MiniClaw-OS是一款OpenClaw的模块化认知架构。它包含用于规划、记忆、沟通和创造的大脑区域插件,可在Mac上运行。
它就像 Open Claw的大脑(确切地说是前额叶皮层),可以通过可视化界面(Kankan Board)看到它的计划、操作等等。
MiniClaw结构:
最底层是一个强大的LLM作为基础能源和算力支持,
中间是一套精密的认知架构作为神经网络,
最上面才是各种像乐高积木一样可以自由插拔的“脑区插件”。
你想让AI学会炒股?没问题,给它加装一个“金融交易脑区”。
你想让它帮你做视频?再给它插上一个“视觉创作脑区”。
这个系统最牛的地方就在于,它的能力是可以无限扩展的,你可以像拼乐高一样,亲手打造一个独一无二、为你量身定制的专属AI大脑。
这是一套“类人认知流水线”,从输入 → 认知 → 行动 → 记忆 → 存储,一整套闭环。
整套系统可以理解成五个层级:输入层 → 消息路由 → 核心认知 → 推理层 → 长期记忆与执行。
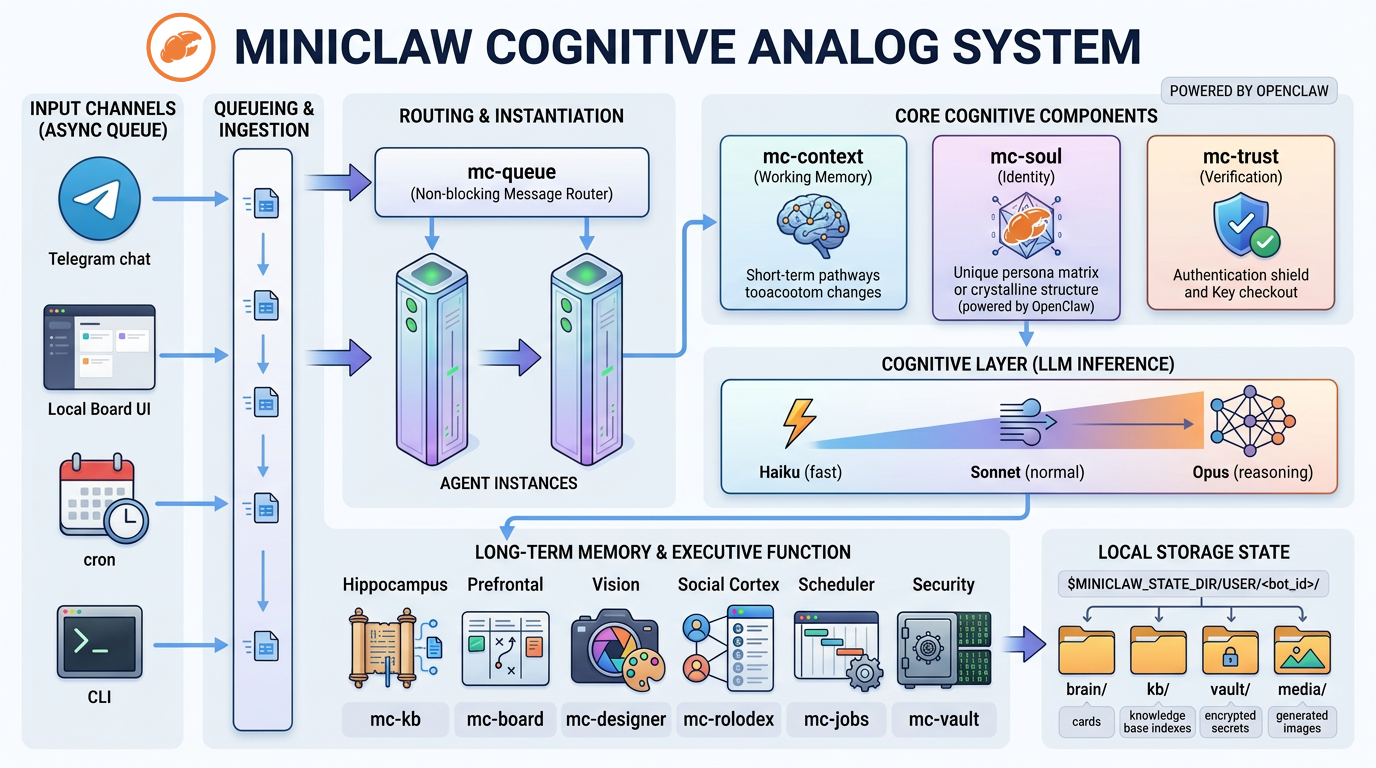
第一部分:输入通道(Input Channels)
这是所有信息进入系统的入口。
这里支持四种输入源:
- Telegram chat
- Local Board UI
- cron 定时任务
- CLI 命令行
这些输入都进入同一个结构:Async Queue(异步消息队列)。
关键点是:所有输入先排队,再处理。
这样做有两个好处:
第一,系统不会被某个任务阻塞。
第二,可以同时处理多个请求。
这一步实际上就是:事件驱动系统EDA。
第二部分:Queueing & Ingestion
所有输入会进入一个 ingestion 层。
这里做的事情主要有三件:
- 解析输入
- 标准化消息格式
- 放入处理队列
换句话说:无论是 Telegram 消息、UI 操作还是 cron 任务,都会被统一转换成同一种“任务消息”。
这一步的意义是:统一协议。
你想啊,如果AI的大脑是个流水线,它最烦的就是送过来的零件长得不一样。现在好了,经过这个分拣拆包处,无论你原来是个方的圆的,最后都变成了流水线上统一的半成品零件。这样一来,AI的脑子就不用费心去辨认你是从哪个门进来的了,它只需要处理这种标准化的消息格式就行。
这就好比学校广播站,不管你是在操场、教室还是食堂投稿,最后广播站收到的都是一张写满字的纸,主播只需要念纸上的字,不用管你这张纸是从哪儿递过来的。这个设计让整个系统变得特别干净,处理逻辑高度统一,不会因为将来想接入个新的输入源,比如微信或者抖音,就得把AI的大脑整个拆了重装,只要在这个拆包处增加一种新的拆包方法就行了,非常优雅且省事儿。
第三部分:mc-queue 路由层
接下来进入图中的核心路由组件:mc-queue。
它的定位是:非阻塞消息路由器。
mc-queue 的职责只有两个:
- 决定任务去哪个 Agent
- 创建 Agent 实例
每一个任务都会生成一个独立的 Agent实例。
这是一种非常典型的设计:短生命周期 Agent;任务完成后实例可以销毁。
好处是:任务互不影响;系统可水平扩展。
这里有个特别关键的设计思想,叫做“短生命周期Agent”。
啥意思呢?就是每一个任务,系统都会生成一个全新的、独立的Agent去专门处理它。这就好比你写作业的时候,不会一辈子只写数学这一门课,而是写数学的时候就拿起数学作业本,写完了放下,再拿起语文作业本。
