大数据专题
日志是每个软件工程师关心的统一数据抽象
这是来自LinkedIn的Kreps发表的一篇博文,虽然很长,但是被称为程序员史诗般必读文章。日志原本应该是运维人员掌握的,如今也是研发人员必须关心的,这是符合DevOps原则。
我是在六年前一个令人兴奋的时刻加入到里了LinkedIn公司。从那个时候我们就开始突破传统整体的(monolithic)、集中式的数据库限制,然后切换到一个特殊的分布式系统。这是一件令人兴奋的事情:重新构建、部署,这些分布式图形数据库、分布式搜索后端、Hadoop以及第一代和第二代key/value的NoSQL数据存储直到今天仍然在运行。
从这一切中我们体会到最有益的事情是:我们构建的这些许多东西的中有一个核心,也就是包含一个简单的理念:日志。有时候也被称作预先写入(write-ahead)日志、提交日志或事务性日志。日志几乎在计算机产生的时候就已经存在,同时它还是许多分布式数据系统和实时应用结构的核心。
不懂得日志,你就不可能完全理解关心数据库、NoSQL存储,键值Key/value存储,数据复制,分布式paxos协议、大数据处理Hadoop、甚至版本控制等几乎所有的软件系统;然而大多数软件工程师对它们不是很熟悉。我愿意改变这种现状。在这篇博客文章里,将介绍有关日志的所有的事情,包括日志是什么,如何在数据集成、实时处理和系统构建中使用日志等。
第一部分:日志是什么?
日志是一种简单的不能再简单的存储抽象。它是一个只能增加的( append),完全按照时间排序的一系列记录。日志看起来如下:
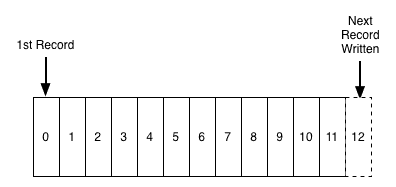
只能给日志的末尾添加记录(append 类似队列),日志记录是从左到右读取的。每一条日志记录都有一个唯一的序列编号(一般我们使用时间戳)。
日志记录的排序是由"时间"决定,处于左边的记录比右边的要早些。记录编号可以看作是这条记录的"时间戳"。当然刚开始我们就把这种排序说成是按时间排序显得有点多余 ,不过 ,与任何一个具体的物理时钟相比,时间属性是非常便于使用的属性。在多个分布式系统中,时间会非常重要。
日志在存储空间完全耗尽的情况下,就不可能再给日志添加记录。稍后我们将会提到这个问题。 日志只是按照时间顺序存储记录的 一种数据表或者文件,可以表现为日志文件或日志数据库。
日志重要特点是:它记录了在某个什么时间发生了什么事情。 而这对分布式数据系统而言才是问题的真正核心。
不过,在我们更加深入的讨论之前,先澄清有些让人混淆的概念。每个编程人员都熟悉另一种日志:使用syslog或者log4j写入到本地文件里的、没有结构的、跟踪信息或错误信息。为了将两者区分开来,我们把这种日志称为"应用日志"。应用日志是我所说日志中的一种低级变种。两者最大的区别是:这些文本日志意味着主要用来方便人们阅读,而我所说的"日志"或者"数据日志"是为了方便程序访问。
(实际上,如果你对它进行深入的思考,那么人们自己读取某个机器上的日志这种理念有些不顺应时代潮流。当涉及到许多服务和服务器的时候,这种方法很快就变成一个难于管理的。)
数据库日志
我不知道日志概念是起源于何时何处-可能它就像二进制搜索一样:发明者认为它太简单而没有当作一项发明。它最早出现在IBM的系统R。
日志在数据库里的用法是:当数据库崩溃的时候用日志来同步各种数据结构和索引。为了保证操作的原子性和持久性,在对数据库进行维护,也就是所有各种数据结构做出更改之前,数据库会把即将修改的信息备份追加到日志里。日志记录了已经发生了什么,每个表或者索引都是其历史投影。由于日志是即刻持久化的,所以在当机时可以用来作为恢复的可信数据源。
随着时间推移,日志用途从实现ACID发展为数据库之间复制数据的一种方法。发生在数据库上的操作动作顺序与远端备份数据库上的操作顺序通过日志保持完全同步。Oracle,MySQL 和PostgreSQL都是使用复制日志同步实现主从同步。Oracle还把日志产品化为一个通用的数据订阅机制,这样非Oracle数据订阅用户也可以使用XStreams和GoldenGate订阅数据了,MySQL和PostgreSQL有类似的实现则,日志已经成为许多数据结构的关键组件。
