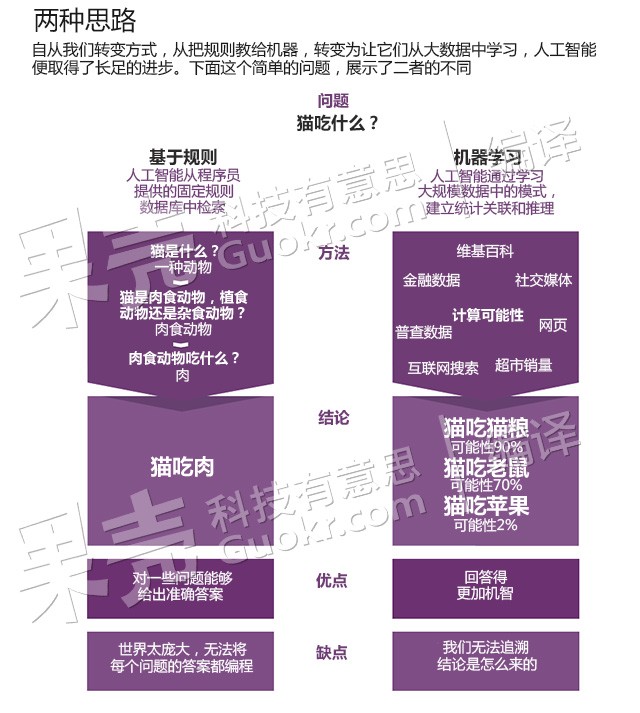
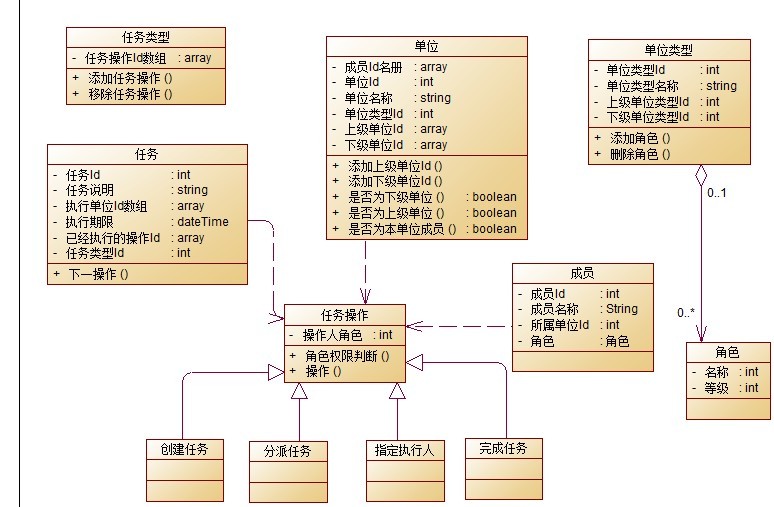
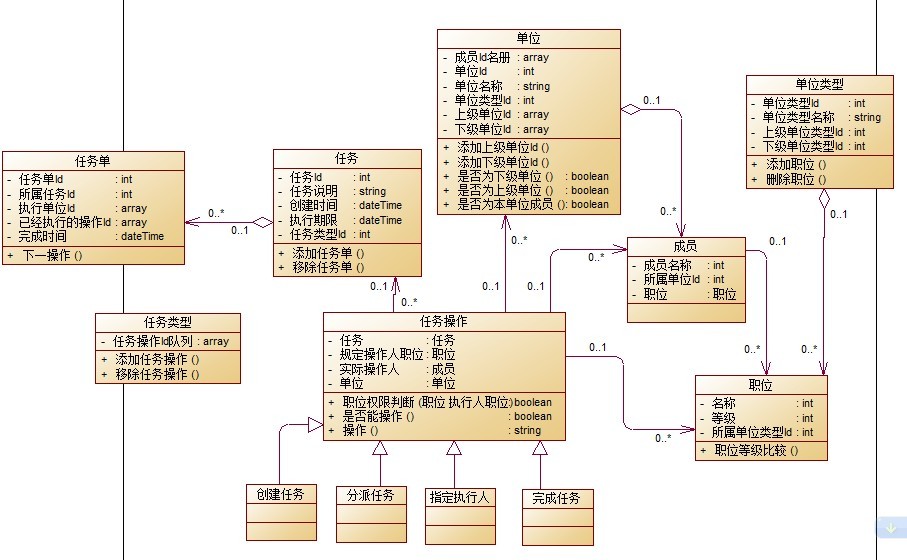
但是,我并不否认面向过程编程方法论,并不否认软件实现最终还是要数据库建模。我只是认同坛子里很多人的观点:将数据库建模的战略地位降低一点,作为对象持久化来看待;将代码编写阶段拖后一些,先看看客户需求,以及应对变化需求的解决方法。
正文:唯一不变的是变化。
需求一:
客户要求做一个任务分派跟踪系统,业务流程大致如下:公司经理可以给部门职员分派任务;任务包括任务说明、要求、完成时间等内容;部门职员收到分派的任务之后限期完成,报公司经理办理情况;系统根据任务限期时间,对于未完成任务的经办人发送提醒;系统对于超期完成的任务执行情况进行记录。
一个具体的例子:部门经理要求所有职员在2013年1月1日之前报一份2012年度工作总结。
数据库建模可能是这个样子:任务表(包涵任务Id、任务要求、任务期限、分派人、执行人、完成时间等字段);任务提醒设置表(包涵Id、任务Id、距离任务限期提醒周期(比如距离任务结束还有1小时、8小时、12小时等)、提醒内容);成员表(包涵Id、成员名、账户、密码、职位(经理和职员))。
由于需求明确、简单,代码部分就是实现以上数据库模型的crud操作,那些简单的业务流程完全可以写入crud操作中,例如判断当前时间是否到了该发送提醒未完成任务的经办人时间。
这样做出的软件效率高,同时满足了需求一,假设这个软件成为软件系统一。