大数据专题
构建实时流数据平台实践指南
如今流处理stream processing,事件数据和实时等词语非常流行,它们经常和 Kafka, Storm, Samza, 以及 Spark的 Streaming module等具体技术有关,本指南是介绍如何将这些技术堆栈架构到具体实践中。这些最佳实践经验来自于LinkedIn。
在LinkedIn使用Apache Kafka建立一个数据流中央仓储,但是为什么这么做呢?有两个动机“首先,解决系统之间的数据传输问题,LinkedIn有很多数据系统:实时OLTP数据库,Hadoop. Teradate和搜索系统,监控系统以及OLAP存储和衍生的key-value存储,这些分布在不同地理位置的系统需要一个可靠的数据输入,这个问题称为数据集成,也可以叫ETL。
其次,需要实现更丰富的数据分析处理,通常会在数据仓库和Hadoop集群中进行,但是必须是有非常低的延迟,也就是实时高性能,称为流处理Stream processing,也可以称为消息,或CEP。
之前LinkedIn没有注重这个问题,只是根据逐渐演化地建立系统之间的异步连接,随着时间推移,这种系统越来越复杂,如下图,于是结束了这种在系统之间建立管道的方式:
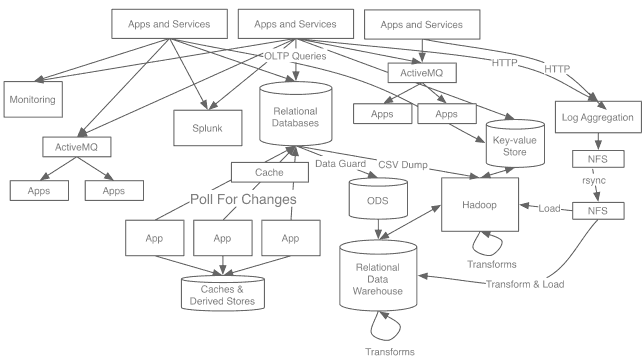
这些不同管道都有不同问题特点,日志管道是可扩展的但是会有丢失,只能传导高延迟的数据,Oracle实例之间管道是快速精确实时的,但是这种快速精确无法对其他系统开放可用,Hadoop的Oracle数据管道是周期的CSV导出,这是高吞吐量的批处理;搜索系统的数据管道是低延迟,但是不可扩展,紧紧和数据库耦合在一起;消息系统是低延迟但是不可靠且不可扩展。
当LinkedIn在全世界各地建立数据中心后,需要构建每个这些数据流的地理复制,由于这些系统的规模巨大,支持配套的管道架构也必须与之相适应。因此,建立一个简单的胶带式的管道会在处理扩展这些操作方面变得容易得多。更糟糕的是,复杂性意味着不可靠,报告不可靠,派生的指标和存储也就有问题,每个人花费了很多时间在各种数据质量问题解决上。
虽然Hadoop提供了一个批处理的数据平台,但是还缺乏一个类似但是有低延迟的系统,许多应用程序比如监测系统 搜索引擎 分析和安全以及欺诈分析需要的时间不能超过几秒钟。
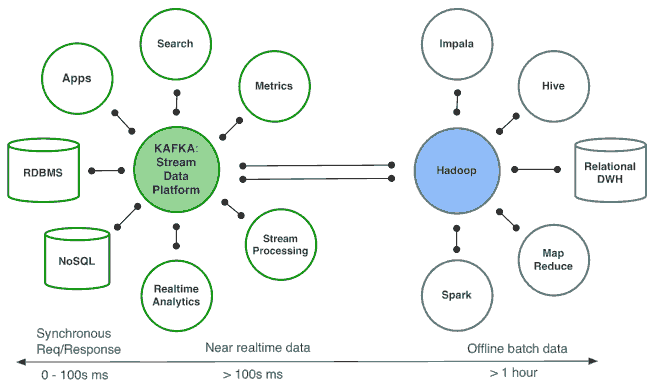
从2010年开始LinkedIn决定建立一个专门捕捉数据流的系统,实现系统之间的集成,提供实时数据流的处理,这是使用Apache Kafka的原始原因。
构想如下:
这样,LinkedIn的系统架构从之前丑陋的管道系统变为更加干净以数据流为中心的系统,如下:
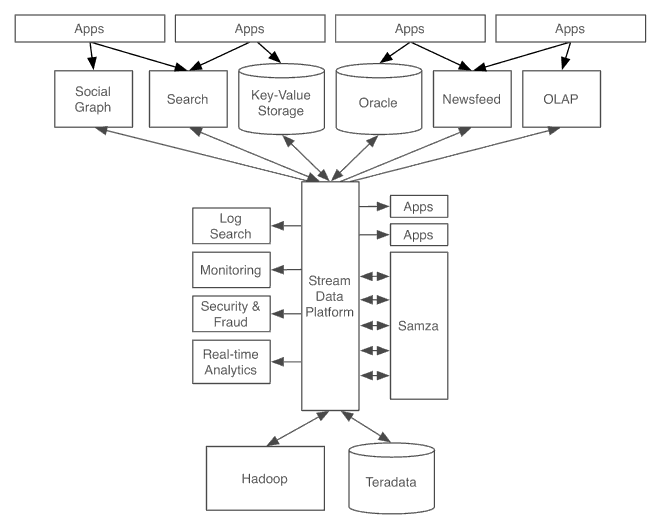
设置Kafka作为数据流的通用管道,每个系统能够反馈到中央管道(类似SOA中央总线ESB),应用系统或流处理器能够创建和传递新的数据流,然后再反馈到各种系统服务中,良好数据格式的持续送入在多个系统之间扮演了一种 lingua franca(通用语言)。
举例来说,如果一个用户更新了他的配置,那么这种更新也许会流入到这个流处理层,在那里会被处理成标准的公司信息 地理位置和其他该用户的配置属性,然后,流可能进入搜索索引和用于查询的社会图谱,也可能进入为推荐工作机会的匹配推荐系统,所有这些都是发生毫秒级别,这一流程将会加载到Hadoop中提供数据给数据仓库环境。
Kafka每天处理大概500 billion的事件,它已经成为各种系统之间的数据流骨干,成为Hadoop数据核心管道和流处理中心。