正是由于这样的起源,机器可识别的日志这个概念大部分时候还是都被局限在数据库内部。日志用做数据订阅的机制似乎是偶然出现,不过要把这种数据抽象用于支持所有类型的消息传输、数据流和实时数据处理也是可行的。
分布式系统日志
日志解决了两个问题:操作动作的顺序化和数据的分发,这两个问题在分布式数据系统里显得尤为重要。保持一致的操作动作的顺序是分布式系统设计的核心问题之一。
以日志为中心实现分布式系统是受到了一个简单经验常识的启发,它称为状态机复制原理:如果两个相同的确定的处理过程从同一状态开始,以相同的顺序输入相同的(数据或事件),那么这两个处理过程必然会产生相同的输出(结果),并且在最后相同的状态结束。
这也许有点难以理解,让我们更加深入的探讨,弄懂它的真正含义。
确定性意味着处理过程是与时间无关,而且任何其他"外部的"输入不会影响到其处理结果。例如,如果一个程序的输出会受到线程执行的具体顺序影响,或者受到gettimeofday调用、或者其他一些非重复性事件的影响,那么这样的程序一般被认为是非确定性的。
处理状态是处理过程保存在计算机上的任何数据(状态),在处理过程结束后,这些状态数据要么保存在内存里,要么保存在磁盘上。
“以相同的顺序获得相同输入”这个地方应当引起注意的是:这里就是引入日志的地方。这儿有一个重要的常识:如果给两段确定性代码相同的日志输入,那么它们就会生成相同的输出。
分布式计算在这方面的应用格外明显。你可以把用多台机器一起执行同一件事情缩减为为这些流程输入分布式一致性的日志数据。这里使用日志的目的是把所有非确定性的东西排除在输入流之外,这样来确保每个复制都能够同步地处理输入。
当你理解了以后,状态机复制原理就不再复杂或者说不再深奥了:它或多或少的意味着"确定性的处理过程就是确定性的"。不管怎样,我都认为它是分布式系统设计里较常用的设计工具之一。
这种方式的一个美妙之处就在于作为日志的索引的时间戳就像时钟状态的一个副本——你可以用一个单独的数字描述每一个副本,这就是经过处理的日志的时间戳。时间戳与日志一一对应着整个副本的状态。
由于写进日志的内容不同,也就会有许多在系统中应用这个原则的不同方式。举个例子,我们可以记录一个服务的请求,或者也可以记录服务从请求到响应的状态变化,或者它执行命令的转换。理论上来说,我们甚至可以为每一个要执行的机器指令或者调用的方法名和参数实现一系列副本记录。只要两个处理过程用相同的方式处理这些输入,这些处理过程就会保持副本的一致性。
一千个人眼中有一千种日志的用法。数据库工作者通常区分物理日志和逻辑日志。物理日志就是记录每一行被改变的内容。逻辑日志记录的不是改变的行,而是那些引起行的内容被改变的SQL语句(insert,update和delete语句)。
分布式系统通常可以宽泛划分为两种方法来进行数据处理和复制。"状态机器模型"通常使用一个active-active模型,在这个模型中我们保存了请求和该请求的复制处理。
我们可以对"状态机器模型"进行细微的更改,称之为"预备份primary-backup模型",也就是选出一个副本做为leader,并允许它按照请求到达的时间来进行处理请求,并将该请求导致状态的改变输出到日志。其他的副本按照leader状态改变的顺序而应用执行这些改变,这样他们之间就能达到同步,并能够在leader失败的时候接替leader的工作。

如图"预备份模型"和"状态机器模型"是有些区别的,假定有一个算术服务,它内部有一个使用数字属性作为它的状态(初始值为0),并对这个值进行加法和乘法运算。active-active模型(状态机器模型)方式应该会输出所进行的变换,比如"+1","*2"等动作。每一个副本都会应用这些变换,从而得到同样的结果集。active-passive(预备份模型)方式将会有一个独立的主处理过程执行这些变换并输出结果日志,比如"1","3","6"等。这个例子也清楚的展示了为什么说顺序是保证各副本间一致性的关键:一次加法和乘法的顺序的改变将会导致不同的结果。
