处理实时传感器读数、金融市场更新还是社交媒体源,能够在数据到达时对其进行处理都可以提供有价值的见解并实现及时决策。Pandas 库是.
Scikit-learn可扩展学习简介

随着机器学习模型变得越来越复杂和数据集变得越来越大,可扩展性成为从业者和研究人员的一个重要关注点。虽然 Python 的 scikit-learn 库提供了广泛的机器学习算法,但其有效处理大型数据集的.
Postgres正在蚕食数据库世界

PostgreSQL 不仅仅是一个简单的关系数据库;它是一个数据管理框架,有可能吞没整个数据库领域。“一切皆用 Postgres”的趋势不再局限于少数精英团队,而是正在成为主流最佳实践。OLAP 的新.
Arroyo:基于Arrow和DataFusion的新SQL引擎

Arroyo 0.10 拥有一个使用 Apache Arrow 和 DataFusion 构建的全新 SQL 引擎。它更快、更小、更容易运行。这篇文章将详细介绍 Arroyo 当前的实现以及为什么会发.
实时数据处理:Kafka 和 Flink

在大数据时代,实时洞察是保持领先的关键。但是如何利用不断流动的数据流的力量呢?Apache Kafka 和 Apache Flink登场,这对实时数据处理带来革命性变革的梦之队。这对充满活力的二人组协.
Java中大数据生态和4个工具介绍

大数据 和 Java 形成强大的协同作用。大数据以其高 容量、 高速度和 多样性为特征,已成为各行业的游戏规则改变者。什么是大数据?使用传统数据处理技术难以处理和处理的异常大的数据集被称为“大数据”。.
PySpark DataFrame教程与演示
PySpark DataFrame 是 PySpark 库中的基本抽象,专为分配的记录处理和操作而设计。它是 Apache Spark 生态系统的重要组成部分,提供了一种强大且绿色的方式来大规模处理结.
2024年数据中台工程十大趋势

在当今世界,创新和决策需要实时数据管道和实时数据处理,对数据工程领域的重视程度日益增加。数据工程提供了许多工具和方法,持续为公司提供有关如何克服所面临挑战的见解。什么是数据中台工程?数据中台工程是设计.
案例:Postgres中构建客户数据仓库
在 Tembo(,我们希望拥有一个客户数据仓库来跟踪和了解客户的使用情况和行为。我们希望快速回答诸如 “我们部署了多少个 Postgres 实例?”、 “谁是我们最活跃的客户?”之类的问题。以及 .
将Postgres转变为快速OLAP数据库

pg_analytics 是一个扩展,可将任何 Postgres 数据库的本地分析性能提高 94 倍。安装 pg_analytics 后,Postgres 的速度比 Elasticsearch 快 8.
Postgres不适合用于全文搜索的几种场景

与以搜索为中心的数据库相比,Postgres 全文搜索存在不足的九个领域的概述。什么是全文搜索?全文搜索是指将部分或全部文本查询与数据库中存储的文档进行匹配。与传统的数据库查询相比,全文搜索即使在部分.
什么是数据分析中的仪表板?
了解数据是当今世界任何组织做出最佳决策的关键。然而,即使是最精通数据的人也可能会因某一时刻可用的信息量而不知所措。创建一个可以在一个位置方便地显示所有数据可视化的仪表板是让技术和非技术用户轻松掌握数据.
Apache Spark:释放大数据力量
Apache Spark是一个强大的开源分布式计算系统,已成为大数据处理领域的基石。凭借其多功能的特性和强大的功能,Spark 已成为处理海量数据集的组织的首选解决方案。让我们探讨一下它的主要特性、优.
Apache Calcite 简介

在本教程中,我们将了解Apache Calcite。它是一个功能强大的数据管理框架,可用于与数据访问有关的各种用例。它专注于从任何来源检索数据,而不是存储数据。此外,其查询优化功能可以实现更快、更高效.
分布式数据库系统中主从、主主和无主三种复制算法

分布式系统中的复制对于确保数据一致性、可用性和系统弹性至关重要。这是一种将数据存储在多个节点或服务器上的策略,即使在服务器故障或维护期间也可以防止数据丢失并实现不间断访问。1、单领导者主从复制:涉及一.
案例:使用 Web UI 探索近乎实时的流数据
Expedia Group是世界领先的在线旅游平台之一,他们开发了一个工具,帮助用户使用Kafka、Postgres和WebSockets查询和获取实时流数据,并通过Web浏览器获取实时事件他们面临的.
数据库的6个缺点

这里讨论的是关于数据库在概念上存在的问题,并且已经存在了几十年。1、全局可变状态是有害的每个程序员很早就学会尽量减少使用全局变量中的状态。全局变量偶尔也有合理的用途,但一般来说,全局变量会导致代码纠结.
简单介绍Iceberg与数据湖屋由来
本文从数据存储格式的演变介绍了数据工程领域的大数据处理框架发展,从Hive到Iceberg、Delta Lake以及数据湖屋的发展过程:数据如何存储(在文件和内存中)开源文件格式(如Avro、Parq.
RisingWave:分布式SQL流数据库
RisingWave是一个分布式SQL流数据库,可以简单、高效、可靠地处理流数据。在当今以数据为中心的世界中,流数据已经变得无处不在传统的批处理越来越不能满足业务的实时性要求。RisingWave流数.
当前流行技术栈一览列表