这些Agent就是一个个的作业本,任务来了就生成,任务完成了,这个Agent实例就可以销毁了,把资源腾出来给别人用。
这么设计的好处是显而易见的:
第一,任务之间互不影响。你写数学作业的时候思路卡壳,不会影响你写语文作业的流畅度,因为它们是两个独立的本子。
第二,系统可以水平扩展。如果同时有十万个人来找AI聊天,系统就能瞬间生成十万个Agent去分别接待他们,大家各聊各的,谁也不用排队等别人聊完,这就叫“可扩展性”,是支撑大流量的关键所在。
第四部分:核心认知组件(Core Cognitive Components)
这部分就是 MiniClaw 的“大脑”。
共有三个核心模块:
- mc-context
- mc-soul
- mc-trust
每个模块对应一个认知能力。
当一个崭新的Agent被创建出来了,它就像一个刚出生的婴儿,脑子里空空如也。但是要处理任务,它总得知道点上下文吧?比如你跟它聊了三句,它不能第四句就忘了你前面说的是啥。
这时候,就要给它装上核心认知组件,也就是MiniClaw的“大脑”了。
这部分有三个大模块,咱们先聊前两个:mc-context和mc-soul。
mc-context管它叫“工作记忆”或者“便利贴系统”:
“Working Memory”和“Short-term pathways”,意思就是短期记忆通道。它的作用就是临时保存当前这个任务里所有相关的信息,比如刚才说了啥,最近的推理步骤到哪儿了,现在任务进行到百分之多少了。所有这些零碎的信息,就像你做题时在草稿纸上写的过程一样,都会被放在mc-context里,然后直接喂给后面的大语言模型(LLM)去处理。
你可以把它想象成人脑的“工作记忆”,就是你在心算“27+35”的时候,暂时记住“7+5=12,进一位”的这个短暂记忆,算完了可能就扔了。
mc-context保存当前任务的上下文,例如:
- 当前对话
- 最近的推理步骤
- 当前任务状态
这部分内容会被直接喂给 LLM。它的作用类似:人脑的工作记忆。
跟mc-context这个临时记忆相对的,是mc-soul,这是个贼有意思的模块,我管它叫“灵魂系统”或者“人设盒子”。
“Identity”和“Unique persona matrix”,就是“身份”和“独特人格矩阵”。
这个模块是用来干嘛的呢?就是给每个Agent定义一个独一无二的“人设”。它决定了这个Agent用什么样的语气跟你说话,它的行为策略是什么,甚至它的价值观是啥。比如,你可以创建一个说话特别幽默逗逼的“脱口秀Agent”,再创建一个说话一本正经、动不动就引用名人名言的“论文Agent”。
这两种Agent的人格参数是完全不一样的,而这个差异就保存在mc-soul里面。这个设计简直是神来之笔,因为它让OpenClaw不再是一个冷冰冰的、千篇一律的应答机,而是可以拥有多副面孔,见人说人话,见鬼说鬼话。今天心情不好就找个温柔安慰型Agent聊,明天想讨论严肃问题就换个逻辑型Agent聊,全看mc-queue调度室给你分配哪个灵魂的Agent。、
每个 Agent 都有一个人格矩阵。
它定义了:
- 角色
- 风格
- 行为策略
- 价值观
比如可以创建:
- 研究型 Agent
- 写作型 Agent
- 客服 Agent
每种 Agent 的“人格参数”都不同。
最后一个是mc-trust(安全验证)
这个模块是系统安全层。
功能包括:
