Apache Kafka简单介绍
本文将首先简要介绍Kafka卡夫卡,通过一个示例场景演示其一些独特的功能。帮助大家初步了解其主要特点。
Kafka是一个分布式发布-订阅publish-subscribe消息传递系统,设计目标是快速、可伸缩和耐用冗余。它是一个在一个较高的抽象水平上描述的但是又非常简单的系统,虽然当你更深地挖掘时会令人难以置信的技术细节。卡夫卡文档出色的解释了系统中许多设计和实现的微妙之处,所以我们不会在这里试图解释他们了。
像许多发布-订阅消息传递系统,卡夫卡能保存源消息的数据。生产者将输入写入到主题topic,而消费者则从主题topic中读取写入数据。因为卡夫卡是一个分布式系统,所以topic主题会实现跨多个节点分区和复制。
消息是简单byte数组,开发者能够使用它们存在对象的任何格式,如String或JSON和Avro,每个消息能够有一个Key,因此,生产者保证拥有相同key的消息到达同一个分区,而对主题topic的消费,可以使用多个消费者来配置消费组,每个消费组中消费者能够从他订阅的那个主题Topic所在分区子集中读取消息,这样每个消息发送给消费组中一个消费者,使用相同key的所有消息能够到达相同的消费者。
Kafka的特点是它将每个主题topic分区都看成一个日志log(一个有顺序的消息集合),一个分区中的每个消息被分配一个唯一的偏移量offset. Kafka并不试图跟踪哪个消息被哪个消费者读取,而是只是保留未被读取的消息。 Kafka保留所有消息的时间,而消费者负责跟踪它们在每个日志(日志是一个消息序列集合代表一个topic分区)中的位置, 因此Kafka能够支持大量的消费者,使用最小的代价保留大量的数据。
Kafka如何工作?
假设我们正在开发一个大型多人在线游戏。在这些游戏中,玩家在一个虚拟的世界中互相合作和竞争。通常玩家互相发生贸易,比如交换物品和金钱,所以游戏开发者重要的是要确保球员不会欺骗,在下面两种情况下的交易将标记为特殊:如果贸易数量明显大于正常的球员;如果IP玩家登录是不同于过去的20场比赛使用的IP。除了对实时交易进行标记以外,我们也想加载数据到Apache Hadoop,我们的数据,科学家们可以用它来训练和测试新算法。
基于游戏服务器内存数据缓存进行实时事件标记是最好的,能够让我们达到迅速决定,特别是对那些最活跃玩家。如果我们分区游戏服务器,我们的系统有多个游戏服务器和数据集,,包括过去登录的20个玩家和近20在内存的交易,。
我们的游戏服务器必须执行两个截然不同的角色:第一个是接受和执行用户操作,第二是实时处理贸易信息并标记可疑事件。为了有效执行第二个角色功能,每个用户整个贸易的历史事件都驻留在一个单独的服务器内存中。因为接收用户操作(第一个角色功能)的服务器可能没有他的贸易历史,这意味着我们必须通过服务器之间的消息实现第二个角色功能。为了让两个角色功能保持松散耦合,我们使用卡夫卡在服务器之间传递消息,您将看到如下:
卡夫卡有几个特性::可伸缩性、数据分区,低延迟,并且能够处理大量不同的消费者。我们为登录和交易配置了一个Topic主题。我们把它们配置成一个topic主题的原因是:只有我们获得已经登录信息(我们可以确保玩家从他平时IP登录)后,才能确保他的交易是有效的。卡夫卡可以在在一个主题topic中维护这个前后顺序,而不是在两个topic之间。
当用户登录后进行交易,接受服务器立即发送事件到Kafka. 消息是将user id作为key, 事件作为值. 这能确保同一个用户的所有交易和登录发送到Kafka同样的分区. 每个事件处理服务器都运行一个Kafka消费者, 其每个消费者都被配置为同样组的一部分,这样,每个服务器从少量Kafka分区读取消息,所有关于某个特定用户的数据都能发往相同事件处理服务器,当事件处理服务器从Kafka读取一个用户交易时,将这个事件加入到用户事件历史缓存本地内存缓存,这样就无需额外网络磁盘开销直接标记那些可以事件。