每项任务的最佳技术: Web api:NextJS(Spring Boot 紧随其后) SQL 数据库:PostgresPostgres NoSQL 数据库:DynamoDB 图数据库:Neo4j 前.
Polyjuice:通过并发控制动态学习实现高性能事务

Polyjuice 专为单节点多核设置而设计。它假设所有事务类型都是事先已知的,并且可以作为存储过程运行(请参阅下面的策略表部分)。它不支持 MVCC,因为它是在Silo 框架之上实现的。Polyju.
PolarDB-SCC:阿里低延迟强一致性读取的云数据库分析
阿里巴巴组的这篇论文讨论了如何在PolarDB数据库部署中从从节点执行低延迟强一致性读取。发表在VLDB'23 上。PolarDB采用关系型数据库规范的主从架构。主节点是读写 (RW) 节点,辅助节点.
什么是语义异质性?
语义异质性是指不同系统、领域或人员对信息的解释或含义存在差异。术语、句子结构、语法或概念化方面的差异可能会导致这些差异。使用多种术语或词汇是造成语义异构的典型原因。例如,医院或医学研究机构在描述病人情.
时态数据库简介
显式创建称为时态数据库的系统来管理和存储时态数据或随时间变化的数据。它通过存储和检索有关数据的过去、现在和未来状态的数据,使应用程序能够分析和查询时间维度的数据。时态数据库通过在数据模型中添加时间概念.
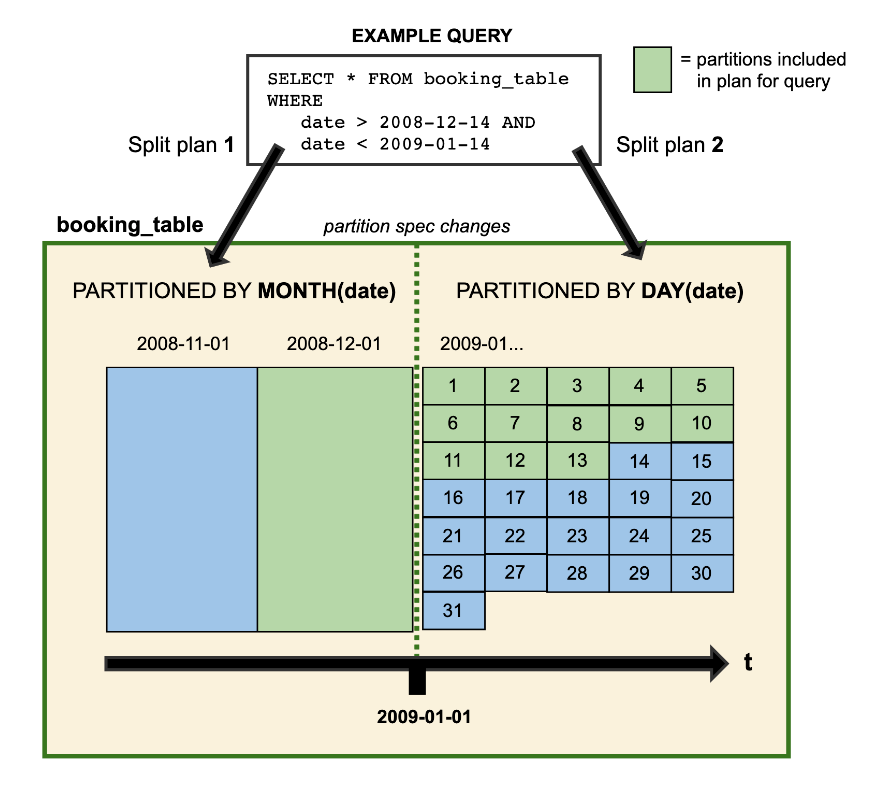
什么是开放表格式OTF?
Python数据管道中的设计模式
使用适当的代码设计模式可以使您的代码易于阅读、可扩展,并且可以无缝地修改现有逻辑、调试,并使开发人员能够更快地上手。为了演示代码设计模式,我们将构建一个简单的 ETL 项目,让我们从 Reddit 中.
2023年游戏数据流的状况
这篇博文探讨了 2023 年游戏行业的数据流状态。包括来自 Kakao Games、Mobile Premier League (MLP)、Demonware / Blizzard 等的客户案例。休闲.
2023年能源和公用事业数据流状况
这篇博文探讨了 2023 年能源和公用事业行业的数据流状态。公用事业基础设施、能源分配、客户服务和新业务模式的发展需要实时的端到端可视性、可靠且直观的B2B 和B2C 通信,以及与 5G 等先锋技术的.
2023年保险数据流的状况
这篇博文探讨了 2023 年保险行业的数据流状态。索赔处理、客户服务、远程信息处理和新业务模式的发展需要实时的端到端可见性、可靠且直观的B2B 和 B2C 通信,并与人工智能/机器学习等前沿技术集成以.