数据科学教程
本周Github有趣项目:draw-a-ui等

机器学习量化交易中四个陷阱

数据工程师 、数据科学和硬件工程师组成的团队在开发机器学习交易算法时,在四个关键点上可能会出现陷阱:- 在收集数据时,将使用新开发的算法- 在算法的设计过程中,当一个团队被组成来解决一个问题时,假设的.
最近金融量化交易的研究成果列表

基于 Shapley 的投资组合绩效方法:SPPC 方法可以确定单个预测变量对投资组合绩效的贡献,揭示回报可预测性的经济价值来源。(2023-11-09,股数:3.0)使用神经网络进行波动率建模:引入.
Salesforce中企业数据架构的设计原则

企业的运营依赖于数据——最好的组织都拥有强大的数据战略。Salesforce中的企业数据架构是:用于指导 Salesforce 组织中的数据管理的核心设计原则和框架。它可以帮助您确定数据的存储位置、数.
通过业务架构和IT架构提供价值

企业架构需要足够的资源来规划和映射适当的客户驱动的业务架构,但IT架构的3个领域不应被忽视,即应用程序/服务、信息/数据和技术/基础设施。企业架构中的业务架构领域不仅仅涉及业务功能和业务流程。最重要的.
开放、严谨和可重复的研究:从业者手册

数据分析和报告结果的开放、严格和可重复研究实践的实用指南这篇文章讨论了开放、严格和可重复研究的最佳实践。它强调仔细的研究设计以确保有效的结果,包括功效分析、区分探索性研究和验证性研究以及分析前规划。它.
大模型和知识图谱结合综述

大型语言模型 (LLM) 和知识图谱 (KG) 是互补技术,结合起来可以平衡彼此的优缺点:大模型具有很强的理解和生成自然语言的能力,但有时会产生幻觉事实。 KG 以结构化格式明确表示事实知识,但缺乏语.
ML算法对量化交易规则的处理
ML算法采用剪枝技术,通过排序、抽样和分类,去除多余或不重要的交易规则。这一过程的结果可分为四种情况。假设 "U "是交易者的数据集,"A "是发现的交易规则集: 符合规则:如果 A_i 的前因和后果.
大数据将图论带入新维度

我喜欢数学的原因是它基于逻辑,如果你遵循正确的方向,你就会得到正确的答案。但有时,当你定义全新的数学领域时,正确的方法存在主观性,如果你不认识到有多种方法可以做到这一点,你可能会将社区引向错误的方向。.
通用智能的五个特征
表征综合智能的五种方法:1、实用方法将通用智能与人类能力进行比较。如果一个系统可以自动完成人类为获取报酬而执行的大多数任务,那么它就具有通用智能。与图灵测试有关。2、心理学特征试图找出使人类具备实际能.
如何玩转推特X之类的社交算法?

过去玩转搜素技术能让普通人开挂,如今驾驭AI算法是开挂唯一方式:推特X几个月前发布了部分源代码,推友揭开它的所有秘密(以下算法适合微博、抖音和脸书之类社交媒体):X试图(通过研究你的行为)猜测你的以下.
比尔·盖茨表示GPT技术已经达到了平台期
微软创始人比尔·盖茨在接受德国商业报纸 Handelsblatt 采访时表示,有很多理由相信 GPT 技术已经达到了稳定水平。在 OpenAI 工作的“许多优秀人士”都相信 GPT-5 将明显优于GP.
数据科学的三个基础常识
每个数据科学家都需要了解这些观点,它们会让你大开眼界。1.相关性与因果关系P(A | B) 是指定 B 的 A 的概率。P(A | do(B)) 是给定 do(B) 的 A 的概率。它是在我们干预导致.
什么是GARCH模型及其陷阱?
广义自回归条件异方差 (GARCH) 是一种用于分析时间序列数据的统计模型,其中方差误差被认为是连续自相关的。GARCH 模型假设误差项的方差遵循自回归移动平均过程。要点: GARCH 是一种统计建模.
研究首次表明乌鸦能使用统计逻辑

arstechnica报道,一项新的研究表明,乌鸦能够基于统计推断进行复杂的推理:鸟类可以将图像与不同的奖励概率联系起来。图宾根大学(University of Tübingen)的研究人员首次发现,.
哈特奖:压缩算法竞赛奖
Hutter 奖是一项奖励智能压缩器/数据压缩程序开发的竞赛,目前总奖金为 23,034 欧元。目标是将 1GB 文件 enwik9 压缩到小于当前记录的约 114MB。根据所达到的压缩程度,获胜者有.
股票预测神经网络和机器学习示例
本项目是使用样本股票数据的 Python 神经网络和 ML 股票预测方法示例。ML 和 NN 方法和库的资料库,以及用于训练和测试的样本股数据。这些示例简单易懂,突出了每种方法的基本组成部分。示例还展.
腾讯使用大语言模型增强基于Doris的OLAP服务

