分布式事务教程
解决Kafka消息丢失的一个简单办法

虽然Kafka是一个功能强大的消息系统,但由于网络问题,我们可能会遇到一些不理想的情况。我们也遇到过由于网络问题导致的事件丢失,在试图避免这些丢失的同时,我们也遇到了由于相同原因导致的不同问题。在这篇.
幽默:什么是两段事务机制2PC?
使用 Vert.x 处理 Kafka 和数据库之间的背压

异步编程在开发反应式和响应式应用程序方面带来了许多优点。然而,它也存在缺点和挑战,其中主要的问题之一是背压问题。什么是背压?在物理学中定义是:它是与管道中所需的流体流动相反的阻力或力我们可以把这个问题.
如何解决不同数据库和服务之间的事务问题?

在我这个项目中,有多个数据库和服务需要无缝通信和交换数据。然而,在这些不同的系统中保持交易的完整性已被证明是一个相当大的障碍。我想确保所有相关操作要么成功,要么失败,避免任何不一致或数据差异。我正在使.
微服务分布式事务指南大全
使用Kafka并行消费者提高Apache Kafka性能
与其他现代大数据平台一样,Kafka 通过将数据分区到集群中的多个节点来实现无限的水平可扩展性。对于 Kafka,这意味着每个主题都有 1 个或多个分区。主题拥有的分区越多,并发性就越高,因此潜在的吞.
Temporal让Saga模式变得简单

如果你想知道Saga模式是否适合你的场景,问问你自己:你的逻辑是否涉及多个步骤,其中一些步骤跨越机器、服务、分片或数据库,对于这些步骤,部分执行是不可取的?事实证明,这正是sagas的用武之地。也许你.
使用 db-scheduler 和 Spring 的事务性分阶段作业

在 web 应用程序中,除了更新数据库之外,请求处理通常具有次要效果,例如更新另一个数据源或发送电子邮件。但是很难可靠地控制二次效应发生的时间和条件。在这篇博文中,我将向您展示如何使用db-sched.
现代分布式事务的两种形式 - a16z

长期以来,事务数据库一直是应用程序设计中最关键的组成部分。为什么?因为稳定的数据库通常是混乱的分布式世界中正确性的最终实施点。没有他们,我们就会多付钱和少收钱。我们会失去试图从机场回家的乘客,我们会丢.
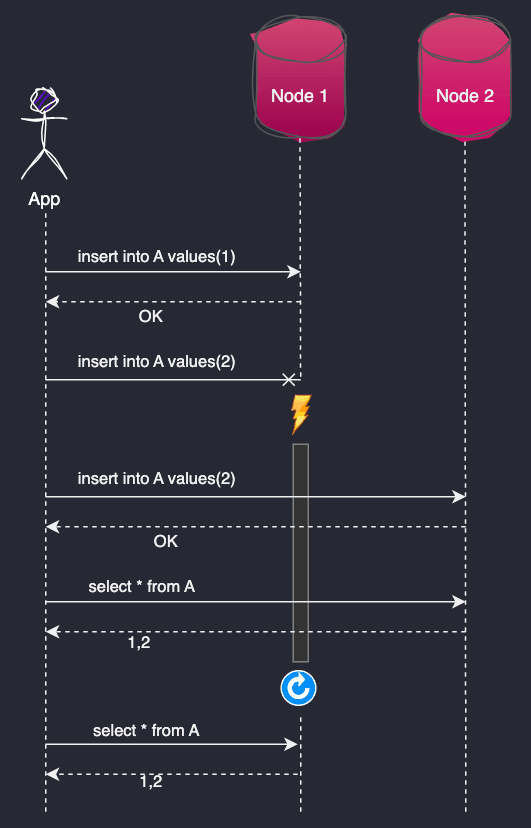
分布式数据库的内部工作原理
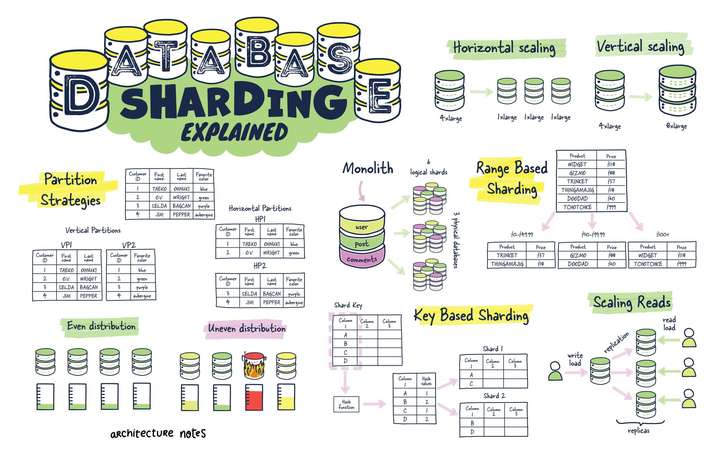
数据库分片解释
数据工程中的三种数据创建方式比较
所有成功的数据驱动组织都有一个共同点;他们有一个高质量和高效的数据创建过程。数据创建通常是数据团队成功与失败之间的区别。数据创建的架构模式在数据创建中,有三种类型的架构模式:事件溯源EventSour.
CDC变更数据捕获实施模式