- 身份认证
- 密钥调用
- 权限控制
Agent 想调用某些资源时,需要经过信任验证。例如:
- 访问 API
- 读取私密数据
- 执行系统操作
第五部分:认知推理层(LLM Inference)
接下来是 LLM 推理层。三个推理等级:
- Haiku(fast免费)
- Sonnet(normal)
- Opus(reasoning贵)
这是Anthropic公司多模型!
不同复杂度任务使用不同模型:
- 简单聊天 → Haiku
- 普通任务 → Sonnet
- 复杂推理 → Opus
这样可以做到:速度与成本优化。
Haiku、Sonnet和Opus。这是Anthropic公司(一个AI研究公司)家的大语言模型的不同版本,你可以把它们理解成三个智商和速度都不同的“外援大脑”。
Haiku是个快枪手,反应特别快,但思考深度一般,适合处理那种简单的聊天,比如“今天天气不错”这种,你这边刚问,它那边秒回,不费什么脑子。
Sonnet是个普通选手,速度和智商都处在中等水平,适合处理日常的大部分任务,比如写封邮件、总结个文章,又快又好。
Opus则是个深度思考型选手,它思考得慢,但智商最高,适合处理那种特别烧脑的任务,比如复杂的逻辑推理、写代码框架、分析一堆数据找规律。
这个设计叫“多模型推理策略”,特别聪明,它实现了速度和成本的最优化。
你想啊,如果所有问题,不管是“1+1等于几”还是“如何实现可控核聚变”,你都请那个最聪明但最慢也最贵的Opus来回答,那效率得多低,成本得多高?这就像你出门买个菜,本来骑个自行车就去了,你非要开个法拉利,费油不说,还堵车。
所以这套系统会根据任务的复杂度来动态选择请哪个外援。简单问题,Haiku上;普通问题,Sonnet来;只有遇到真正复杂的问题,才动用王牌Opus。这样既能保证用户能快速得到回复,又不会浪费昂贵的计算资源,是个非常精打细算过日子的小能手。
第六部分:长期记忆与执行功能
在 LLM 推理之后,系统会进入执行与记忆模块。这里的设计完全模仿人脑结构。
六个“认知器官”:
- 海马体:长期记忆
- 前额叶:决策与执行
- 视觉系统:图像理解与创作
- 社会皮层:关系与沟通
- 调度器:时间与任务管理
- 安全模块:身份与权限控制
每个模块对应一个插件。
比如,mc-kb这个插件,对应的就是海马体,海马体在人脑里主要负责长期记忆的形成。所以mc-kb就是AI的“知识库”,它负责保存那些长期的知识、经验总结、文档索引等等。当AI需要查资料的时候,它就会去这个“知识库”里检索。
再比如,mc-board这个插件,对应的是前额叶,前额叶在人脑里负责计划、决策和执行控制。所以mc-board就是AI的“任务看板”,它记录着当前要达成的目标、已经分解好的步骤、以及每一步的执行状态,就像一个项目管理软件,盯着AI按计划办事。
还有mc-designer,对应视觉,专门负责图像生成和设计类的任务。
mc-rolodex,对应社交皮层,专门管理你的联系人列表和聊天历史,谁跟你说了啥,它门儿清。
mc-jobs,对应调度器,就是那个定时任务的闹钟管理员,负责在指定的时间把你设定好的任务扔给调度室去执行。
最后是mc-vault,对应安全,这是个非常重要的“保险柜”,专门用来保存你的各种私密信息,比如API密钥、数据库密码、加密配置等等,确保这些核心机密不会被随便调用。
