在处理数据和分析用户与我们今天的产品的互动时,必须通过跟踪他们过去的行为来了解他们的行为,如打开通知、与博客互动或在平台上创建新的登录。在这种情况下,归因研究指的是将所有这些行为按特定模式组合在一起,以产生一个预期的最终结果的方法。
在本文的范围内,我们的主要目标是在Business Studio中从我们的酒店经营者那里产生新的活跃活动。
在我们开始之前,让我们定义一下事件、渠道和路径的概念。在这篇文章中,我们将把事件称为任何类型的用户与公司产品的互动,这种互动在我们的数据库中被跟踪和登记。这可能是多种类型的活动,如查看通知、打开电子邮件、在个人资料中添加新酒店或首次进入网站。
渠道是事件发生的环境,可以是博客、社交媒体、主仪表板或任何其他对企业有意义的背景。
路径是一连串按时间顺序发生的事件,它定义了一个独特的行为。因此,如果用户检查了博客,打开了电子邮件,然后在网站上开始了新的订阅,我们就有一个事件的路径,如检查博客>打开电子邮件>开始订阅活动。
考虑到这一点,也有一个事件归属的想法。为了检查所有触发一个新活动的路径,有必要访问背后的历史数据,并检查就在这个触发事件之前发生的每个事件。然而,在触发事件之前检查哪些和多少事件,或者在触发事件之前检查多少天,取决于业务战略和数据科学家对可用信息的选择。
路径归因的类型
在这里,我将分享一些最流行、最常见的归因模型,然后介绍多触点归因模型的应用,以及根据触发特定事件的几率对用户的行为进行评分的最简单方法。
1、最后一次接触归因模型
这是默认的,也是数字营销中最常用的方法。在这种情况下,被触发的主要事件的归因会归于在它之前发生的最近的渠道事件。因此,如果我们认为触发事件是购买一个副产品,如果之前的追踪事件是用户对Facebook广告的点击,那么这个事件将获得100%的归因。如果你第一次开始实施归因模型,特别是如果你工作的产品购买周期很短,这是一个很好的方法,这意味着将有更少的可能过去的渠道来接收触发的主要事件的归因。如果花在广告上的钱价值很高(每月超过50,000美元),则不建议使用最后接触归因模型。在这些情况下,有一种投资于多个渠道的趋势,最好是分析用户路径中每个渠道的效率,而不是只关注最后一个渠道。如果产品有大量的有机流量或购买周期长,也最好避免这种模式。
2、首次接触归因模型
对于这种类型的模型,触发事件发生的原因的所有归因都来自于用户时间线上的第一个事件。在营销方面,一个电子邮件活动开始了,或者一个广告被设置为用户开始行动。如果在几个事件之后,他们开始了新的订阅,我们认为归因100%来自第一个事件。如果你与很多顶部漏斗营销渠道合作,例如SEO、博客,以及涉及将大量客户拉入公司主网站或仪表盘的营销,这种方法很有效。
然而,如果你需要每天更新之前的渠道,并且用户和平台之间的第一次互动不像以前那样相关,那么第一次触摸归因模型可能不是最好的选择。在这种情况下,最近的活动更有针对性,可以增加触发主要事件的几率。
3、线性归因模型
线性归因模型对所有以前的渠道给予同等的归因份额。这意味着我们不对活动的数量或其与购买的密切程度分配任何权重。如果产品有一个非常复杂的购买周期,这是一个很好的模型。意味着,很难定义每个事件的价值,或者如果你正在处理非常小的渠道,没有保留很多数据。
如果有几个频道比其他频道更有优势,这不是最好的选择,因为较小的频道会得到更多的荣誉。如果用户的时间线有空隙,也不建议这样做。这意味着一些重要的事件没有被长期跟踪,某些渠道获得了太多的信用。
