K 最近邻 (KNN)、支持向量机 (SVM)、随机森林和神经网络等ML 技术常用于交易应用程序。这些算法可以分析历史价格数据、市场指标、新闻情绪和其他相关因素,以预测未来价格走势并确定最佳进入和退出点。
K 最近邻 (KNN) 是机器学习中用于回归和分类问题的最简单算法之一。KNN 算法使用数据并根据相似性度量(例如距离函数)对新数据点进行分类。
分类是通过对其邻居的多数投票来完成的。数据被分配给具有最近邻居的类。随着最近邻居的数量(k 值)的增加,准确性可能会增加。
什么是 K 最近邻算法?
K-Nearest Neighbors (KNN) 算法是机器学习中一种简单而强大的工具,常用于回归和分类任务。它使用距离函数测量数据点之间的相似性。
在分类过程中,KNN 会将一个新数据点分配到拥有大多数近邻的类别中。通过调整 K 值(即考虑的近邻数量),我们可以影响分类的准确性。
在交易领域,机器学习带来了范式的转变,使交易者能够做出数据驱动的决策,并增强他们的策略。通过利用历史数据和复杂的算法,ML 模型可以识别模式、预测市场走势并优化交易方法。
人工智能在交易中的主要优势之一是能够实时分析海量数据,为交易者提供有价值的见解和机会。
人工智能算法可以处理庞大的数据集,识别隐藏的相关性,并生成准确的股票预测,帮助交易者做出明智的决策,实现利润最大化。
想象一下,有一群经验丰富的交易员指导你做出明智的决策。通过利用预测分析,KNN 算法也能发挥类似的作用。它是一种功能强大的监督机器学习算法,使您能够根据数据点与训练集中近邻数据点的接近程度对数据点进行分类和预测。
利用 KNN,您可以访问虚拟的专家交易员团队,获得有助于做出具有良好预期收益的交易选择的真知灼见。
K 近邻算法是如何工作的?
试想一下,参加交易的都是不同的市场参与者。为了找出最适合特定市场条件的交易策略,您自然会观察顶级算法交易员的行为,并将其与您已经了解的交易员进行比较。
KNN 算法的运行原理与此类似。
第 1 步 - 确定最近的邻居
在 KNN 中,我们使用选定的距离度量(如欧几里得距离或曼哈顿距离)在训练集中找到 "k "个最近的数据点。这些邻近点作为决策影响因素,影响着我们对目标数据点的分类或预测。
步骤 2 - 利用集体智慧
一旦识别出最近的邻居,它们就会根据各自的交易结果投票,为集体智能系统做出贡献。在交易中,成功交易的多数票决定了目标数据点的类别或预测结果。
现在,让我们来探索如何在 Python 中实现 K-Nearest Neighbors (KNN),以创建交易策略。
在交易中使用 KNN 的步骤
首先,让我们看看使用 Python 来使用 KNN 所需的步骤,然后我们将进入编码部分。
此外,如果您是 Python 的新手,在开始学习之前,您必须阅读我们的 Python 免费书籍,以了解基础知识。
因此,大致步骤如下:
- 数据准备 - 收集历史交易数据并进行预处理,确保其符合 KNN 所需的格式。
- 选择最佳 "k "值 - 尝试不同的 "k "值,在交易模型的偏差和方差之间取得适当的平衡。
- 定义距离度量 - 选择一个合适的距离度量,以捕捉交易模式和行为之间的相似性。
- 模型训练 - 将 KNN 模型与训练数据相匹配,使其能够从历史交易模式和结果中学习。
- 进行预测 - 将训练好的模型应用于新的市场数据,根据类似历史数据点的集体智慧预测最可能的交易结果。
在 Python 中逐步实现 KNN
现在,是使用 Python 进行编码的时候了。让我们一步一步来。
步骤 1 - 导入库
我们将首先导入在 Python 中实现 KNN 算法所需的 Python 库。我们将导入用于科学计算的 numpy 库。。
接下来,我们将导入 matplotlib.pyplot 库,用于绘制图形。
我们将导入两个机器学习库:
- 来自 sklearn.neighbors 的 KNeighborsClassifier 来实现 K 近邻投票,以及来自 sklearn.metrics 的
