Hadoop大数据教程
Java中大数据生态和4个工具介绍

大数据 和 Java 形成强大的协同作用。大数据以其高 容量、 高速度和 多样性为特征,已成为各行业的游戏规则改变者。什么是大数据?使用传统数据处理技术难以处理和处理的异常大的数据集被称为“大数据”。.
2024年20大数据科学工具

企业数据变得越来越具有挑战性,并且由于它在战略规划和决策中发挥着关键作用,组织被迫在从数据资产中提取有用的业务洞察所需的人员、程序和技术上投入资金。当我们深入研究 2024 年时,数据科学工具的前景已.
Apache Spark:释放大数据力量

Apache Spark是一个强大的开源分布式计算系统,已成为大数据处理领域的基石。凭借其多功能的特性和强大的功能,Spark 已成为处理海量数据集的组织的首选解决方案。让我们探讨一下它的主要特性、优.
简单介绍Iceberg与数据湖屋由来

本文从数据存储格式的演变介绍了数据工程领域的大数据处理框架发展,从Hive到Iceberg、Delta Lake以及数据湖屋的发展过程:数据如何存储(在文件和内存中)开源文件格式(如Avro、Parq.
2023年游戏数据流的状况
这篇博文探讨了 2023 年游戏行业的数据流状态。包括来自 Kakao Games、Mobile Premier League (MLP)、Demonware / Blizzard 等的客户案例。休闲.
可组合数据系统之路:对过去15年和未来的思考

来自韦斯·麦金尼文章:15年前,也就是2008年4月,我开始构建数据分析工具。我当时所感知到的是数据科学的迫切“Python化”。这不仅是为了让新一代的数据从业者更容易获得数据科学,也是为了让现有的数.
Uber如何实现互联网大规模金融交易的自动化审计?

假设乘客于 2022 年 1 月从家到机场,费用为 60 美元。6-7 个月后,乘客再次从家到机场,但现在需支付 50 美元。在这两次行程中,乘客都使用了具有相同出发地和目的地的 UberX。现在,用.
Apache Flink 是实时流处理的行业标准

在 Decodable,我们长期以来一直认为Apache Flink是最好的流处理系统,在满足世界上一些最大和最复杂的企业(如 Netflix、Uber、Stripe 等)的需求方面有着良好的记录。未.
Druid:实时分析数据存储
Apache Druid是一个开源数据库,专为低延迟的近实时和历史数据分析而设计,Druid 被Netflix、Confluent和Lyft等公司用于各种不同的用例。这个领域有Clickhouse、t.
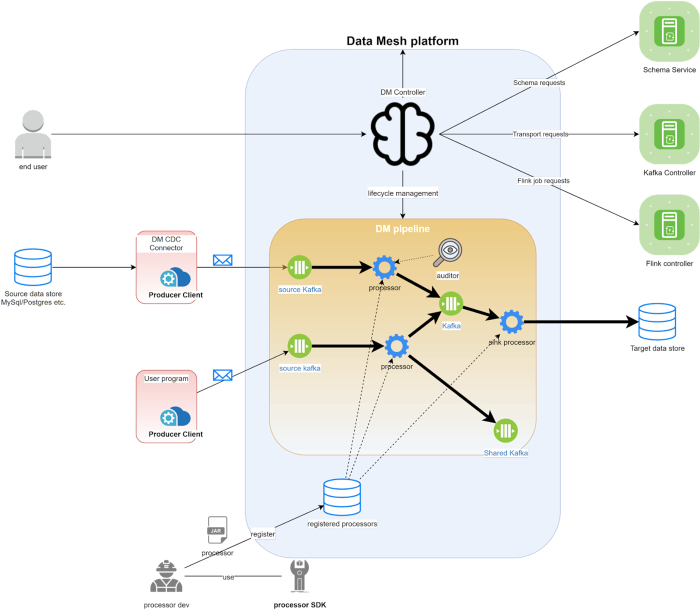
Uber实时数据基础设施:分布式计算架构
Dagster使用DuckDB从头构建一个穷人的数据湖

数据的价值与数据的新近程度成正比。我们可以使用内存数据库来提高速度和价值生成吗?DuckDB 在这一承诺上获得了很多关注,Dagster 团队撰写了关于其建立在 DuckDB、Parquet 和 Da.
超级表:领英构建可靠和可发现的数据产品之路