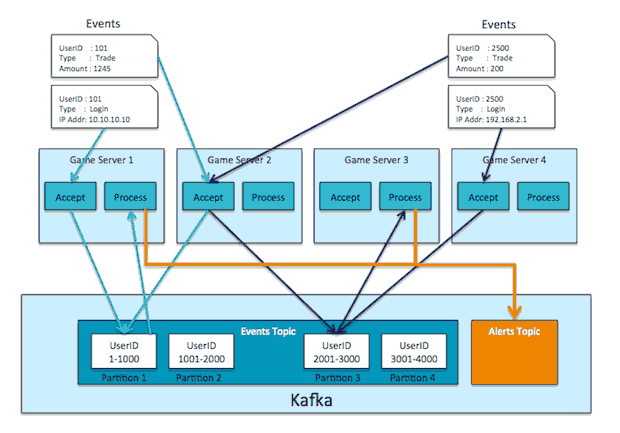
重要的是我们为每个事件处理服务器创建一个分区,或者每个事件处理服务器上每核对应一个多线程应用,(记住 Kafka大部分是用少于 10,000 个分区实现所有主题topic,这样我们不能为每个用户创建一个分区,因为用户数是不断增加的。)
这好像是一种迂回方式处理事件:从游戏服务器发送事件到Kafka, 另外一台服务器读取这个事件再处理它,这种设计解耦了两种角色功能,允许我们为每个角色功能安排其需要的容量与能力。.另外,这样做不会增加处理时间,因为Kafka是设计为高吞吐量和低延迟的,即使只有一个小的三台节点服务器的集群环境,也能每秒处理接近一百万个事件,平均延迟只有3ms.
当服务器标识出一个事件作为可疑,它会发送这个标记了的事件到新的Kafka topic,比如其主题名称为Alerts,这时报警服务器或仪表监控服务器会接受到这个事件,同时另外一个单独过程会从Alerts主题中读取这个事件,将它写入到Hadoop进行更进一步分析。
因为Kafka并不跟踪确认每个消费者的消息,它就能用很少的性能影响处理成千上万的消费者。Kafka甚至可以处理批量消费者:每一个小时处理过程唤醒激活处理一个队列中所有消息,根本就不会影响系统的吞吐量或延迟。
其他案例
Kafka还可以作为一个传统的消息代理broker集成事件到Hadoop.
这里是其一些普通用途:
- 网站活动跟踪Website activity tracking:Web应用发送事件如页浏览量或搜索到Kafka,这样这些事件能够被hadoop实时处理和分析。
- 操作衡量Operational metrics: 实现操作监控的警报和报表,Kafka可以偶尔发送它们的消息总数到一个特定的主题,这样有一个服务就可以比较这些总数,如果数据丢失可以报警。
- 记录聚合Log aggregation: Kafka能够用于跨组织从多个服务收集日志,然后以一种标准格式提供给多个消费者,包括Hadoop 和Apache Solr.
- 流处理Stream processing: 类似Spark Streaming能从一个主题读取数据处理然后写入数据到一个新的主题,这样被其他应用再次利用,Kafka的强壮的durability(不丢失 持久性)对已流处理是非常有用的。
其他系统只能做这些其中之一,不像Kafka全部都做得好,ActiveMQ 和 RabbitMQ是非常流行的消息中间件broker系统,Apache Flume是用于摄取事件 日志和计量到Hadoop.
Kafka和Flume区别
Kafka卡夫卡开始来简化数据摄取Hadoop。当有多个数据来源和目的地,为每个源和目标设计一个单独的的数据管道配对迅速发展的系统来说会导致一个不可维护的混乱。卡夫卡帮助LinkedIn标准化其数据管道,允许每个系统一次获取数据,大大降低了管道的操作复杂性和成本。
卡夫卡是一个通用的系统。你可以有许多生产者和许多消费者共享多个主题。相比之下,Flume是一个旨在HDFS,HBase中发送数据的专用工具。它有与Hadoop的HDFS特定的优化,它集成了安全。
Flume可以使用拦截器动态处理数据。这些可以对数据屏蔽或过滤是非常有用的。卡夫卡需要外部流处理系统。
Kafka和Flume都是可靠的系统,可以通过适当的配置能保证零数据丢失。然而,Flume并不复制事件。因此,即使使用可靠文件通道,如果Flume节点代理崩溃,你将失去访问事件通道,直到你恢复磁盘。如果你需要摄取管道具有很高的可用性使用Kafka。
开源消息系统Apache Kafka, RabbitMQ和NATS比较