什么是RAG?
RAG(Retrieval-Augmented Generation:检索增强生成) 是一个人工智能框架,用于从外部知识库检索事实,以最准确、最新的信息为基础的大语言模型 (LLM),并让用户深入了解 LLM 的生成过程。
大语言模型可能不一致。有时他们会确定问题的答案,有时他们会从训练数据中反省随机事实。如果他们有时听起来像是不知道自己在说什么,那是因为他们不知道。 大模型知道词语在统计上如何关联,但不知道它们的含义。
检索增强生成 (RAG) 是一种人工智能框架,用于通过将模型建立在外部知识源的基础上来补充大模型的内部信息表示,从而提高大模型响应的质量。
在基于 LLM 的问答系统中实施 RAG 有两个主要好处:
- 它确保模型能够访问最新、可靠的事实,并且用户能够访问模型的来源,确保可以检查其声明的准确性和准确性。
- 最终得到信任。
GPT-4-turbo
GPT-4-turbo 较长的上下文窗口有可能克服搜索的局限性。搜索通常根据前 K 个结果的召回率进行评估。较小的 k 值(1 到 5)比较大的 k 值(100 或更多)更难返回相关上下文。
也就是说,你可以输入 100 个或更多对象,而不是只输入 5 个对象,从而提高 LLM 的输出结果。不过,经典的 "迷失在中间 "问题依然存在。
长上下文RAG将是这样一个游戏规则改变者-个人超级兴奋使用多索引搜索!
将所有数据存储在一个集合中并不总是RAG应用程序的最佳选择。多索引 RAG 描述了从多个来源提取上下文的路由查询。这意味着您可以拥有基于不同来源(文档、博文、电子邮件等)的集合,并将其用作 LLM 的上下文。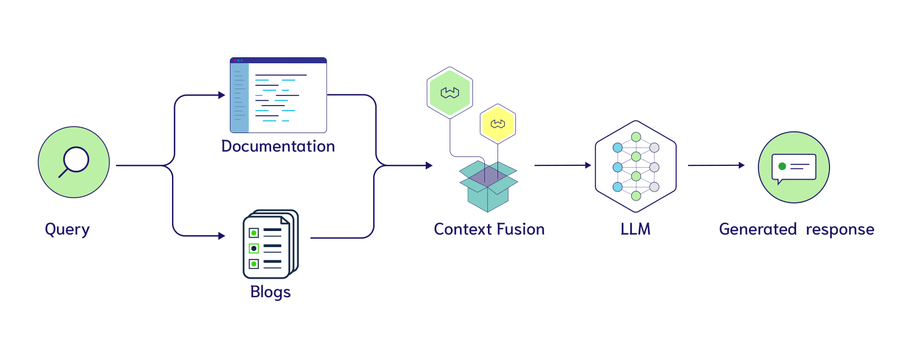
长上下文 RAG + 多索引带来了上下文涌现潜力!
一个简单的模板可以是:
<pre class="displaycode"><code> |
或者,LLM 可以创建一种方法,将多个索引中的相关数据块融合在一起,可能性有很多!