Flink实时流处理系统
什么是数据工程中的流处理?

数据流处理可分为三个不同的数据处理阶段: 收集 处理 呈现 让我们更详细地了解这三个阶段,并举例说明。步骤 1:收集数据要处理数据流,首先需要数据流!幸运的是,几乎所有数据都是以连续的方式产生的,将数.
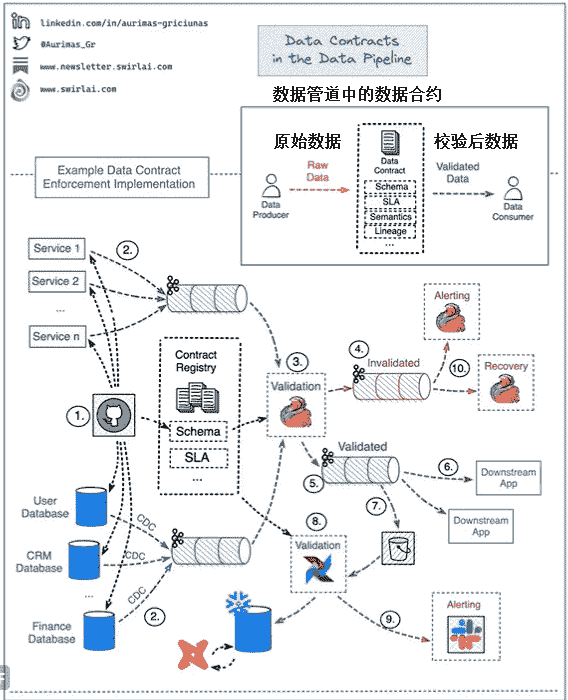
一张图解释数据合同如何实施
使用Flink实现Exactly-Once分布式事务 - Devora

如何在 Flink 中处理数据倾斜?

数据倾斜是指数据集的不平衡分布。这种不平衡通常是通过特定指标或领域的镜头观察到的。我们可以说一个国家的人口数据集在按人口中心分组时是有偏差的(假设更多的人住在几个大城市,而其他地方的人口较少)。这本身.
Apache Flink与Kafka Streams区别? - Gunnar

Apache Flink与Kafka Stream都能实现流处理,但在一些重要方面有所不同。下面是从用户的角度出发的,不涉及实现细节:支持的流平台不同 作为的Apache Kafka项目的一部分,Ka.
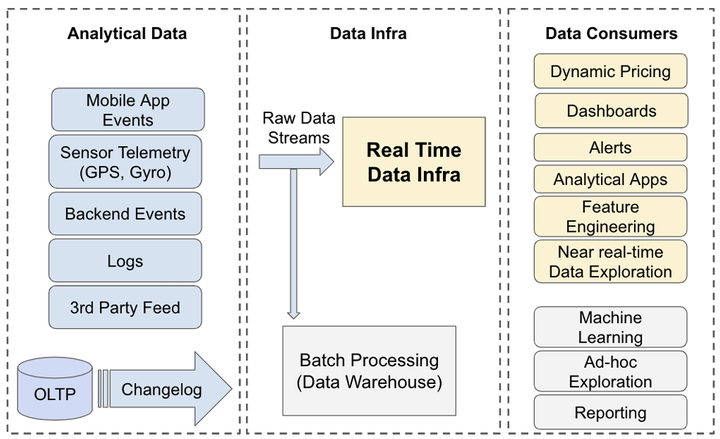
Uber实时数据基础设施:分布式计算架构
Apache Flink回应Akka许可证收费事件

Akka的新许可证给Apache Flink带来了许多问题,因为它在内部使用Akka 进行集群协调。但是,Apache Flink的许可证不会改变。将不会再使用 Akka 2.7+,这将确保用户不受影.
DoorDash使用 Kafka 和 Flink 构建可扩展的实时事件处理

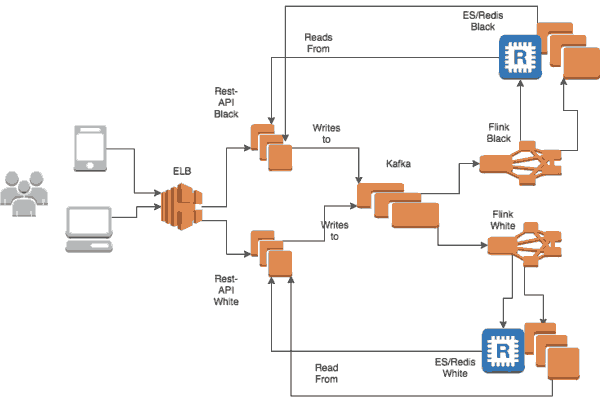
如何将Apache Druid,Flink和Cassandra用于实时流分析和用户评分?

在Deep.BI上,我们能够解决的最艰巨的挑战之一就是如何基于数十亿个数据点实时提供可自定义的洞察力,这些洞察力可以从单个角度全面扩展到多达数百万个用户。在Deep.BI,我们跟踪用户习惯,参与度,产.
Apache Flink复杂事件处理指南 - softwaremill

如今,流处理是一个非常流行的话题。公司处理成千上万个需要实时或近实时处理的事件。企业需要分析客户的行为,交易,股票价格变化甚至自动驾驶汽车传感器读数。但是,今天,我们要专注于复杂事件处理。 什么是复杂.
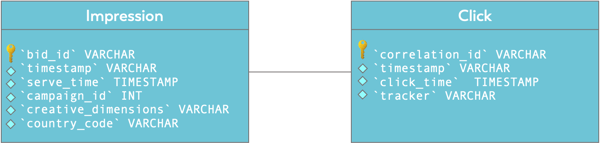
使用Flink SQL进行实时性能监控:AdTech广告用例
Eta中的Apache Flink示例

Apache Flink是一个大数据处理框架,允许程序员以非常有效和可扩展的方式处理大量数据。这是Eta中的一个简单的WordCount示例。Maven依赖文件中添加了maven依赖项flink-ja.
使用Apache Flink和Apache Ignit进行数据流分析

在本文中,我们将讨论如何使用Apache Flink和Apache Ignite构建数据流应用程序。构建数据流应用程序可以以优化和容错的方式将大量有限和无限量的数据提取到Ignite集群中。数据摄取率.
Drivetribe采取CQRS和Apache Flink的经验分享
实时流处理框架Apache Flink简介
