机器学习教程之深度学习前馈神经网络
神经网络是真的只是一个感知器组合,以不同的方式连接和操作在不同的激活函数上。

首先,我们来看看前馈神经网络,它具有以下属性:
- 一个输入、输出和一个或多个 隐藏的 层。 上面的图显示了一个与3-unit网络输入层,4单元隐藏层和2单元输出层(单元和神经元是可以互换的)。
- 每个单位是一个感知器。
- 输入层单元作为隐层单元的输入,而隐层单元是输入到输出层。
- 每个两个神经元之间连接有一个权重 W (类似于感知器的权重)。
- 每个单元的层 T 通常是连接到 每一个 前面的层单元 t - 1 (尽管你可以通过设置权重为0断开他们)。
- 为了处理输入数据,你将输入向量插入输入层,设置向量的值作为每个输入单元的"输出"。 在这种特定的情况下,网络可以处理三维输入向量(因为3个输入单位)。 例如,如果您输入向量(7、1、2),然后你要设置上层输入单元的输出为7,中间单元为1,等等。 这些值然后为每个隐单元使用加权和传递函数向前传播到隐藏单元,,进而计算其输出(激活函数)。
- 输出层以如同隐藏层相同的方式计算输出。 输出层的结果是网络输出。
线性以外
如果我们每一个感知器只允许使用一个线性激活函数,然后,我们的网络将最终的输出 仍然 一些输入的线性函数以及从整个网络收集的大量的不同的权重调整。换句话说,一群线性函数的线性组合仍只是一个线性函数。 如果我们局限于线性激活函数, 前馈神经网络与感知器相比也不再是多么强大,无论有多少层。
一群线性函数的线性组合仍只是一个线性函数,因此大多数神经网络使用非线性激活函数。
正因为如此,大多数神经网络使用非线性激活函数等 logistic , 双曲正切 , 二进制 或 整流器rectifier 。 没有他们,网络只能 输入的线性组合 的学习功能。
感知器训练
最常见的深度学习为多层感知器的监督学习算法的训练被称为反向传播。 基本过程:
- 提出了一种训练样本,通过网络向前传播。
- 出误差计算,通常均方误差:
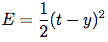
T 目标价值 Y 是实际的网络输出 其他错误的计算也可以接受的 但MSE是一个不错的选择。
- 网络错误使用方法调用最小化 随机梯度下降 。
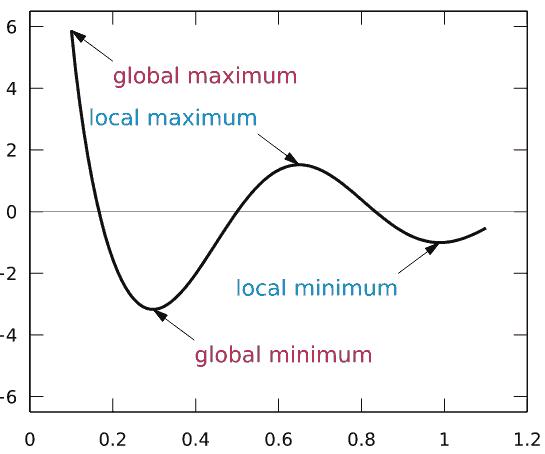
梯度下降是普遍的,但在神经网络中,这将是作为输入参数的函数的训练误差的图, 每个权重是最优值的误差是达到了 global minimum,在训练阶段,小步骤的权重更新(在每个训练样本或mini-batch几个样本)的方式,他们总是试图进入 global minimum, 这不是件容易的事,就像你会在 local minima,图中在右边的一个。 例如,如果权重值为0.6,需要改变到0.4
这个图是最简单的情况下,误差取决于单个参数。 然而网络错误依赖每个网络权重和错误,函数要复杂得多。
谢天谢地,反向传播提供了一个方法使用输出误差来更新每个权重之间的两个神经元,它的推导本身相当复杂,但重量更新给定节点具有以下(简单的)形式:
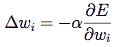
E 是输出误差, w_i 输入到神经元的权重
从本质上说,目标是朝着响应权重方向梯度梯度前进,错误产生的衍生是不容易计算的,你如何在一个中大型网络中发现一个随机隐藏节点中的随机权重衍生呢?
答案是:通过反向传播。 错误在输出单元将首先被算,这个公式很简单(基于目标和预期值)之间的区别,然后以聪明的方式网络回播,使我们能够有效地更新我们的训练权重,(希望)达到最小。
隐层
隐藏层是特别有趣的。 通过通用逼近定理 ,一个带有有限数量的神经元单隐层网络可以被训练来近似一个任意随机函数。 换句话说,一个隐藏层是强大到足以学习 任何 函数。 也就是说,我们在实践中使用多层会学习得更好(即隐藏层。 深网)。
隐层是网络存储其内部训练数据的抽象。
在隐层,网络存储其内部训练数据的抽象,类似于人脑的方式(大大简化类比),大脑有一个外部世界的的内部表示。 今后在本教程中,我们将看看在隐藏层不同的方法。
网络案例
你可以看到一个简单的(4-2-3层)前馈神经网络案例,分类 IRIS 数据集,Java是实现源码在here ,通过testMLPSigmoidBP方法,数据集包含三个iris植物 分类如花萼长度和花瓣长度等特性,网络是每一个类提供50个样本。这些特性是被放入输入单元,而每个输出单元响应一个数据集的单个分类:"1/0/0"表明,植物类Setosa,"0/1/0"表示Versicolour,"0/0/1"表示Virginica),分类错误是2/150,每150个有两个误分类。
大型网络的问题
神经网络可以有多个隐层:在这种情况下,更高的层是"建筑"的新先前之上的抽象层。 正如我们前面提到的,你在实践中的更大网络中可以学习更好。
然而,增加隐藏层的数量会导致两个问题:
- 消失的梯度Vanishing gradients :当我们添加越来越多的隐藏层,反向传播变得越来越没有用,特别是向下层传递信息。实际上,随着信息传回,梯度开始消失,相对于网络的权重变得越来越小。
- 过度拟合Overfitting :也许是机器学习的核心问题。 简单地说,过度拟合是指与训练数太 密切了,会带有太多假设的复杂。 在这种情况下,你的学习者最终可以拟合训练数据,而在在真正的例子中真正执行时却很差。。
让我们看看一些深度学习算法来解决这些问题。