使用Apache Flink和Kafka进行大数据流处理
Flink是一个开源流处理框架,注意它是一个处理计算框架,类似Spark框架,Flink在数据摄取方面非常准确,在保持状态的同时能轻松地从故障中恢复。
Flink内置引擎是一个分布式流数据流引擎,支持流处理和批处理,支持和使用现有存储和部署基础架构的能力,它支持多个特定于域的库,如用于机器学习的FLinkML、用于图形分析的Gelly、用于复杂事件处理的SQL和FlinkCEP。Flink的另一个有趣的方面是现有的大数据作业(Hadoop M / R,Cascading,Storm)可以通过适配器在Flink的引擎上执行,因此这种灵活性使Flink成为Streaming基础设施处理的中心。
它支持所有下面关键功能:
- 处理引擎,支持实时Streaming和批处理Batch
- 支持各种窗口范例
- 支持有状态流
- Faul Tolerant和高吞吐量
- 复杂事件处理(CEP)
- 背压处理
- 与现有Hadoop堆栈轻松集成
- 用于进行机器学习和图形处理的库。
核心API功能:
- 每个Flink程序都对分布式数据集合执行转换。提供了用于转换数据的各种功能,包括过滤,映射,加入,分组和聚合。
- Flink中的接收器操作用于接受触发流的执行以产生所需的程序结果,例如将结果保存到文件系统或将其打印到标准输出
- Flink转换是惰性的,这意味着它们在调用接收器操作之前不会执行
- Apache Flink API支持两种操作模式 - 批量操作和实时操作。如果正在处理可以批处理模式处理的有限数据源,则将使用DataSet API。如果您想要实时处理无限数据流,您需要使用DataStream API
擅长批处理的现有Hadoop堆栈已经有很多组件,但是试图将其配置为流处理是一项艰巨的任务,因为各种组件如Oozi(作业调度程序),HDFS(和用于数据加载的存储),ML和图形库和批处理工作都必须完美协调。最重要的是,Hadoop具有较差的Stream支持,并且没有简单的方法来处理背压峰值。这使得流数据处理中的Hadoop堆栈更难以使用。让我们来看看Flink架构的高级视图:

对于每个提交的程序,创建一个客户端,该客户端执行所需的预处理并将程序转换为并行数据流形式,然后由TaskManagers和JobManager执行。JobManager是整个执行周期的主要协调者,负责将任务分配给TaskManager以及资源管理。
它的组件图如下:

Flink支持的流的两个重要方面是窗口化和有状态流。窗口化基本上是在流上执行聚合的技术。窗口可以大致分为
- 翻滚的窗户(没有重叠)
- 滑动窗(带重叠)
支持基本过滤或简单转换的流处理不需要状态流,但是当涉及到诸如流上的聚合(窗口化)、复杂转换、复杂事件处理等更高级的概念时,则必须支持有状态流。
使用Kafka和Flink的Streaming架构如下
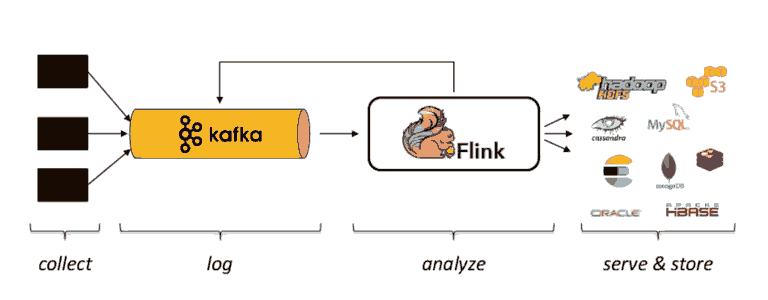
图10 - 来自Stephan Ewen的演讲“Apache Flink和Apache Kafka的高级流分析”
以下是各个流处理框架和Kafka结合的基准测试,来自Yahoo:
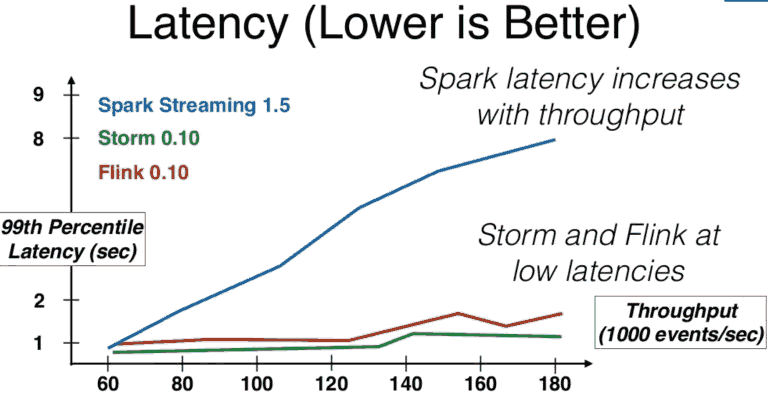
图11 - 来自Ufuk Celebi的谈话“使用Apache Flink的统一流和批处理”[7]
该架构由中Kafka集群是为流处理器提供数据,流变换后的结果在Redis中发布,可用于架构之外的应用程序。正如你所看到的,即使在高吞吐量的情况下,Storm和Flink还能保持低延迟,而Spark要差多了。继续增加数据量Flink不仅跑赢了Storm,而且还以大约300万次/秒的速度使Kafka链接饱和。
案例源码
Flink程序的入口点是ExecutionEnvironment类的实例- 它定义了执行程序的上下文。