你看,这整个设计,就是把一个完整的人脑认知功能,拆解成了一个个可以插拔的软件模块,需要哪块功能,就把对应的插件装上,不需要就卸下来,模块化程度非常高。
第七部分:本地存储结构
最右边是数据落地结构。所有数据保存在:$MINICLAW_STATE_DIR/USER/
下面有四个目录:
- brain/
- kb/
- vault/
- media/
含义分别是:
- brain:Agent 的状态卡片
- kb:知识库索引
- vault:加密密钥
- media:生成内容(图片等)
brain/目录,存的是Agent的状态卡片,也就是每个Agent的“人设档案”和当前的“工作记忆”,记录了它是个谁,正在干啥。
kb/目录,是知识库的物理存储地,所有长期记忆的文档索引都放这儿。
vault/目录,就是那个保险柜,加密后的密钥就放在这个文件夹里。
media/目录,放的是AI生成的各种内容,比如你让它画的图,它生成的视频,都存这儿。
这一套目录结构,就像是你房间里井井有条的抽屉:手办放一个抽屉,课本放一个抽屉,日记本锁一个抽屉,零食再放一个抽屉。找东西的时候,直接去对应的抽屉翻就行,不会乱。这种清晰的数据落地方式,让整个系统的状态变得可管理、可备份、可迁移,你可以把整个机器人的文件夹打包发给别人,人家一运行,就能得到一个和你一模一样的AI,连记忆和性格都完全复制,是不是特别酷?
总结
系统流程就是:
输入消息
→ 队列排队
→ mc-queue 路由
→ 创建 Agent
→ 注入 context / soul / trust
→ LLM 推理
→ 调用执行模块
→ 写入长期记忆
→ 更新本地状态
这就是一个完整的:认知循环。
一条消息从进门到被记住,到底经历了一场怎样的奇妙旅程:
首先,你在Telegram上给OpenClaw发了条消息,比如“帮我画一只会飞的猪”。这条消息瞬间进入了异步队列,开始排队。很快它被分拣拆包,变成了标准化的任务消息。
然后,mc-queue调度室看到这个任务,一拍大腿:“这是个画画任务,得找个有艺术细胞的Agent!”于是它立刻创建了一个新的Agent实例,并从mc-soul里给它加载了一个“卡通画师”的人格,从mc-context里初始化了一个空的画板(工作记忆),并且让mc-trust确认了你有调用画画插件的权限。
接着,这个具备了灵魂、记忆和权限的Agent,带着你的问题去敲LLM的门。
它看了看问题,觉得“画一只会飞的猪”不算特别复杂,但也不是随口一句“你好”那么简单,于是它决定请Sonnet这个普通选手出马。
Sonnet思考了一下,给出了一个详细的作画指令,比如“一只粉色的小猪,背上长着白色的天使翅膀,在蓝天白云下飞翔”。
得到指令后,Agent就去调用mc-designer这个视觉插件。mc-designer吭哧吭哧地把图给画了出来。
画完之后,Agent会把这个成果记录到mc-context里,告诉大脑“任务完成了”。
然后它会把这个经历,比如“用户让我画了一只会飞的猪,我用了卡通风格”,打包发给mc-kb知识库,让它存进长期记忆里,下次你再提“会飞的猪”,它马上就能想起来。
同时,它也会把这张图片存到media/目录里。
最后,它通过原路返回,把画好的图片发回到你的Telegram上。
你看,从输入、认知、推理、执行到记忆,一个完整的“认知循环”就这么跑完了。这就是MiniClaw-OS这个“人脑模拟软件”的厉害之处,它不是简单地处理信息,而是在试图构建一个真正的、有生命感的AI个体。