正如 LinkedIn 数据团队所述,自从十年前采用 Apache Hadoop 以来,包括 LinkedIn 在内的许多公司都经历了指数级的数据增长。随着自助数据创作工具和发布平台的激增,不同的团队.
下一代五个一体化数据平台比较
多合一数据堆栈是未来吗?Ben 的文章来得正是时候,因为 dbt 揭开了语义层的面纱,成为了分析生态系统的枢纽。作者比较了五个可用的一体化数据平台,并讨论了它们的优缺点。现代数据堆栈在 2020 年和.
Apache Atlas为企业提供元数据管理和治理能力
当时Hortonworks的Apache Atlas项目加入了Apache孵化器项目,专注于为企业提供开放的元数据管理和治理能力,以建立其数据资产的目录,对这些资产进行分类和治理,并为数据科学家、分析.
Snowflake和Databricks比较 - John
应该选择 Snowflake 还是 Databricks?Snowflake 和 Databricks 都是很棒的组织。他们发明或重新发明了数据管理行业。我不会贬低他们的任何技术、人员或流程。然而,他.
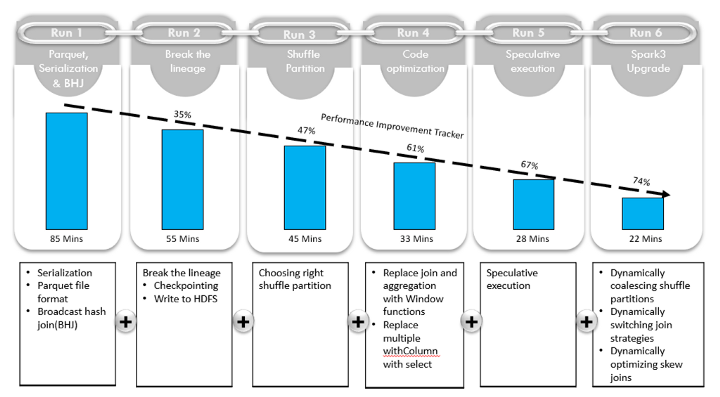
使用 Spark 优化加速大数据处理 - Gaurav
Schema Ops是数据合约更好的命名? - Ananth

在过去的几周里,数据合约一直是一个热门话题: Chad 发表了数据合约的工程指南, Jake 发表了合约驱动的平台, David 发表了关于数据合约的三部分系列 Yali Sassoon 发表了为什么.
Apache Iceber能将Amazon S3 成本降低了 90%
与Apache Hive相比,新一代数据湖表格式(Apache Hudi、Apache Iceberg和Delta Lake)凭借其卓越的功能每天都在受到越来越多的关注。它们为具有 ACID 事务、模.
有状态流处理和流数据库两种数据处理方式比较

长期以来,在有状态流处理器和流数据库之间进行选择一直是一个有争议的问题。一个流处理应用程序是一个DAG(直接无环图),其中每个节点是一个处理步骤。你通过编写单独的处理函数来编写DAG,这些函数在数据流.
批处理中的数据质量如何保证? - Weingarten
下面是我在尼尔森工作时的实现,这在 Airflow 中使用 Soda 来实施数据质量检查的博客类似。当我在尼尔森时,还没有一个数据质量的总体框架或平台,所以我们“开发”的只是内部供我们自己使用。我们决.
Claimforce为何使用湖仓统一数据湖和数据仓库?

