分析和审计工作流对于大规模操作数据管道至关重要。过去,我尝试使用“airflow.log”表和“profiling”功能来实现相同的目的。令人惊讶的是,Airflow 配置文件和日志表并没有广泛流行。我很高兴看到 Apache Hop 将其添加为与信息日志框架的集成功能。
为什么要记录执行信息?
执行信息记录是Apache Hop 2.1.0 版本中的主要新特性之一。什么是执行信息日志记录,它对 Apache Hop 用户有何帮助?
开发工作流和管道是成功数据项目的一个重要方面。但是,任何数据项目的目标都是部署到生产环境并重复正确地处理数据。
Apache Hop 可以帮助您确保您的数据工作流和管道完全做到这一点:专注于您想要处理数据的方式,而不是如何通过可视化设计,通过单元测试验证您的数据是否完全按照您想要的方式处理,管理您的通过代码(项目)和配置(环境)的分离来实现项目的生命周期。
所有这些操作都可以让您主动工作:可视化设计可以让您构建易于理解的管道,项目和环境可以帮助您快速轻松地部署到多个环境,单元测试可以让您针对您知道或预期的问题场景构建测试。
虽然主动工作非常好,而且绝对必要,但也不能忽视被动地找出正在发生的事情。在 Apache Hop 中基本的日志记录和监控已经成为可能,但是 2.1.0 有了一个重大飞跃,引入了一个新的执行信息和数据分析平台。
找出工作流和管道执行期间发生的事情对于了解数据如何在项目中流动至关重要。新的执行信息平台正是这样做的。
如何运作?
顾名思义,执行信息记录允许 Hop 用户存储工作流和管道执行信息,但还有更多。 其实还有很多。让我们仔细看看。
新的工作流和管道执行平台将实际的工作流或管道执行与执行它的客户端(Hop Gui、hop-run、Hop Server)分离。例如,您现在可以通过 hop-run 在远程服务器上启动管道,并通过 Hop Gui 跟进其进度。
执行信息和数据分析为您的 Apache Hop 安装添加了各种新的元数据项和元数据选项:
- 元数据透视图中的 2 种新元数据类型:
- 执行数据配置文件允许您配置要使用的多个数据采样器。可用的采样器让您指定第一行、最后一行或随机行,并让您配置分析:包括最小值、最大值、空值等
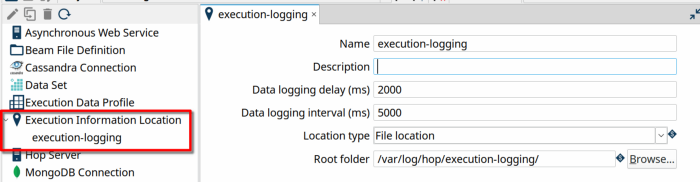
- 执行信息位置可让您配置要收集执行信息的位置和延迟、间隔和行大小。当前支持的位置是本地文件系统或远程 Hop 服务器和 Neo4j 图形数据库上的文件夹。
- Pipeline 和 Workflow Run Configurations 现在有新的选项来配置我们刚刚讨论的执行数据配置文件和信息位置:
- 执行信息位置(工作流程和管道):选择执行信息位置,如元数据透视图中指定的那样(请参阅上面的元数据类型)
- 执行数据配置文件(仅限管道):与此管道运行配置一起使用的执行数据配置文件。
- 全新的执行信息透视图允许您探索以前的工作流和管道执行。此透视图可让您详细调查工作流或管道的先前执行情况,包括使用的参数和变量、执行时间、数据配置文件等。该透视图还允许您从给定的工作流或管道向上或向下钻取到其父级或子项。所有执行信息都可用,因为它在执行期间在 Hop 的内部。
- 新的执行信息 转换可让您回读以前收集的执行信息以进行进一步分析。
执行信息演练
我们将介绍在本地系统上捕获执行信息和数据分析的基本步骤,并在一些执行后探索结果。
如前所述,我们将首先为执行信息位置和执行数据配置文件创建元数据项。
执行信息位置元数据类型采用几个参数:
- Name:此执行信息位置的名称。此名称将用于指代此位置。
- 描述:用于此执行信息位置的描述
- 数据记录延迟(毫秒):此延迟决定了 Hop 在开始写入记录信息之前将等待多长时间(以毫秒为单位)。
- 数据记录间隔(毫秒):此间隔确定在写入下一组记录信息之前 Hop 将等待多长时间(以毫秒为单位)
- 数据记录大小(行):
- 位置类型:执行信息要么记录在本地文件系统上,要么发送到远程服务器。
- 文件位置是您的执行信息将作为一组 JSON 文件存储在其中的根文件夹,每次执行都存储在一个散列文件夹中。
- 如果您选择Remote Location,则需要指定 Hop Server 和该服务器上的执行信息位置。服务器上此远程执行信息位置的配置将确定您的执行日志将写入的位置。
创建数据配置文件类似:右键单击元数据透视图中的“执行数据配置文件”,然后点击“新建”。在下面的示例中为您的数据配置文件命名为“local-data-profile”,然后添加您需要的采样器。我们在下面的示例中添加了所有可用的采样器,并带有默认选项。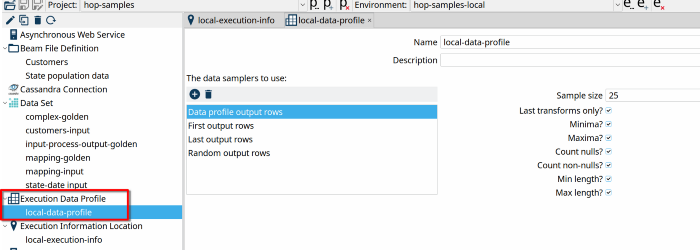
我们需要做的最后一件事是在管道和工作流运行配置中启用执行日志记录和数据分析。在本示例中,我们将使用 Hop 的本机引擎,但相同的配置选项可用于任何受支持的 Beam 管道引擎。
打开您的本地运行配置设置(右键单击 -> 编辑或双击)并选择我们刚刚创建的执行信息位置和执行数据配置文件。您的工作流运行配置设置类似,唯一的区别是数据分析不适用于工作流运行配置。
您现在已准备好开始收集日志记录信息和数据分析信息。运行多个工作流和管道后,您将在配置的文件夹中获得执行日志记录和数据分析信息。
切换到 Execution Information 透视图以探索您刚刚捕获的信息。
在此示例中,我们从示例项目中运行了几个管道:
执行信息提供了大量信息:
工作流或管道视图允许您向上或向下钻取到父或子管道或工作流。选择一个动作或转换并点击向上或向下钻取图标以转到父级或子级执行。向上和向下钻取按钮左侧的箭头按钮可将您直接带到工作流或管道编辑器。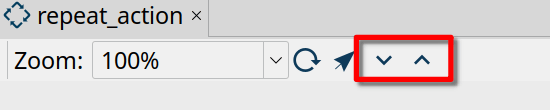
在透视图的下半部分,您会找到 Info、Log、metrics(仅限管道)和 data 选项卡:
- Info包含有关您的工作流或管道执行的执行信息:除了名称、ID 和父级(如果可用)之外,您还可以找到开始和结束日期及其状态。
- 日志包含工作流或管道的完整日志输出
- 指标(仅限管道)包含为管道中的特定转换收集的指标
- 数据包含所选转换或操作的分析数据。
- all-transforms-data.json包含管道中转换的分析数据
- execution.json包含信息选项卡中显示的信息
- workflow-log.txt或pipeline-log.txt包含工作流或管道执行的完整日志
- state.json在执行期间跟踪工作流或管道状态。