如何理解Stream processing, Event sourcing, Reactive, CEP?
流处理Stream processing, 事件溯源Event sourcing, 响应式Reactive, 复杂事件处理CEP, CQRS等等这些概念好像是分离豪不相关的,其实它们内在的逻辑是一致性的。
来自 talk /dev/winter 2015对这三个概念进行了深入理解与分析:分布式流处理概念来自于互联网公司LinkedIn,而CAEP来自于90年代的event simulation research,ES事件溯源则是属于领域驱动设计社区,用于企业软件开发的一种方式,这种方式适合复杂的数据模型,同时数据量又小于互联网应用的场景。
首先,我们从Google Analytics这个案例开始,这是一段Javascript放在你的网站上,跟踪每个页面被哪些访客访问,管理员通过时间线或根据URL浏览这些统计数据,那么你如何自己实现类似谷歌分析这样的工具呢?
每次用户浏览一个页面,我们需要记录一个事件,一个page view事件看上去如下下面(伪JSON):
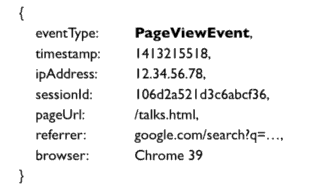
这个page view事件有一个事件类型(PageViewEvent),还有一个显示事件发生的时间戳,客户的IP以及会话ID(cookie的唯一标识用来跟踪同一个用户的一系列浏览行为),页面的URL,以及从哪上一个页面到当前页面的URL,浏览器设置等等。
这个事件很简单,是不可变的事实,只是记录某个发生的事情。那么我们如何基于这些事实获得用户是如何访问我的网站的整个情形呢?
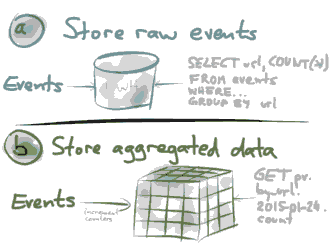
有两种选项:
Option (a): 每次将单个事件存储一次,导入到一个大数据库,或数据仓库或一个Hadoop集群等大的数据集中,你可以运行一个大的SELECT 来查询这个数据集,这种查询将会扫描所有涉及到的事件,进行聚合分析。
Option (b): 如果每次都存储一个事件太浪费了,你可以存储一个事件汇总的结果,比如,如果你计数,那么每次有事件进来时,就增加一下计数数值,扔掉那些进行来的事件,你也可以设计一种数据表结构,代表多维视角,一维是URL,另外一维是事件的时间,另外一维是浏览器,对于每个事件,你只需要增加对应URL在某个时间下的总计数就可以了。这是我们非常常见的关系数据库数据表结构设计场景。
使用这种方式,你如果要发现某天某个URL的页浏览量数量,只需要使用URL和时间作为Select查询参数,直接查询这个数据表即可。不必每次都要存储每个事件,从这点来看,方案a显得非常疯狂,但是它却令人惊奇地工作得很好,相信Google Analytics 实际也是如同方案a这么存储原始事件的,现代分析数据库非常擅长快速扫描大量数据,因此每次查询数据时,都会依赖这些现代技术扫描所有有关的事件。
存储原始数据的最大好处是你有分析上巨大灵活性,你能跟踪一个用户会话阶段的所有浏览页面序列,如果你采取方案b就无法实现,因为你事先没有设计这样的数据表结构,需求是时刻变化的,今天用户希望从这些事件上获得一种汇总结果,明天他们可能需要另外一种汇总结构,如果每种汇总结果都设计一个数据结构,那么数据表数量不但庞大,而且数据冗余,同时新的数据表结构无法对以前的事件数据进行汇总聚合,因为你将以前的原始事件扔掉了,失去了事件真相。
最好的办法是你保存这些原始事件,如果技术发展了,还可以使用机器学习系统对这些原始事件进行分析,但是方案b能够对某个具体汇总查询有实时响应。因此,原始事件存储和事件的汇总聚合都是有用处的,只是针对不同的用例情况。
那么如何结合这两个方式呢?我们可以使用缓存memcache等存储事件的汇总聚合,每次进来一个事件,我们只要修改一个汇总聚合的状态即可,而引入事件流或消息队列或事件日志来保存原始事件,一个消息包含一个事件,这样我们能够以很便宜低廉方式保存原始事件,同时也会消费这些原始事件提供了多种消费可能,只要设计多个消息队列的消费者即可,
Event Sourcing也类似方案a,每次保存的都是原始事件,以购物车为案例,每次保存的不是购物车当前有几个商品,而是保存的是造成当前有几个商品的原因,也就是用户进行了那些加入和移除事件后,最后造成当前购物车的这种状态。我们将AddToCart, UpdateCartQuantity等对购物车的加入和修改操作作为原始事件,类似方案a的用户浏览事件一样,当你要查询当前购物车状态时,只要通过播放这些动作就能获得最终购物车的状态。
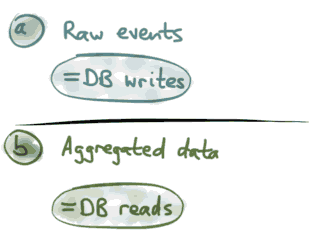
这种方式可以归结为:写入原始事件,读取出事件的汇总结果。也就是说,只要将原始操作事件保存写入数据库,我们通过读取数据库播放这些事件就能获得当前状态,传统方式是:我们设计一个关系数据表,也就是方案b,用来保存购物车当前状态,原始事件更改玩状态后就扔掉了,也就是updateSQL语句每次操作完成就扔掉了,而没有记录哪些事件触发这个update SQL的发生。
这样我们就可以使用一个数据库进行写,一个数据库专门用来读,这些读写方式分离分担了系统的负载,写数据库专门写入原始事件,读数据库专门用来进行事件的汇总聚合结果的读取。
下面我们再以Twitter为案例说明这种方式。