Hadoop2.2和Yarn安装教程
Hadoop 2.2新特性
将Mapreduce框架升级到Apache YARN,YARN将Map reduce工作区分为两个:JobTracker组件:实现资源管理和任务JOB;计划/监视组件:划分到单独应用中。
使用MapReduce的2.0,开发人员现在可以直接Hadoop内部基于构建应用程序。Hadoop2.2也已经在微软widnows上支持。
YARN带来了:
1.HDFS的高可靠性
2.HDFS snapshots快照
3.支持HDFS中的 NFSv3 文件系统。
Yarn/map reduce2.0架构图:
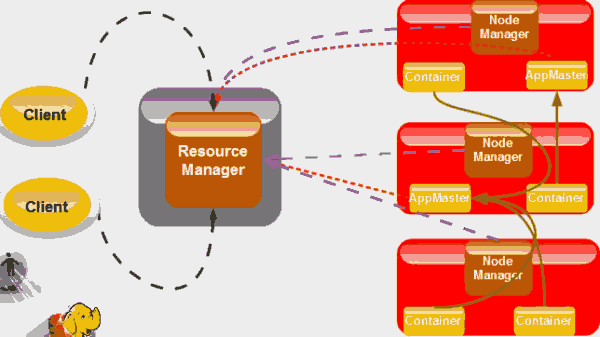
其中灰绿的箭头是Mapreduce处理流程,黑色虚线是任务Job提交,由客户端提交给RM,由各个节点发出资源请求到RM获取,当然他们也将各自的状态反馈到到RM。
安装Hadoop 2.2
从http://mirror.metrocast.net/apache/hadoop/common/stable2/下载。百度云盘下载。
解压到/home/hduser/yarn目录,假设hadoop是用户名。
$ tar -xvzf hadoop-2.2.0.tar.gz
$ mv hadoop-2.2.0 /home/hadoop/yarn/hadoop-2.2.0
$ cd /home/hadoop/yarn
$ sudo chown -R hadoop:hadoop hadoop-2.2.0
$ sudo chmod -R 755 hadoop-2.2.0
在~/.bashrc设置环境,将下面加入:
export HADOOP_HOME=$HOME/Programs/Hadoop/hadoop-2.2.0
export HADOOP_MAPRED_HOME=$HOME/Programs/Hadoop/hadoop-2.2.0
export HADOOP_COMMON_HOME=$HOME/Programs/Hadoop/hadoop-2.2.0
export HADOOP_HDFS_HOME=$HOME/Programs/Hadoop/hadoop-2.2.0
export YARN_HOME=$HOME/Programs/Hadoop/hadoop-2.2.0
export HADOOP_CONF_DIR=$HOME/Programs/Hadoop/hadoop-2.2.0/etc/hadoop
$ source ~/.bashrc
创建Hadoop数据目录:
$ mkdir -p $HOME/yarn/yarn_data/hdfs/namenode
$ mkdir -p $HOME/yarn/yarn_data/hdfs/datanode
配置:
$ cd $YARN_HOME
$ vi etc/hadoop/yarn-site.xml
编辑 yarn-site.xml
div id="PAGE_AD_1">
加入下面喊在yarn-site.xml:
#etc/hadoop/yarn-site.xml .
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
单个集群节点设置:
$ vi etc/hadoop/core-site.xml
加入下面内容在配置
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
$ vi etc/hadoop/hdfs-site.xml
加入下面内容
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/yarn/yarn_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/yarn/yarn_data/hdfs/datanode</value>
</property>
$ vi etc/hadoop/mapred-site.xml
如果这个文件不存在,创建,拷贝粘贴下面的配置。
<?xml version="1.0"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
格式化namenode(Onetime Process)
$ bin/hadoop namenode -format
启动HDFS处理和Map-Reduce 处理:
# HDFS(NameNode & DataNode)部分:
$ sbin/hadoop-daemon.sh start namenode
$ sbin/hadoop-daemon.sh start datanode
# MR(Resource Manager, Node Manager & Job History Server).部分:
$ sbin/yarn-daemon.sh start resourcemanager
$ sbin/yarn-daemon.sh start nodemanager
$ sbin/mr-jobhistory-daemon.sh start historyserver
确认安装:
$ jps
# 应该输出:
22844 Jps
28711 DataNode
29281 JobHistoryServer
28887 ResourceManager
29022 NodeManager
28180 NameNode
运行wordcount单词计数案例:
$ mkdir input
$ cat > input/file
This is word count example
using hadoop 2.2.0
将目录加入hadoop:
$ bin/hadoop hdfs -copyFromLocal input /input
在HADOOP_HOME运行wordcount案例::
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /input /output
检查输出:
$ bin/hadoop dfs -cat /out/*
This 2
Another 1
is 2
line 1
one 2
检查WebUI,浏览器打开端口:http://localhost:50070
可以在http://localhost:8088检查应用程序的状态.