- accuracyscore from sklearn.metrics 用于准确性分类得分。
# Data Manipulation |
第 2 步 - 获取数据
现在,我们将使用 yfinance 获取数据
# Fetch data |
步骤 3 - 确定预测变量
预测变量又称自变量,用于确定目标变量的值。
我们使用 "开-关 "和 "高-低 "作为预测变量。我们将去掉 NaN 值,并将预测变量存储在 "X "中。让我们借助 Python 来定义预测变量。
您可以查看下面的代码:
# Predictor variables |
步骤 4 - 确定目标变量
目标变量又称因变量,是指预测变量要预测的变量值。在这里,目标变量是下一个交易日 SPY 价格收盘时会上涨还是下跌。
其逻辑是,如果明天的收盘价高于今天的收盘价,那么我们将买入 SPY,否则我们将卖出 SPY。
买入信号为 +1,卖出信号为 -1。我们将目标变量存储在变量 "Y "中。
# Target variable |
步骤 5 - 分割数据集
现在,我们将把数据集分成训练数据集和测试数据集。我们将使用 70% 的数据进行训练,其余 30% 用于测试。为此,我们将创建一个分割参数,以 70-30 的比例分割数据帧。
您可以根据需要更改分割比例,但建议至少将 60% 的数据作为训练数据,这样效果会更好。
Xtrain "和 "Ytrain "是训练数据集。Xtest "和 "Ytest "是测试数据集。
# Splitting the dataset |
步骤 6 - 实例化 KNN 模型
将数据集拆分为训练数据集和测试数据集后,我们将实例化 K-最近分类器。这里我们使用的是 "k =15",你可以改变 k 的值并注意结果的变化。
接下来,我们使用 "fit "函数对训练数据进行拟合。然后,我们将使用 "accuracy_score "函数计算训练和测试的准确率。
# Instantiate KNN learning model(k=15) |
Output:
Train_data Accuracy: 0.63
Test_data Accuracy: 0.45
在这里,我们看到测试数据集的准确率为 45%,这意味着我们的预测有 45% 的时间是正确的。
第 7 步 - 利用模型创建交易策略
我们的交易策略就是买入或卖出。我们将使用预测函数预测买入或卖出信号。然后,我们将计算测试期间的 SPY 累计收益。
接下来,我们将根据模型在测试数据集中预测的信号计算累计策略收益。
然后,我们将绘制累计 SPY 回报率和累计策略回报率图,并直观地显示基于 KNN 算法的交易策略的表现。
# Predicted Signal |
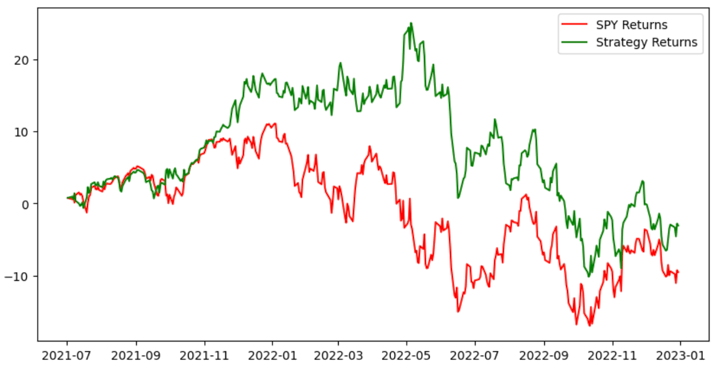
上图显示了两个要素的累计回报:SPY 指数和基于 K-Nearest Neighbors (KNN) 分类器预测信号的交易策略。
简而言之,该图比较了 SPY 指数(绿线表示)和交易策略累积回报(红线表示)的表现。
通过该图,我们可以评估与持有 SPY 股票而不进行主动交易相比,交易策略在产生收益方面的有效性。
步骤 8 - 夏普比率
夏普比率(Sharpe ratio)是指每单位波动所获得的超出市场回报的收益。首先,我们将计算累计收益率的标准差,然后用它来计算夏普比率。
# Calculate Sharpe ratio |
Output:
Sharpe ratio: 1.07
夏普比率为 1.07 表明,投资或战略所产生的收益是所承担的单位风险的 1.07 倍。
夏普比率超过 1 通常被认为是好的。不过,重要的是要将夏普比率与其他投资选择或基准进行比较,以便更清楚地了解其相对表现。
KNN 算法的实现
现在,轮到你来实现 KNN 算法了!
您可以通过以下方式调整代码。
- 在不同的数据集上使用和尝试模型。
- 你可以使用不同的指标创建自己的预测变量,以提高模型的准确性。
- 您可以更改 K 值并对其进行调整。
- 您可以随心所欲地改变交易策略。