在 Claimforce,我们最初的大数据方法是一个两层架构,包括 Amazon S3 中的数据湖阶段和 Amazon Redshift 中的数据仓库阶段(此处概述)。随着时间的推移,我们意识到拥有两.
Apache Iceberg 英文学习资料
Apache Iceberg 是一种开源数据湖库表格式,已席卷大数据分析世界。 在本文中,您将找到一个 101 视频课程,以及您在概念和实践方面快速了解 Apache Iceberg 所需的所有资源的.
数据摄取的 7 个最佳实践
“数据工程是 2022 年最性感的新工作”它在需求和职业机会方面已经超过了数据科学。如果您还没有看到对数据工程的需求呈天文数字增长,那么您很可能在过去 2 年都生活在山洞里。到底是什么炒作?为了试图回.
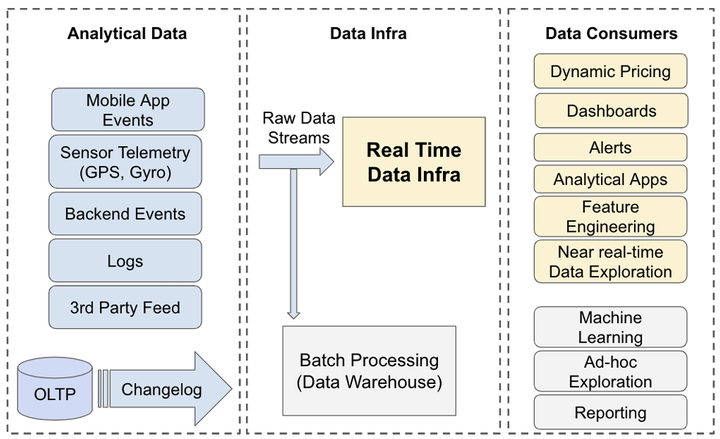
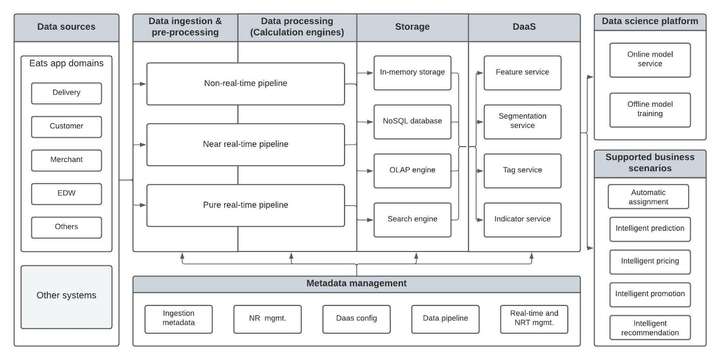
Eats数据平台:用数据赋能企业
沃尔玛如何使用 Apache Hudi 和 Spark 实现 SCD-2(渐变维度)?
数据是当今分析世界的宝贵资产。在向最终用户提供数据时,跟踪数据在一段时间内的变化非常重要。渐变维度 (SCD) 是随时间推移存储和管理当前和历史数据的维度。在 SCD 的类型中,我们将特别关注类型 2.