在本文中,我想讨论实现 CDC 的几种不同方法,以及一些关键应用程序是什么以及 CDC 如何融入现代数据流架构的大局。有几种从数据库中提取变更事件的方法,每一种都有自己的优点和缺点。因此,让我们仔细看.
ActiveMQ 与 Kafka 的比较 | redhat

将 ActiveMQ 与 Kafka 进行比较类似于将关系数据库与 NoSQL 进行比较。ActiveMQ 不像 Kafka 那样适合云。但这并不意味着 ActiveMQ 不再有任何用例。仍然有大量业.
“事务”是任何大规模架构中最糟糕的耦合类型 - techleadjournal
Neal Ford 是 ThoughtWorks 的总监兼软件架构师。在这一集中,我们讨论了关于软件架构的所有内容,涵盖了他最近的三本书:“软件架构基础”、“软件架构:硬部分”和“构建演化架构”。我们.
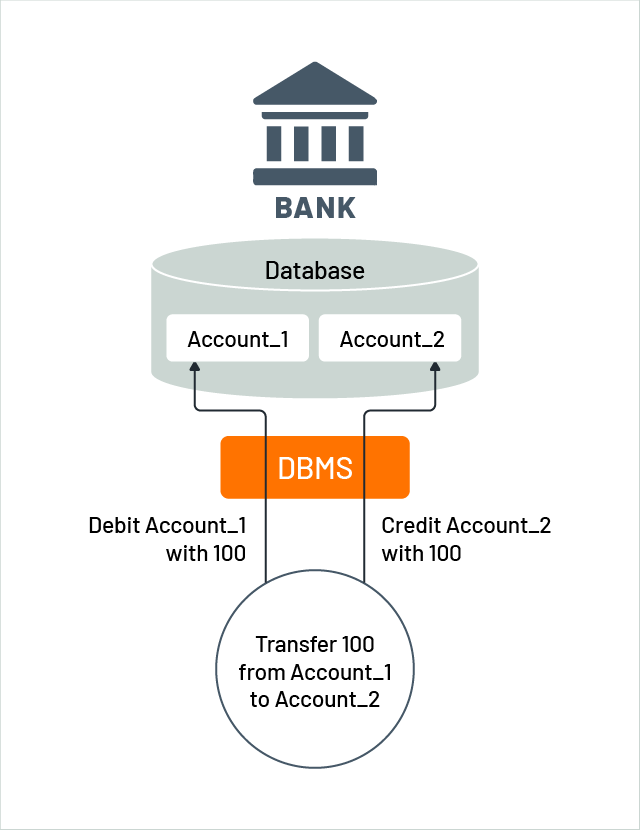
什么是分布式事务?
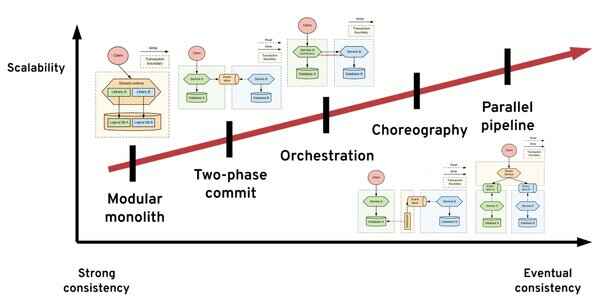
模块化单体比普通单体更复杂 - Oliver
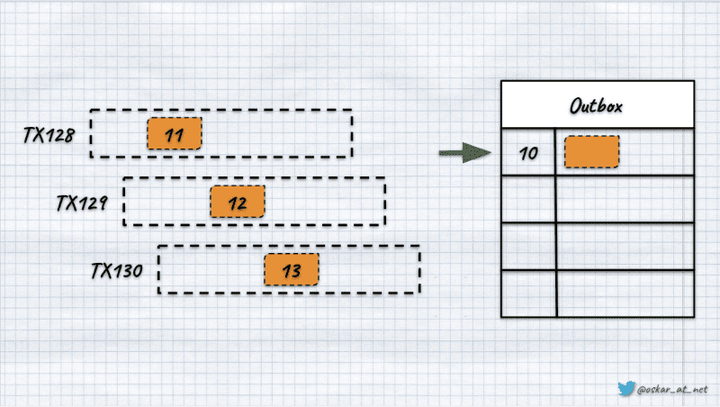
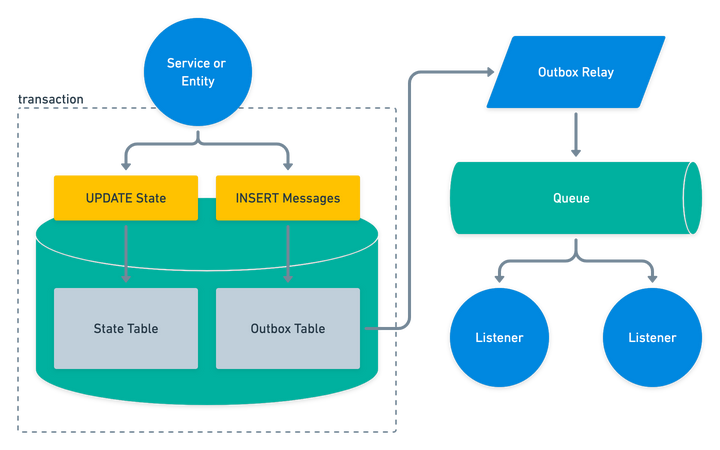
使用事务发件箱进行可靠的事件调度
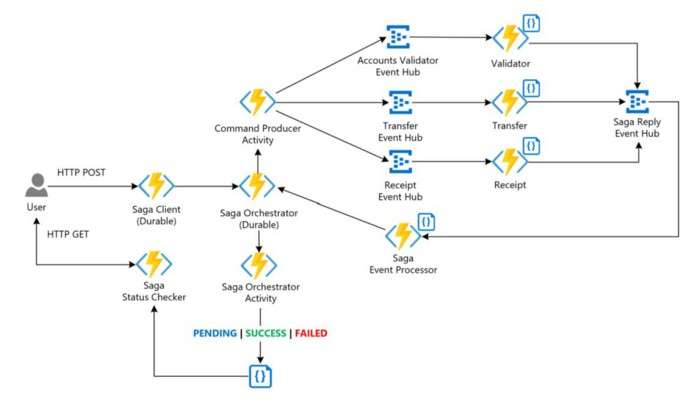
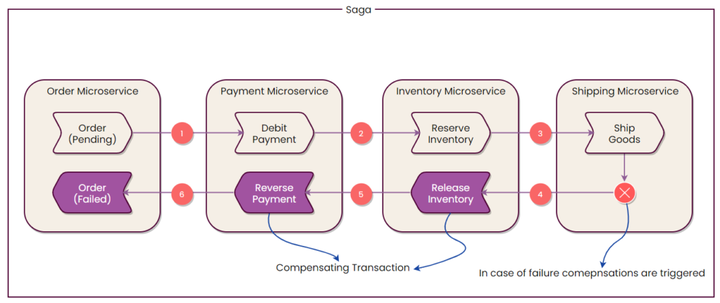
微服务架构中的SAGA模式是什么?
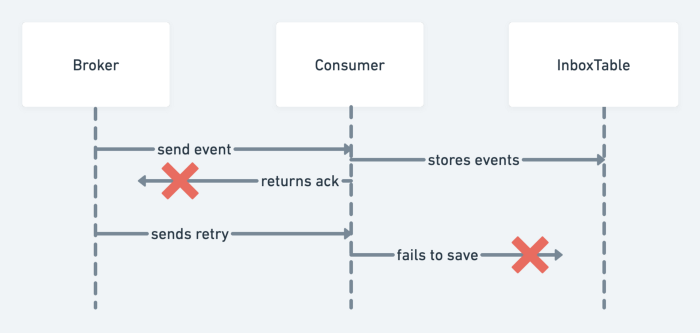
事件模式:使用幂等消费者(收件箱)检测重复消息
使用Flink实现Exactly-Once分布式事务 - Devora