数据驱动。多触点归因模型(马尔科夫链)
现在我们知道了最幼稚的模型,让我们再进一步了解马尔可夫链--在这里,我们根据统计资料,根据每个渠道和事件与最终购买的历史相关性来分配归因。有了这个,我们就有了更多的开口,可以根据你正在使用的特定产品生态系统来定义一个定制的归因规则。
考虑到这一点,我们引入了马尔科夫链的概念。这个模型涉及一个渠道链,每个渠道都是一个顶点,用户有一个特定的概率从一个渠道移动到另一个渠道。
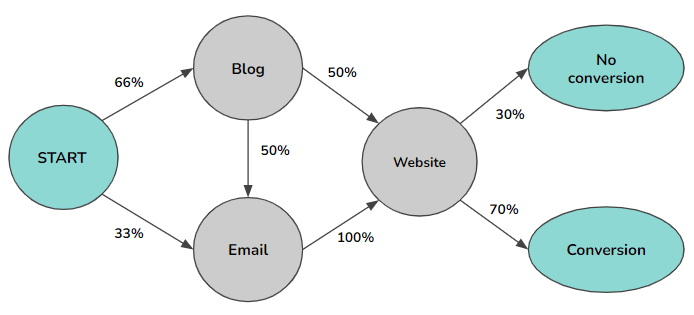
马尔科夫链的顺序定义了我们在未来的观测值之前要看多少个观测值--所以在第二顺序的情况下,我们要检查两个观测值。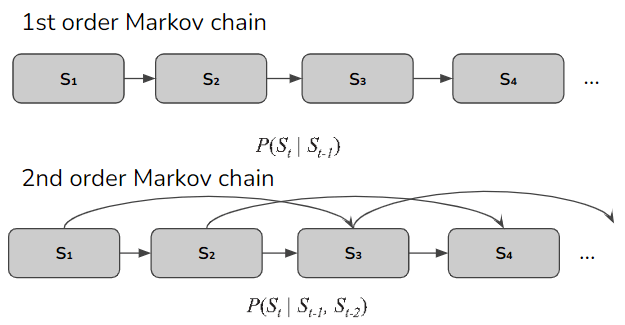
通过深入研究二阶马尔可夫链概率模型的数学概念,借助来自邵旭辉,我们可以根据每个用户事件序列的购买发生次数计算每个渠道的概率: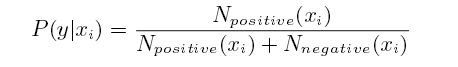
这将带来一个结果,其中每个事件序列都与特定的转化概率相关联——这意味着根据从以前客户那里获得的历史数据,根据该渠道过去的受欢迎程度进行购买的几率。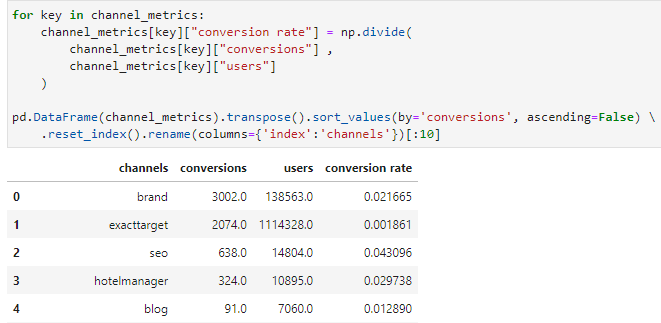
当我们处理用户的路径(他们的事件组合)时,验证每对顺序通道的概率也很重要。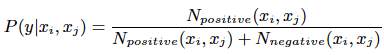
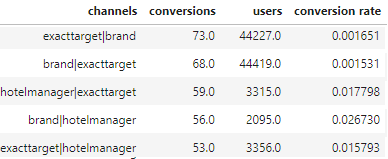
通过提供单个通道和成对通道概率,现在可以使用二阶概率估计来计算组合,以计算此多点触控归因模型的转换指标: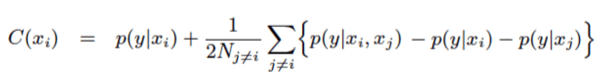
为了简化对上述信道贡献计算公式的理解,可以将其分解为两项。第一项表示单个信道概率。第二项考虑了所有可能对与该特定渠道的贡献——同时还减去每个人的个人贡献,以便它只考虑与两个渠道交互后发生的转换。
用户转化分数:最简单的方法
从上述选项中选择模型后——根据数据驱动方法的马尔可夫链选项的建议——是时候根据他们以前的每条路径的值来定义用户潜力了。主要想法是根据他们与平台的互动来设置分数,以此来定义他们购买公司产品的可能性。
此时,如果你已经将每个路径和渠道的贡献值信息存储在一个单独的表中,就可以跟踪和比较当前用户的路径,并参考这个表,定义用户的得分. 可以根据每个业务案例所需的粒度级别来选择该分数的范围。例如,您可以选择一个介于 0 和 1 之间的分数,也可以看作是用户潜力的百分比,介于 0% 和 100% 之间。
生成的结果还包括对用户路径的描述以及该路径之前在我们的历史数据库中出现过多少次,因此我们可以检查事件的流行度并根据用户对产品的参与度对其进行分类。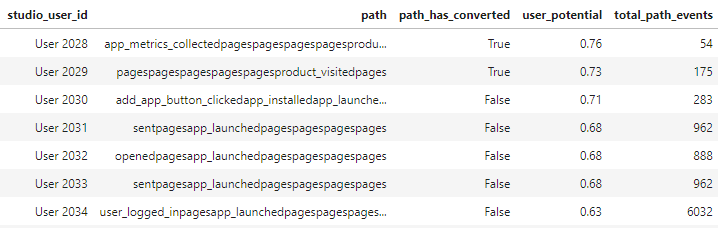
结论
通过该结果,您可以分析客户与平台的互动,并根据营销策略筛选用户,重点关注那些更有可能从您的场所购买新产品的用户。在最后一个营销活动示例中,该营销活动侧重于具有超过 20% 的潜力但尚未购买的用户,我们有 210 名观众可以联系他们,以便更好地了解他们尚未订阅的原因尚未推荐该产品。