数据库真的成为瓶颈了
不知道大家对此有何高见,当访问量突增时如何应付庞大的数据量。是否使用双主库,或者多主库来解决呢?而外国的这种高并发系统是如何实现的,也是这样的吗?希望大家多多谈谈意见
另一种可能更容易实现的方式是划分数据库,比如每10000个客户使用一个数据库,平行部署多个数据库然后使用一个负载均衡前端。
另一种可能更容易实现的方式是划分数据库,比如每10000个客户使用一个数据库,平行部署多个数据库然后使用一个负载均衡前端。
能否具体说一下,如何使用类似云的缓冲模式?
如果不是用数据库,如何来保证数据的完整性,以及能够生成复杂的报表等
[该贴被admin于2009-11-05 07:53修改过]
CAP原理回答了关于一致性问题。碎片划分数据库缺点:
Sharding会消耗很多关系数据库本身的优点,Sharding侵扰了业务逻辑,对业务逻辑设计进行了干涉
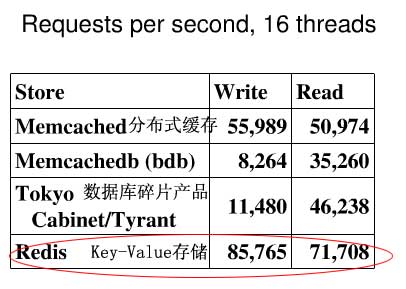
下面是分布式缓存 数据库碎片划分产品和非关系型的分布式key-value性能比较图:
[该贴被banq于2009-11-05 13:44修改过]
有兴趣的话,,可以看看豆瓣的洪强宁在InfoQ做的分享, 应该其中有很多可以借鉴的地方..
对业务部分做切分? 尽可能先切分耦合性较低的业务模块, 再将数据库中较大的字段如大文本(LOB)或者Text字段迁移到分布式文件系统上, 再在Web主机与数据库之间搭建一定的MemCached集群来降低大部分的读IO,
通过上述方式基本上就可以解决大部分网站的性能问题了,,Scalability是很重要, 但是在系统并不需要很高的Scalability的时候, 通过利用NoSQL或者类似的方案可能代价非常高昂, 重要的是设计的时候考虑将来可能如何走, 而不是在不需要的时候就急急的迁移上去..