Python中的发件箱模式源码

微服务/模块之间最常用的通信方式之一是通过事件进行异步通信。实施可靠的消息传递有时可能具有挑战性。在今天的文章中,我将向您介绍如何实现发件箱模式以保证事件的传递和可靠的消息传递。发件箱模式(事务性发件.
微服务中的分布式事务:使用 Temporal 实现 Saga
ulid/spec: 全局唯一标识符ULID是传统UUID的替代

ULID 是 UUID 的替代品。它是可排序的并且基于时间戳+随机种子。有多种语言的实现可用。Shopify从UUID切换到ULID,INSERT提升50%,以下是他们经验:分布式系统使用不可靠的网络.
将数据库更改复制到消息队列很棘手 (evanjones.ca)

假设我们有一个将其状态存储在数据库中的程序,我们希望其他程序在发生变化时做一些事情。例如,我们可能想在银行余额下降到某个阈值以下时发送电子邮件通知。这是应用程序使用Kafka等消息队列的一个非常常见的.
适合用于数据库主键的最佳UUID工具库 - Vlad Mihalcea

在本文中,我们将了解哪种 UUID(通用唯一标识符)类型最适合具有主键约束的数据库列。虽然标准的 128 位随机 UUID 是一个非常受欢迎的选择,但您会发现这非常适合数据库主键列。通用唯一标识符 (.
go-coffeeshop: 使用Golang构建的实用事件驱动微服务演示

不要使用UUID,它不安全!

如果您需要一个不可猜测的随机字符串(例如,用于会话 cookie 或访问令牌),可能很想获取一个随机 UUID,如下所示:88cf3e49-e28e-4c0e-b95f-6a68a785a89d这是一.
debezium官方分布式事务Saga案例源码

Postgres 序列问题如何影响您的消息传递保证 ?