如何理解Stream processing, Event sourcing, Reactive, CEP?(3)
在上一篇中,我们以Facebook和Twitter为案例,说明如何使用的单独流程,一边接受大量连续不断的原始事件写入,一边根据不同阅读页面要求更新缓存,以便将原始事件转换到适合不同读取角度的汇总聚合结果。
下面再以LinkedIn为案例,每个人发布自己的当前工作情况,这些事件写入数据库,而读取页面有各种各样,这里以搜索为例,当你输入一些关键词,比如公司名,那么在这个公司的所有人员都应该出现在提示框中。

为了实现搜索,你需要搜索索引,这个索引其实是另外一种聚合结构,当有新的数据事件加入,这个结构也需要跟随新数据变化。
总结以上Twitter Facebook LinkedIn的模式如下:
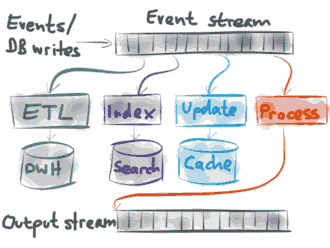
大量持续不断的单个事件写入数据库中,这也就是一种事件流,根据这个持续不断的事件流,你能够构建不同的聚合结构,如View视图 缓存和搜索索引,你还能设置一个独立的Process处理过程,翻译转换到输出流output stream;总之,有了事件流,你能依据这个流做很多事情。
- 你能将所有事件转换到一个大数据仓库,在那里可以进行数据分析和查询。
- 你能更新完整文本搜索索引,这样当用户点击搜索框时,能够搜索到实时的数据。
- 你能使用事件对缓存进行更新,这样缓存能够方便快速读取最新数据。
- 最后,你可以将一个事件流转换到另外一个输出流,作为其他系统的输入,这样能够串联起一个复杂的事件驱动大型系统。
不管怎样,传统数据库也采取这种事件处理方式进行读写,比如像PostgreSQL, MySQL's InnoDB 和Oracle, 和 append-only B-trees of CouchDB, Datomic 和LMDB 等MVCC数据库都是相同类似思想。这里我们是将数据库引擎内部机制作为应用程序架构来实现。
复杂事件处理CEP来源于90年代的event-driven simulation,,大部分CEP产品都是商业化昂贵软件,只有 Esper 是免费开源,使用CEP你能在事件中进行匹配查询,相比SQL查询,CEP引擎持续不断查询事件流以发现匹配你的要求并通知你,这对于实时监控业务处理是非常有用的。