他们把r1放在一个循环中15分钟,它产生了:“在某些情况下比熟练的工程师开发的优化内核更好”
有网友表示:这就是我在过去几周里一直在做cuda / ptx工作的方式,我可以证明R1在这方面特别出色,而且如果你在循环中运行基准测试/编译器,它的表现比你想象的要好得多。
随着人工智能模型的能力越来越强,能够解决更复杂的问题,一种叫做“推理时间缩放”的新技术出现了。这个技术也叫“人工智能推理”或“长期思考”,它的核心思想是在模型推理(也就是模型实际做预测的时候)过程中,多花点计算资源去评估多种可能的结果,然后选出最好的那个。这样一来,AI 就能像人类一样,把复杂问题拆开,一步步解决,最后得出最好的答案。
在这篇文章里,我们聊了一个 NVIDIA 工程师做的实验。他们用了最新的开源模型 DeepSeek-R1,加上推理时额外的计算能力,来解决一个复杂问题。
这个实验的目标是自动生成 GPU 的“注意力内核”(一种专门用来处理 AI 模型中注意力机制的代码),这些内核不仅数值上正确,还能针对不同类型的注意力机制进行优化,而且完全不需要人工写代码。
在某些情况下,这些自动生成的代码甚至比专业工程师手写的优化代码还要好!
为什么需要优化注意力内核?挑战在哪里?
注意力机制是让大型语言模型(LLM)变得强大的关键。它让 AI 模型在做任务时,能够有选择地关注输入中最相关的部分。通过关注重要信息,注意力机制帮助模型做出更好的预测,并发现数据中的隐藏规律。
但是,注意力机制的计算复杂度很高,尤其是当输入序列变长时,计算量会成倍增加。这就逼着我们去开发更高效的底层实现(也就是 GPU 内核),否则简单的实现可能会导致内存不足或者计算效率低下。
注意力机制有很多变种(比如因果注意力、相对位置嵌入、不在场证明等等),工程师通常需要根据任务的不同,组合使用这些变种。
多模态模型(比如视觉转换器)还带来了额外的挑战,因为它们需要专门的注意力机制(比如空间邻域注意力)来处理计算机视觉、视频生成等任务中常见的时空信息。
即使对于经验丰富的软件工程师来说,编写一个针对注意力机制优化的 GPU 内核也需要很多技巧和时间。
最近的一些大型语言模型(比如 DeepSeek-R1)在代码生成任务上表现出了很大的潜力,但它们在第一次尝试生成优化代码时还是会遇到困难。这就需要在推理时使用一些额外的策略来生成优化代码。
下面是一个用户输入的提示示例,要求生成一个支持相对位置嵌入的 GPU 注意力内核:
请写一个 GPU 注意力内核,支持相对位置编码。在核内实时计算相对位置编码。返回完整代码,包括必要的修改。 |
使用以下函数计算相对位置编码:
def relative_positional(score, b, h, q_idx, kv_idx): |
在实现内核时,请注意由于 qk_scale = sm_scale * 1.44269504,相对位置编码需要乘以一个常数缩放因子 1.44269504。
PyTorch 的参考实现不需要缩放相对位置编码,但在 GPU 内核中,请使用:
qk = qk * qk_scale + rel_pos * 1.44269504 |
请提供完整的更新后的内核代码,确保相对位置编码在核内操作中高效应用。
大型语言模型有时会生成一些“幻觉代码”,或者把不同语言或框架的语法混在一起,导致代码出错或者效率低下。计算最佳的 GPU 线程映射也是一项艰巨的任务,通常需要多次迭代才能得到正确且高效的内核。
推理时间扩展用于生成优化的 GPU 内核
为了通过优化的注意力内核获得最佳效果,NVIDIA 工程师创建了一种新的工作流程。这个流程包括一个特殊的验证器和 DeepSeek-R1 模型,在预定时间内以闭环方式进行推理。
- 首先,手动输入提示,DeepSeek-R1 模型生成 GPU 代码(也就是内核)。
- 然后,验证器在 NVIDIA H100 GPU 上运行,分析生成的内核并创建新的提示,作为 DeepSeek-R1 模型的输入。
这种闭环方法通过每次以不同的方式引导代码生成过程,让代码生成变得越来越好。团队发现,让这个过程持续 15 分钟可以显著改善注意力内核。
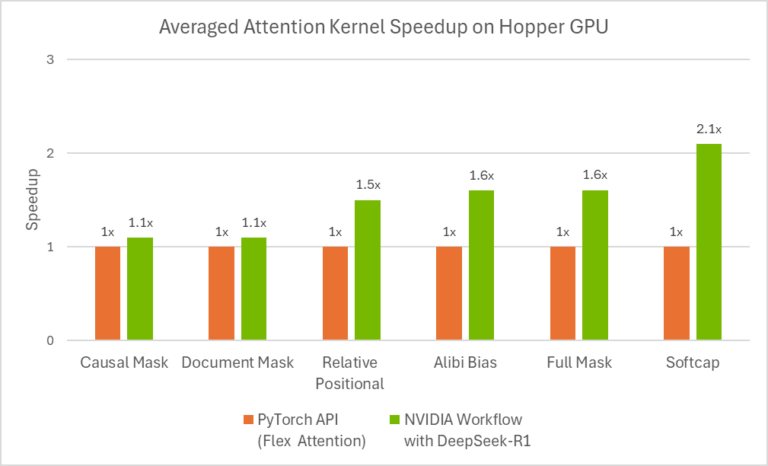
上图 展示了在 Hopper GPU 上,使用两种方法生成的不同类型注意力内核的加速效果对比。橙色表示“PyTorch API(Flex Attention)”,绿色表示“带有 DeepSeek-R1 的 NVIDIA Workflow”。结果显示,带有 DeepSeek-R1 的工作流程在多种注意力内核上都实现了加速,尤其是 Softcap 内核,加速效果达到了 2.1 倍。
经斯坦福的 KernelBench基准测试,这个工作流程为 100% 的 1 级问题和 96% 的 2 级问题生成了数值正确的内核。
推理时间预算如何影响生成正确内核的数量
在 Level-1 类别中,
- 为每个问题分配超过 10 分钟的时间,可以让工作流程为大多数问题生成数值正确的代码。
- 在 20 分钟时,正确率接近 100%。
DeepSeek-R1 上优化的 GPU 内核
这些结果展示了如何使用最新的 DeepSeek-R1 模型,通过在推理期间使用更多计算能力来生成更好的 GPU 内核。
这仍然是一个新的研究领域,但已经取得了一些早期成果。
虽然我们已经有了一个不错的开始,但还需要做更多工作,才能在更广泛的问题上持续生成更好的结果。
我们对 DeepSeek-R1 的最新进展及其潜力感到非常兴奋!