让我们创建一个ExecutionEnvironment来开始我们的处理:
ExecutionEnvironment env
= ExecutionEnvironment.getExecutionEnvironment();
请注意,在本地计算机上启动应用程序时,它将在本地JVM上执行处理。如果要在一组计算机上开始处理,则需要在这些计算机上安装Apache Flink并相应地配置ExecutionEnvironment。
我们将创建两个作业:
- 生产者WriteToKafka :生成随机字符串并使用Kafka Flink Connector及其Producer API将它们发布到MapR Streams主题。
- 消费者ReadFromKafka:读取相同主题并使用Kafka Flink Connector及其Consumer消息在标准输出中打印消息。
下面是Kafka的生产者代码,使用SimpleStringGenerator()类生成消息并将字符串发送到kafka的flink-demo主题。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", “localhost:9092");
DataStream<String> stream = env.addSource(new SimpleStringGenerator());
stream.addSink(new FlinkKafkaProducer09<>("flink-demo", new SimpleStringSchema(), properties));
env.execute();
}
- 创建一个新StreamExecutionEnvironment对象,这是使用Flink应用程序的起点
- DataStream在应用程序环境中创建一个新的SimpleStringGenerator,该类实现SourceFunction Flink中所有流数据源的基本接口。
- 将FlinkKafkaProducer09添加到主题中。
消费者只需从flink-demo主题中读取消息,然后将其打印到控制台中。
public static void main(String[] args) throws Exception {
// create execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", “localhost:9092");
properties.setProperty("group.id", "flink_consumer");
DataStream<String> stream = env.addSource(new FlinkKafkaConsumer09<>(
"flink-demo", new SimpleStringSchema(), properties) );
stream.map(new MapFunction<String, String>() {
private static final long serialVersionUID = -6867736771747690202L;
@Override
public String map(String value) throws Exception {
return "Stream Value: " + value;
}
}).print();
env.execute();
}
- 用消费者信息创建一组属性,在这个应用程序中我们只能设置消费者group.id。
- 使用FlinkKafkaConsumer09来获取主题中的消息flink-demo
本文源码Github
开源项目Nussknacker让你通过GUI设计流处理流程,类似工作流那种方式,实现流处理的设计、部署和监控。
大数据专题
Stream流处理专题
Apache Kafka专题