分布式日志可以看成是解决一致性问题模型的数据结构。因为日志代表了后续追加的一系列确定值。你需要重新审视Paxos算法簇,尽管日志模块是他们最常见的应用。 在Paxos算法中,它通常通过使用称之为多paxos的协议,这种协议将日志建模为解决共识(一致性)问题的方案。而在ZAB, RAFT等其它的协议中,日志的作用尤为突出,它直接是解决维护分布式的一致性问题。
可能是由于过去的几十年中,分布式计算的理论远超过了其实际应用。在现实中,一致性的问题是有点太简单了。计算机系统很少需要决定某个单值,他们几乎总是处理成序列的请求。所以日志作为这样的记录,而不是一个简单的单值寄存器,自然是更加抽象。
此外,专注于算法会掩盖了 底层系统需要的日志的抽象。我怀疑,我们最终会把日志为一个商品化的基石,不论其是否以同样的方式 实施,日志将成为一种大众化的接口,为大多数算法和其实现提升提供最好的保证和最佳的性能。
记录变更101: 表与事件是一对
让我们还是回到数据库。数据库中存在着大量重复:操作日志和表是一对“情侣”。这些日志有点类似借贷清单和银行的流程,数据库表记录的是当前的盈余表。如果你有大量的操作日志,你就可以使用这些操作从而创建可以捕获当前状态的表(类似领域事件/CQRS)。这张表将记录每个关键点(日志中一个特别的时间点)的状态信息。这就是为什么日志是非常基本的数据结构的意义所在:日志可用来创建基本表,也可以用来创建各类衍生表。同时意味着可以存储非关系型的对象。

这个流程也是可反向:如果你正在对一张表进行更新,你可以记录这些变更动作事件,并把所有更新事件的日志作为表的状态信息进行记录。这些变更事件的记录日志就是你所需要的支持准实时的克隆。基于此,你就可以清楚的理解表与事件的相似性: 表支持了静态数据,而日志捕获了变更这个动态动作。日志的魅力就在于它是变更动作事件的完整记录,它不仅仅捕获了表的最终版本的内容,它还记录了曾经存在过的其它版本的信息。日志实质上是表历史状态的一系列备份。
这可能会引起你对源代码版本管理的联想。源代码管理和数据库之间有密切关系。版本管理解决了一个大家非常熟悉的问题,那也是分布式数据系统需要解决的--- 时时刻刻在变化着的分布式管理。版本管理系统通常以补丁的发布为基础,这实际上可能是一个日志。您可以直接对当前源代码 类似于表一样做出一份"快照"。你会注意到, 与其他分布式状态化系统类似,版本控制系统在 当你更新源码时会复制到日志,当你提交新代码时,你只是将更新应用到你的当前快照中而已。
最近,有人从Datomic 一家销售日志数据库的公司得到了一些想法。这些想法使他们对如何 在他们的系统应用这些想法有了开阔的认识。 当然这些想法不是只针对这个系统,他们会成为 十多年分布式系统和数据库文献的一部分。
这可能似乎有点过于理想化。但是不要悲观!我们会很快把它实现。
接下来的内容
在这篇文章的其余部分,我将试图说明日志除了可用在分布式计算或者抽象分布式计算内部模型之外,还可用在哪些方面。其中包括:
-
数据集成-让组织的全部数据存储和处理系统里的所有数据很容易地得到访问。
-
实时数据处理-计算生成的数据流。
-
分布式系统设计-实践中的的系统是如何通过使用集中式日志来简化设计。
所有这些用法都是通过把日志用做单独服务来实现的。
在上面任何一种用法里,日志的用途开始都是使用了日志所能提供的某个简单功能:生成永久的、可重现的历史记录。令人意外的是,问题的核心是可以让多少台机器以特定的方式,按照自身的速度重现历史记录的能力。
下页
原文The Log: What every software engineer should know about real-time data's unifying abstraction
如何理解Stream processing, Event sourcing, Reactive, CEP?