数据架构的演变
数据与业务运营和各种分析工作负载(BI、数据科学、认知解决方案等)的分离与 IT 系统和业务应用程序一样古老。由于分析工作负载是资源密集型的,因此需要将它们与运行业务运营的 IT 系统分开,以便运营工.
数据湖仓比较:Apache Hudi、Delta Lake、Apache Iceberg
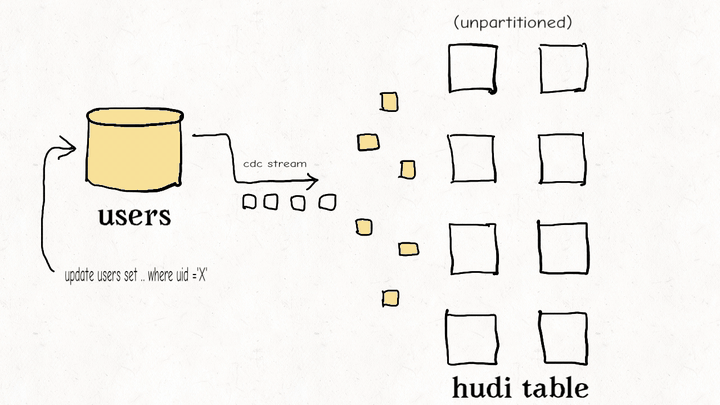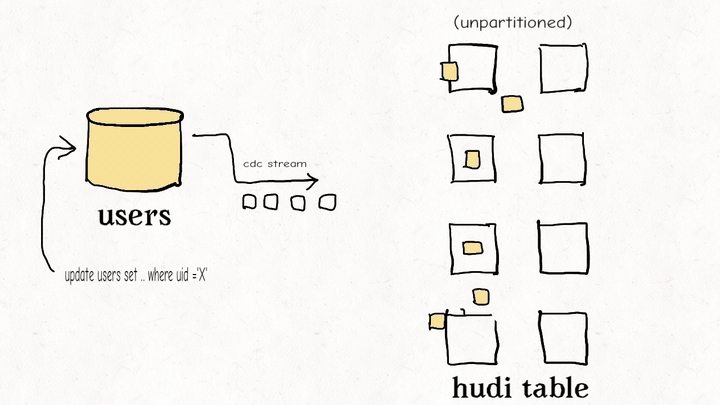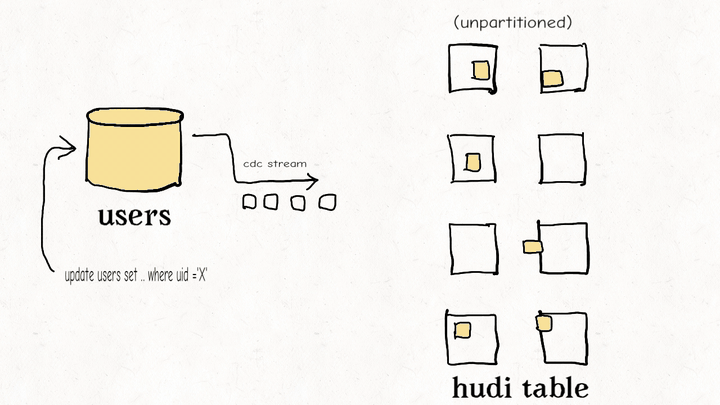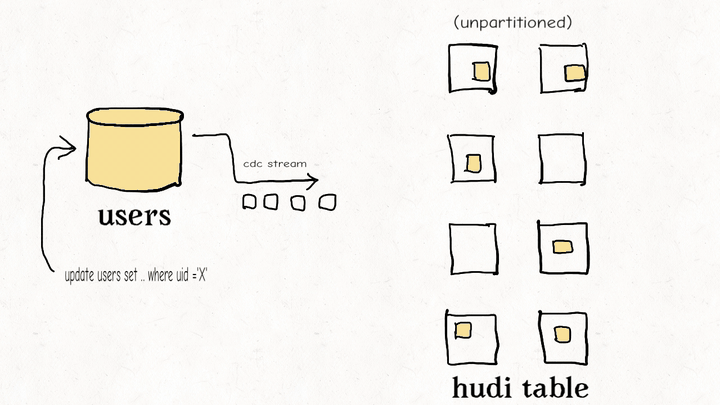
Schemata:分散式的数据结构建模框架
自从 Hadoop 和 MapReduce 诞生以来,数据工程社区一直非常关注数据转换的商品化。所有 Hadoop 抽象,如 Hive、Pig、Crunch 等。在 Hadoop 之上构建以进一步简化.
贝宝:基于DDD的下一代数据平台是数据网格
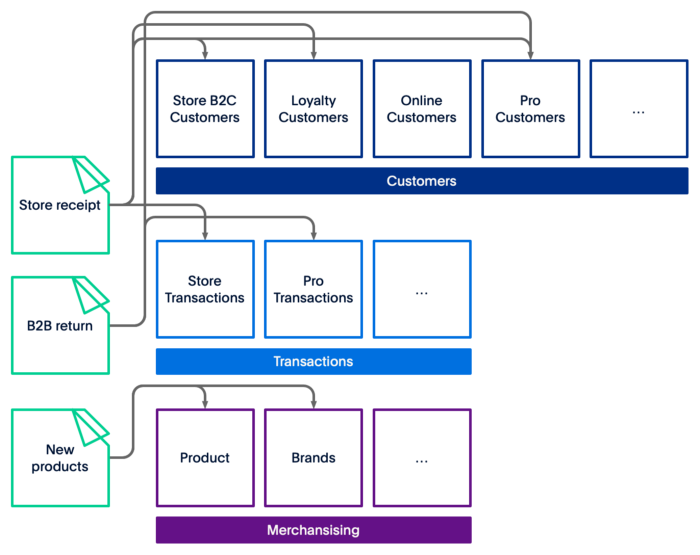
奈飞的数据网格是什么样?