腾讯利用大型语言模型 (LLM) 增强基于 Apache Doris 的 OLAP 服务腾讯采用大型语言模型 (LLM) 来增强其基于 Apache Doris 的 OLAP 服务。LLM作为将自然语.
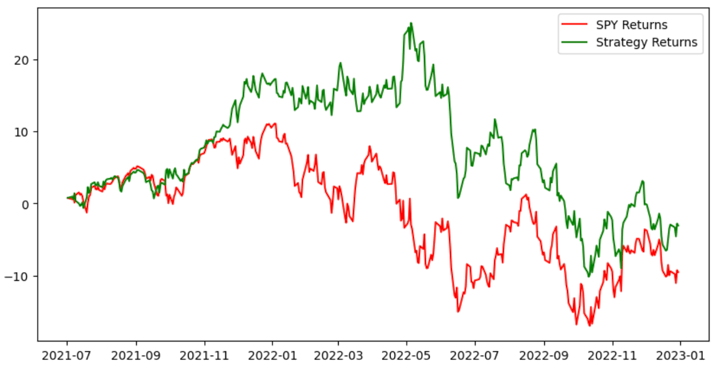
用Python实现KNN量化交易步骤
用 C++ 编写的自托管加密货币交易机器人(自动高频做市)

K是一系列(高度可定制的)极低延迟的做市交易机器人,具有功能齐全的网络界面。在一台像样的机器上,它可以在几个兼容的交易所之一下单和取消订单,每个订单的时间不到几毫秒。如果您不想在自己的机器上配置或硬编.
量化金融面试实用指南
如何在量化金融(主要侧重于交易)领域找到实习或应届毕业生职位。简历确保优化简历,将重点放在数学和数据科学上。如果你在高中时参加过数学竞赛,请务必在简历中注明,如果你的标准化考试成绩很高,请注明你的高中.
阿兰·图灵:数学符号表达的问题并不都能用算法解决

10个来之不易的AI产品教训
我是一家生成式人工智能咨询公司的创始人,我们为其他公司开发基于人工智能的产品。我们已经这样做了18个月了,我想我分享我们的经验-这可能会帮助其他人。跟上最新的工具和发展是一场永无止境的战斗。当你交付产.
OpenAI推出ChatGPT企业版
ChatGPT企业版现已推出,其功能如下: - 无限制访问GPT-4(无使用上限) - 针对GPT-4的更高速度性能(最多快2倍) - 无限制访问高级数据分析(代码解释器) - 32 k令牌上下文窗口.
分子生物学中的大语言模型
分子生物学的中心法则描绘了从基因组到基因表达和随后的蛋白质生产的分子信息流,蛋白质是生命的基本组成部分。基因组中有大约20,000个基因,这些基因是负责蛋白质合成的DNA片段。大约1%的基因组编码蛋白.
OpenAI向ChatGPT Plus用户推出Code Interpreter

这是OpenAI自GPT-4以来发布的最强大的功能。让每个人都成为数据分析师 以下是Code Interpreter的15个令人兴奋的用例:1、在几秒钟内细分您的客户需要一个电子表格,然后自行得出音乐.
什么是AI矢量数据库?
对于涉及大型语言模型、生成式人工智能和语义搜索的应用程序来说,高效的数据处理变得比以往任何时候都更加重要。所有这些新应用程序都依赖于矢量嵌入(vector embeddings),这是一种数据表示形式.
用知识图谱提取专业文献关键词

简洁地可视化和总结或“压缩”大约 10,000 个单词的百科全书式哲学文章,仅包含一组 24 个最常用的非通用单词。使用的主要工具是来自 Wolfram Function Repository 的Ke.
MotherDuck:大数据已死
十多年来,人们很难从他们的数据中获得可操作的洞察力,这一事实被归咎于其规模。诊断结果是 "你的数据对你那微不足道的系统来说太大了",而治疗方法是购买一些能够处理大规模的新的花哨的技术。当然,在大数据工.
pandas 2.0 新变化
Pandas 2.0来了!这是自Pandas诞生以来最大的一次大修,而且已经酝酿了多年。然而,你可能不会注意到太多的变化,你现有的Pandas代码很可能会像以前一样运行。所有的主要变化都在引擎盖下。这.